
新智元报道
编辑:元宇好困
Sakana AI 以自然演化为灵感,提出了一种全新的模型融合进化方法 M2N2。通过引入自然界的「择偶机制」,AI 可以像生物一样「竞争、择偶、繁衍」。在当前全球算力短缺、模型训练实际规模受制的情况下,Sakana AI 借助自然界的启示,为模型融合探索出了一条新路。
如果让 AI 模型像生物一样演化,它们会不会彼此竞争、协作、结合,并繁衍出越来越强的后代?
「物竞天择,适者生存」的进化论思想,是否也适用于 AI 模型?
就在最近,Sakana AI 从自然演化的过程中汲取灵感,提出了一种利用「竞争与吸引力」的自然选择机制,来提升 AI 模型融合效果的方法。

Sakana AI 认为,AI 模型的发展,也和自然演化的过程类似:集体智慧从群体中涌现。
比如:自然并没有创造单一的、巨大的单体生物,而是孕育了一个多样化的生态系统。在自然界的生态系统中,每一个个体通过竞争、合作与组合来适应环境、繁衍后代。
这正是 Sakana 眼中的 AI 世界该有的样子:
当人类不再试图构建一个庞大的单体 AI,而是演化出整个 AI 生态系统,各个专业 AI 模型在其中竞争、合作、融合……这会带来什么?
他们没有简单停留在想象阶段,而是一直在探索模型融合,试图利用演化,来破解现有模型融合的「最佳配方」。
现在,他们把这个「最佳配方」公开了!
目前,相关研究已在 GECCO 2025 会议上发表,并荣获最佳论文提名奖!

论文地址:https://arxiv.org/abs/2508.16204
GitHub:https://github.com/SakanaAI/natural_niches
以往的模型融合,需要人工介入,手动定义模型的分割方式(例如,按固定的层或块)。
能不能让这个过程,也像自然界的演化那样,自动运行?
Sakana AI 提出了 M2N2(Model Merging of Natural Niches,自然生态位的模型融合),攻克了上述难题。
该方法来自于自然演化的三个关键思想:
-
演化融合边界:M2N2 让模型的组合更为自由,打破了预定义的静态边界,大大拓宽了模型组合的探索空间和可能性。如同自然界交换可变长度的 DNA 片段,而非整个染色体。
-
多样性竞争:M2N2 模仿了自然界的「丛林法则」,让模型们为了有限的资源(即训练集中的数据点)展开竞争,迫使模型走向专业化,寻找自己的「生态位」,从而创造出一个由多样化、高性能专家组成的种群,为优质模型的「繁衍」提供更多优秀的种子模型。
-
择偶机制:M2N2 引入了一种「吸引力」启发式方法,它会根据模型的互补优势,智能地进行配对融合——即选择在对方弱项上表现出色的伙伴,这使得演化搜索的效率大幅提升,也大大降低了模型融合的计算成本。
这一尝试的结果,也令人振奋:M2N2 模型融合技术,开始在模型演化中被成功应用,表现也优于其他演化算法。比如:
-
从随机网络演化出的 MNIST 分类器,性能媲美 CMA-ES 算法,但计算效率更高。
-
能够扩展到大型预训练模型,尤其是在数学和网络购物任务上,生成的融合模型表现显著优于其他方法。
-
在模型融合过程中,还避免了模型微调中「灾难性遗忘」的问题。
这让网友 Aragon Dev 感叹:「2025 年,智能体真比自己先找到对象」

M2N2:全新的模型进化方法
M2N2 通过引入一种结合竞争、吸引力与带切分点的模型融合的全新进化方法,显著提升了模型融合的效果。
它首次将模型融合用于从零开始训练,并在性能与计算效率上优于所有当前的进化算法。
研究人员在将 M2N2 扩展至 LLM 与基于扩散的图像生成模型后,表现出了诸多优势。比如,它可以
-
稳定融合且避免灾难性遗忘
-
兼容不同目标训练的模型
-
通过避免梯度计算降低内存占用
-
在无需原始训练数据的情况下保留模型能力

在模型融合中,目标是在个初始模型中找到融合模型的最优参数∗,使得通常以任务分数的和/平均表示的优化目标最大化。
在 M2N2 中,研究人员对融合函数ℎ做出修改,使融合边界可进化。同时对优化目标,做出调整以促进多样解。
M2N2 消除了固定的模型融合边界。
为摆脱固定融合边界的约束,研究人员通过探索更广泛的边界与系数,逐步扩展搜索空间,这一渐进引入复杂度的做法,既拓宽可能性,又保持计算可控。

对有限资源的竞争,天然会促进多样性。
研究人员通过修改优化目标来鼓励多样性。通过限制资源供给,M2N2 激发竞争,自然偏好占据新生态位的个体。
他们的具体做法是:
将群体能从某个样本中提取的总适应度限制为容量。
候选解从获得的适应度,正比于其分数相对于群体总分的占比。
修改后的目标为:

在生物学中,这种结合(繁殖)代价高昂,因此动物会在择偶过程中投入大量资源。
M2N2 额外考虑父本之间的互补性,通过逐步引入复杂度,在保持计算可控的同时扩大了可探索范围。

实验1:进化 MNIST 分类器
这项实验所优化的,是一个总计 19,210 个参数的两层前馈神经网络。
从零开始时,研究人员随机初始化模型。
对于预训练模型,研究人员构建了两个专门化模型:一个在数字0–4 上训练,另一个在数字5–9 上训练。
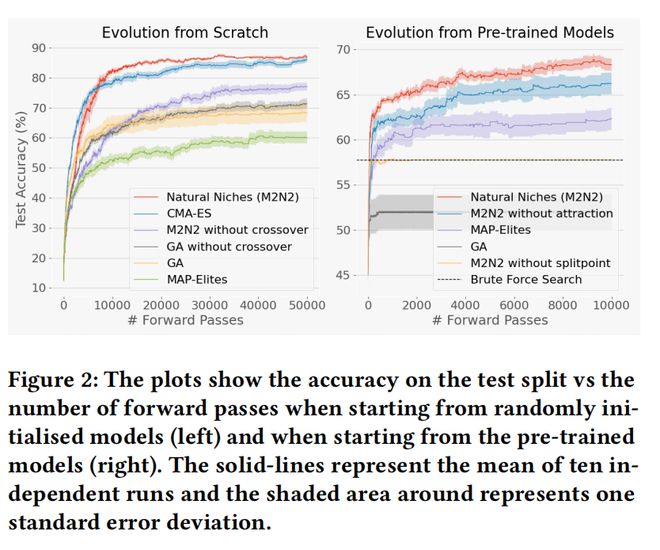
结果表明,在从零开始时,与其它模型融合方法相比,M2N2 在测试准确率上有显著优势(图 2 左)。
对从零开始训练的模型,切分点与吸引力得分影响很小。但如图 2 右所示,当从预训练模型起步时,切分点变得至关重要,而吸引力在整个训练过程中都能显著提升性能。
在多样性方面,图 3 左展示了至少被库中一个模型正确标注的训练样本占比——训练覆盖率。

图 3 右侧,展示了群体性能多样性随训练的演化:
若所有模型对同一样本均对/均错,则熵为0(无多样性); 若模型在预测上均匀分裂,熵达最大1。
从图 3 中,可以看出 M2N2 的模型库,很快覆盖了绝大多数训练样本,并在整个训练过程中保持高覆盖。
图 3 还展示了所有样本的平均熵:M2N2 在初期熵快速上升,随后随着低性能模型的灭绝而逐渐下降。
对比之下,MAP-Elites 通过保留低性能模型持续提高多样性,但未能实现高覆盖。
总体来看:M2N2 维持了一个优势互补的模型库,既促进有效融合,又会在训练推进时系统性地淘汰弱模型。

如图 4 显示,较小的库在起步更好,但更快收敛到较差解。
这表明应按计划的前向次数来扩展库大小。
值得注意的是,上图中库增大并不增加计算成本(前向次数不变),但会增加内存占用。对超大模型,可以将模型库存盘,而非常驻内存。
实验2:LLM 数学专家与智能体融合
实验中,研究人员将数学专家 WizardMath-7B-V1.0,与智能体环境专家 AgentEvol-7B 融合,目标是在数学基准 GSM8k 与网页购物基准 WebShop 上表现良好。

实验结果表明,表 1 显示 M2N2 得分最高。吸引力与切分点两项技术都至关重要,其中切分点技术更重要一些。
当融合数学与智能体技能时,CMA-ES 得分较低,可能由于参数划分不佳,这强调了在优化过程中纳入融合边界的必要性。

如图 5 所示,MNIST 的发现,还可推广到 LLM 融合。
如左图,自然生态位方法保持了高训练覆盖率;在模型探索不同生态位的早期,熵上升(右图);随着低性能模型被移除、优势被聚合,熵逐步下降。
相比之下,MAP-Elites 侧重最大化熵,但因为它保留了低性能模型,将牺牲训练效率与覆盖;GA 则迅速降低覆盖与熵,并「贪心」地收敛到其最优解,最终使整个库「塌缩」为单一解,熵接近零。
实验3:融合基于扩散的图像生成模型
在该实验中,研究人员评估了 M2N2 在融合多样文本到图像模型中的表现。
初始模型包括针对日文提示训练的 JSDXL,以及主要由英文提示训练的三个模型:SDXL1.0、SDXL-DPO 与 Juggernaut-XL-v9。
这些模型共享的基础模型是 SDXL 1.0 的架构。
模型融合的主要目标,是在保留 JSDXL 理解日文提示能力的同时,整合各初始模型在图像生成方面的最佳能力。

表 2 展示了各模型在测试集上的表现,可以看出 M2N2 在测试集上的 NCS 分数优于所有其他模型。

图 6 展示了 M2N2 的融合模型,如何成功结合各初始模型的优势并缓解其弱点,展示了其在追求性能多样性与质量聚合方面的成功。
若不考虑融合模型,可以观察到每个初始模型在不同测试用例上,均可能产出最高与最低质量的结果。
此外,很难找到一个清晰模式,来描述每个模型的专长,或指导如何构造有效的自定义多样性度量。
M2N2 的多样性保持机制,通过自动保留那些在其他模型表现不佳的样本上独特出众的模型,解决了这一难题。
M2N2 融合模型,相对于初始模型有两点关键改进:
-
生成更逼真的照片,与我们使用真实照片的训练集更一致;
-
对输入标题的语义理解更强。
如图 6 中最右列展示,虽然若干初始模型生成了好看的自行车,但 M2N2 的融合模型不仅准确聚焦于标题中指明的「车牌号显示区域」,还生成了更像真实照片而非合成渲染的图像。

M2N2 在语言理解能力上,也同样出色。
图 7 显示,M2N2 融合模型对日语与英语都有良好理解。
这种涌现的双语能力体现了 M2N2 的一项关键优势:
它能够聚合互补能力,同时避免基于梯度训练常见的灾难性遗忘。

表 3 显示了 M2N2 融合模型显著优于其他模型,这在统计上印证了研究人员在定性结果中的观察。
模型融合的可行性高度依赖模型间的相似程度,但也存在一定限制:当微调模型与其基座模型显著偏离(通常由于大量、分歧的训练)时,融合会变得不可行。
表 3 中列出了基于 100 对样本,日文提示与其英文翻译生成图像的 CLIP 特征余弦相似度均值(±标准误),数值越高表明跨语言一致性越好。 研究人员假设状态表示分歧较大的模型不适合融合。然而,尚无标准的模型兼容性度量。
若能定义此类度量,便可在预处理(如微调)中作为正则化使用,从而更好地控制兼容性并提升融合成功率。
研究人员认为,共同演化的模型会受到「保持可融合兼容性」的强烈进化压力。若某个模型偏离并与其他模型不兼容,将无法产生「可存活的后代」,致其改进停滞并最终灭绝。
验证这一假设,将有助于理解模型共演化的动力学。此外,将兼容性度量纳入吸引力启发式,可能促进不同「物种」模型的共演化(定义为彼此可融合、但与其他组不可融合的模型群体)。
作者简介
Yujin Tang

Yujin Tang 是 Sakana AI 的主任研究科学家,研究方向包括强化学习、机器人学、进化算法和生成模型等。
他在东京大学获得计算机科学博士学位,在早稻田大学获得硕士学位,并在上海交通大学获得学士学位。

在加入 Sakana AI 之前,他曾是 Google DeepMind 和 Google Brain 的高级研究科学家。

参考资料:






