
文|阿尔法工场
经历了 DeepSeek 等爆款从横空出世到增长乏力后,大模型投资人变得谨慎,宁可押注前两名。腰部以下玩家的生存空间,持续被压缩。
01 “不是那个节点”
北京时间 8 月 8 日凌晨,OpenAI 发布 GPT-5。这一代产品将大语言模型与推理模型整合,能智能调度多种子模型,在解决不同任务时调用最优引擎。相比 GPT-4o 的事实错误率也大幅降低。
虽然部分业内人士评价其缺乏颠覆性,但在事实准确率、多轮推理、复杂任务执行上的提升,依然让它暂时保持在全球头部的位置。

图源:OpenAI 官网
就在上个月,国内 AI 大模型“六小龙”之一月之暗面发布并开源了万亿参数大模型 Kimi K2。
上线 48 小时,月之暗面官网访问量达 36 亿次,Hugging Face 下载量突破 10 万——这种声势,甚至在国内外科技媒体的版面上压过其它大模型。

图源:Kimi 官网
然而,不到一月,热度如潮水消退。
Kimi 的 K2,没能复制 DeepSeek 今年 1 月的轨迹。抢跑换来的是短暂曝光,而非扭转“下坡”的蹒跚。
第三方监测机构 aicpb.com 数据显示,今年 7 月,Kimi APP 月活跃用户(MAU)仅居全球第 19 位,落后于豆包、DeepSeek、腾讯元宝等国内对手,下载量更跌出前 20。
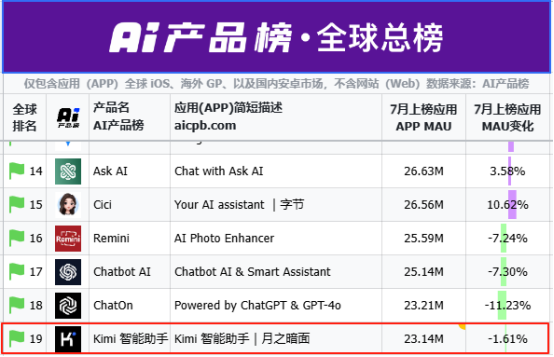
图源:AI 产品榜
QuestMobile 数据显示,5 月 Kimi 的月活用户 1408 万,在国内原生 AI 应用中排名第九;而在去年 12 月,这个数字曾高达 2101 万,位列前三。
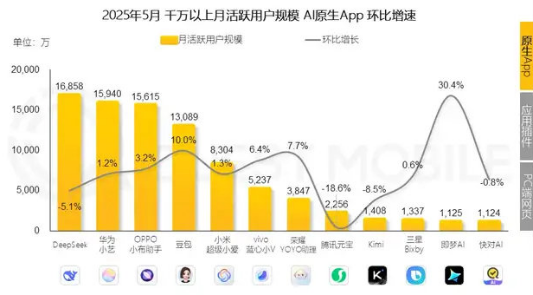
图源:QuestMobile
“大家都在等一个能扭转局势的产品时刻,就像 DeepSeek R1 那样。但 Kimi 的 K2,并不是那个节点。”一位 AI 大模型研究者告诉笔者。
02 重金投流
为何与 DeepSeek 被业内并称“绝代双骄”的 Kimi,退步如此之快?
有业内人士认为,Kimi 之前“走红”,更多是营销的胜利。
2023 年 10 月,Kimi 以 20 万字长文本处理能力横空出世,几个月后将上限提升至 200 万字,对话框容量一度全球领先。
彼时,长文本处理被视为 AI 处理深度任务的门槛:写一份学术综述、法律分析或行业研报,用户不再需要拆分文本、反复输入。
可真正让 Kimi 实现用户数量大幅增长并迅速出圈的,并非其技术优势,而是声势浩大的“重金投流”。
业内广为流传,2024 年春节,月之暗面在B站(9626.HK/BILI.NASDAQ)投放广告总额超亿元,单用户获客成本(CPA)为 30 元。
彼时,在B站首页或视频推荐区,总能看到“Kimi AI 智能助手”推广链接。
Kimi 在B站的广告投放,图源:哔哩哔哩
这一引流策略,短期内制造了“现象级”关注度和下载量,也引发了同行“赛级”模仿。
当时正是 AI 大模型“群雄逐鹿”的相对空白期。各大厂模型加速迭代,DeepSeek 还在韬光养晦。因此,谁受到的关注多,就看谁的曝光率高。
高成本投放的代价,是压缩研发与算力预算。
Kimi 把长文本处理优势作为核心卖点,但技术壁垒却不高。
上下文扩充达到一定限度,对模型整体能力的提升有限。一旦超越这个阈值,大模型比拼的将是实打实对文本推理能力以及高质量解答能力。
根据 QuestMobile 对国内各大模型测试显示,Kimi1.5 模型在长文上输出速度,已远低于通义、豆包、腾讯元宝和文心一言。

国内各大模型在长文本的性能测试,图源:QuestMobile
Kimi 的长文本独占优势被抹平的同时,专业垂直工具开始“降维打击”。
Wind(万得)、知网等在各自领域的应用,把长文本处理与特定知识库绑定,直接生成研报、综述、财报摘要。这种垂直场景 AI,不仅精度更高,还能保证数据来源可追溯,让通用型长文本 AI 的吸引力显著下降。
图源:知网官网
行业变化极快。
到 2024 年中,“百万 tokens”已是主流厂商标配,模型竞争焦点转向推理能力、交互体验与多模态。
豆包 1.6 可以处理文本、图像、音视频全链路,通义千问支持语音+图像输入。
而 Kimi 的多模态仍局限在图片与代码理解,输出主要是文字与代码,缺少语音、视频等交互能力。
这种差距,已很难再通过投流进行弥补。
03 “三重制约”
如果说产品与市场节奏决定了 Kimi 眼前的失速,那么数据、算力、资本三大要素的短板,则限制了它的长期竞争力。
数据不足,是 Kimi 难以突破的核心原因之一。
国内多家大厂模型能利用自家生态(如阿里的淘宝、字节的抖音与今日头条、腾讯的微信)作为中文语料来源,形成持续的模型优化闭环。
受限于生态屏障,Kimi 缺乏这样的数据入口,更多依赖公开网络数据与合作伙伴提供的有限语料。
算力上的短板,则更为直接。显著拖慢了中国 AI 大模型的追赶步伐。近期国外大模型的表现,明显超过国内就说明这一点。
此外,背靠阿里云、百度(9888.HKB/IDU.NASDAQ)智能云、火山引擎的大厂模型,可以用自有云资源训练和部署模型,而 Kimi 需要采购云服务,成本更高。
国内外各大模型厂商均靠持续融资烧钱输血来维持发展,钱主要就花在了购买算力硬件上。
资本收紧,则是今年 Kimi 的新增压力。
2023 年至 2024 年,月之暗面获得阿里等数家大厂青睐,估值一度升至 33 亿美元。
但去年 8 月后,公司再无新融资。去年底,投资人朱啸虎与创始团队的股权纷争与仲裁风波,以及近段时间 Kimi 用户侧数据明显下降,或让潜在投资人态度转为观望。
没有新资金,投流规模与模型迭代速度都会被迫放缓,形成“融资受阻—创新放缓—用户流失”的恶性循环。
根据“爱分析”调研统计,2024 年 AI 大模型项目,累计项目金额超过 400 亿人民币。其中,科大讯飞(002230.SZ)、百度、阿里、腾讯等大厂均获得亿元级订单。而月之暗面尚无公开的标杆性大单。

图源:爱分析
业内人士反馈,经历了 DeepSeek 等爆款从横空出世到增长乏力后,AI 大模型投资人变得谨慎,宁可集中押注头部“前两名”。中腰部以下玩家的生存空间,持续被压缩。
在互联网商业史上,从不缺一鸣惊人的公司,但缺的是能把“一鸣”延续成长期鸣响的能力。






