金磊假装发自武汉
量子位 | 公众号 QbitAI
发疯文学的“疯”,终于是让 AI 给呐喊出来了
例如电视剧《180 天重启计划》中的这段发疯名场面:

然后啊,我们让 AI 用于谦+郭德纲的腔调打开这段对话,画风是这样的:

视频地址:https://mp.weixin.qq.com/s/X_8-1s6ZZqkZ9vS69_LeiQ
这要放以前,那些平平淡淡的 AI 语音,这癫感、这呐喊,大概率是发不出来的。
那为什么现在 AI 就可以做到了呢?
因为就在刚刚,火山引擎把豆包语音大模型升级了——
语音学会了思考,更能理解台词,情感表达更有张力。

具体来说,火山引擎这次主要升级了 2 个模型,分别是豆包语音合成模型 2.0(Doubao-Seed-TTS 2.0)和豆包声音复刻模型 2.0(Doubao-Seed-ICL 2.0)。
刚才的那段发疯对话片段的制作过程,就是先上传了郭德纲和于谦的音频,让豆包声音复刻模型 2.0 在短短几秒中的时间里复刻出声音:
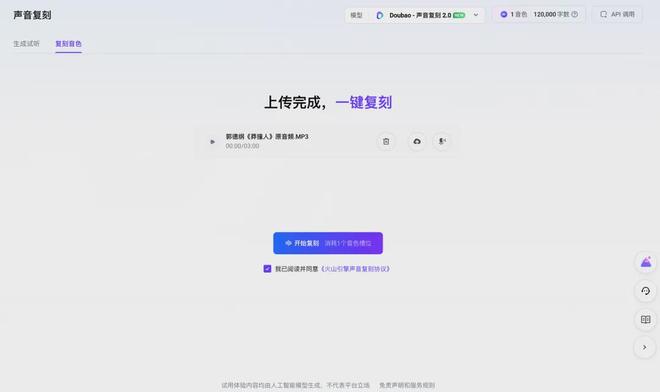
然后再在豆包语音合成模型 2.0 中,分别选择于谦和郭德纲的声音,并在台词的前面标注了一下想要达到的情绪效果:
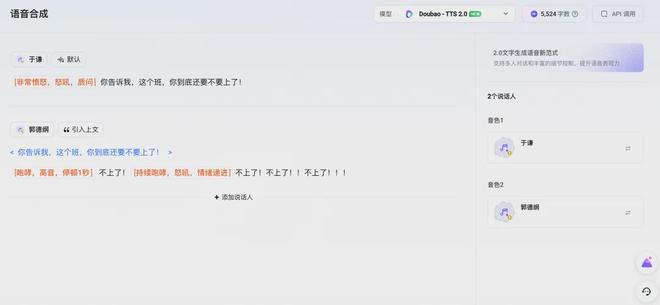
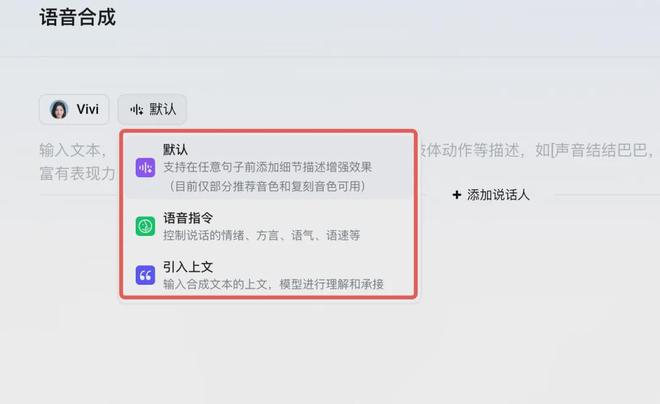
值得注意的是,上面这一步的操作,就是此次豆包语音合成模型 2.0 的一大关键点,分为三种模式:
- 默认模式:可以在台词前像我们刚才那样,添加细节描述内容;
- 语音指令:可以控制说话的情绪、方言、语气和语速等;
- 引入上文:把上文内容引进来,让 AI 更好地去理解完整内容。
所以整体来看,这次火山引擎是想让 AI 语音达到的效果,是要从“像人”走向“懂人”
那么效果到底几何?老规矩,一波实测,走起~
豆包的语音,学会了理解
提到 AI 语音的玩法,怎么能少的了经典名剧《甄嬛传》
有请,华妃甄嬛
然后我们这次要模仿的片段,是闫妮和海清在一次颁奖典礼上的一段有趣对话:
- 海清:大家晚上好,站在我身边的是比我漂亮一点点的闫妮姐。
- 闫妮:站在我身边的是比我难看一点点的美妇海清。
操作方式上,依旧是先用豆包声音复刻模型 2.0 打造出华妃和甄嬛的声音,然后再把魔改的台词注入到豆包语音合成模型 2.0 中。
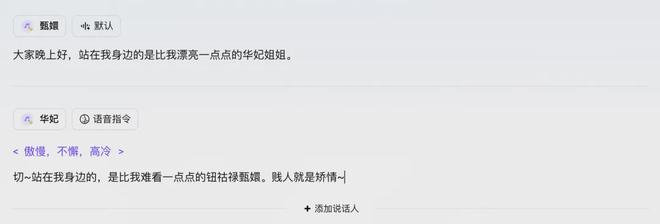
这一次,我们采用的是“默认+语音指令”的方式。
来,听一下效果:

视频地址:https://mp.weixin.qq.com/s/X_8-1s6ZZqkZ9vS69_LeiQ
啧啧啧,听完这个片段,华妃的大白眼儿都在脑海里翻上天了……
接下来,我们再用歌坛当红炸子鸡单依纯的声音来对比一下有无“语音指令”的区别。
台词是:我逆转时空九十九次救你,你却次次死于同一支暗箭。谢珩,原来不是天要亡你……是你宁死也不肯为我活下去。
在没有“语音指令”的时候,单依纯的声音念这段台词可以说是平平淡淡、寡然无味:

音频地址:https://mp.weixin.qq.com/s/X_8-1s6ZZqkZ9vS69_LeiQ
但当我们加上这么一句指令,“小品女王”单依纯的情绪一下子就上来了:

音频地址:https://mp.weixin.qq.com/s/X_8-1s6ZZqkZ9vS69_LeiQ
不过有一说一,单依纯的声线……还是适合用来唱歌。
至于有无“上下文引用”,AI 语音生成的效果差距也是比较的。
例如给定一段台词:
- 北京…因为我来,这是第二次,上一次是在一…八年还是什么时候来过一次但是时间很短也没有时间去,真正的去游历,所以北京对我来说…只是…还存在一种想象之中啊,嗯没有太多的,直观的体验。
可以看到,这段台词有大量的停顿之处,这就需要 AI 精准地去识别和思考。在没有“上下文引用”的时候,效果是这样的:

音频地址:https://mp.weixin.qq.com/s/X_8-1s6ZZqkZ9vS69_LeiQ
停顿可以说是杂乱无章了。但若是家里一句[#你怎么评价北京这个城市?],效果就会截然不同:

音频地址:https://mp.weixin.qq.com/s/X_8-1s6ZZqkZ9vS69_LeiQ
至于火山引擎这次是如何让 AI 语音能力提升的,背后的关键就是我们刚才提到的基于豆包大语言模型研发语音合成新架构
它可以让合成和复刻的声音都能进行深度语义理解,并拓展出上下文推理能力,从单纯的文本朗读进化为 “理解后的精准情感表达”
这意味着模型可以捕捉到对话的背景信息、用户的潜在意图甚至是细腻的心理活动,从而在声音中注入真实的情感和拟人感。
基于这种深度的语义理解,模型不仅能实现更连贯、饱满的情感演绎,还能精确遵循用户的指令,灵活调控语气、情绪和语速。
这也就不难理解升级的豆包语音模型能让 AI 说话这么有味道了。
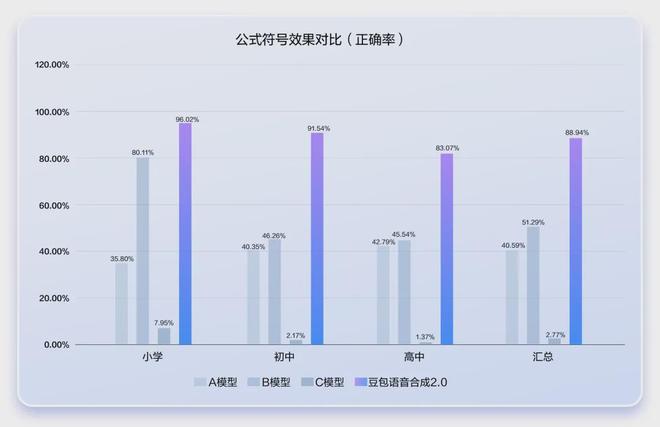
不过基于此,火山引擎还解决了一个业界老大难的问题——让 AI 精准地念出复杂公式

在现场,团队就放出了用咱们很熟悉的声音念出来的铜与浓硫酸反应

视频地址:https://mp.weixin.qq.com/s/X_8-1s6ZZqkZ9vS69_LeiQ
据了解,目前市面上的同类模型朗读准确率普遍低于 50%,但豆包语音大模型 2.0 版本,在小学至高中阶段全学科的复杂公式朗读中,能够实现 90% 左右的准确率!
New 的不仅仅是语音
除了语音上的大动作之外,火山引擎这次在基座模型和多模态方面,同样也有不少的动作。
首先,作为技术底座的豆包大模型 1.6迎来了重要升级。
此次升级最大的亮点是,它成为了国内首个原生支持分档调节思考长度的 Thinking 模型。
在实际应用中,深度思考模型常因推理时间过长而导致响应延迟和成本高昂,这成为许多企业望而却步的门槛。

豆包大模型 1.6 通过训练四种不同的思考模式,让客户可以在效果、时延、成本三者之间找到最适合自身业务的平衡点。
例如,在低思考长度模型下,模型效果与升级前保持不变,但总输出 tokens 下降了 77.5%,深度思考时间更是大幅缩短了 84.6%。

与此同时,火山引擎还首次推出了轻量化的豆包大模型 1.6 Lite,为不同应用场景提供了更灵活、高效的选择。

更进一步,火山引擎在国内首次发布了智能模型路由(Smart Model Router)。

“没有一款模型是万能的”,这是业界的共识。智能模型路由的核心价值在于,它能像一个智能调度中心,根据用户任务的复杂度和类型,自动匹配最合适的模型来执行。
用户可以在“效果优先”、“成本优先”和“平衡模式”之间自由切换,系统会自动选取豆包系列或其他业界主流模型(如 DeepSeek、Kimi 等)中最优的一个来完成任务。
这有效避免了“大材小用”造成的成本浪费或是“小材大用”导致的效果不佳。测试数据显示,在成本优先模式下,路由后的综合成本最高可下降 71%,极大地降低了企业使用大模型的门槛。
中国公有云上,每两个 token 就有一个由火山引擎生产
从豆包图像创作模型 Seedream 4.0 到豆包语音模型 2.0,迈向 AI 云,这是今年火山引擎的迭代速度。
因此在最后,我们还需要讨论一个问题——这一系列密集的产品发布,意味着什么?
答案其实清晰地藏在火山引擎眼中全球大模型技术演进的三大核心趋势:
更强的思考与理解能力更丰富的多模态交互以及更实用的 Agent 智能体

从能分档调节思考长度的豆包大模型 1.6,到能理解上下文的对话式语音模型,再到精准调度模型的智能路由,无一不体现了火山引擎对模型“思考与理解”能力的深度探索。
而豆包语音、图像、视频等一系列多模态模型的持续迭代和生产级应用,则是在多模态趋势上的坚实布局。
这些技术创新并非停留在实验室的理论,而是已经深入到了真实的商业场景中,并创造着实际价值。
例如,小米的智能助手小爱同学在接入豆包大模型 1.6 后,让手机、智能眼镜等终端设备同时拥有了智慧的大脑和眼睛,能够结合看到的现实场景进行对话和处理信息。
国内领先的汽车平台懂车帝,利用“AI 选车”功能,让复杂、模糊的购车需求得到高质量的回应,复杂需求搜索占比从过去的 10% 大幅提升至 79.4%。
此外,包括 OPPO、Keep、美图、洋葱学园在内的众多企业也已经开始应用火山引擎的语音技术,在对话助手、情感陪伴、内容配音、教育等领域提升用户体验。
这一切技术能力的实现与规模化落地,都离不开背后庞大算力和高质量数据的支撑。
一个惊人的数字是,豆包大模型的日均 tokens 调用量,在一年多时间里从 1200 亿增长至超过 30 万亿,实现了 253 倍的增长。
根据 IDC 数据,中国公有云上每两个 token 就有一个由火山引擎生产。
这背后正是火山引擎 AI 云所提供的稳定、高效的基础设施,它为模型的训练和推理提供了关键动力,成为推动 AI 技术从理论走向应用的坚实底座。
最后,豆包语音合成模型 2.0 和豆包声音复刻模型 2.0 现在都已经可以体验了,感兴趣的小伙伴可以去试试喽~
体验地址:
https://console.volcengine.com/speech/new/experience/clone?projectName=default






