
新智元报道
编辑:LRST
GraphNarrator 是 Emory 大学研究团队开发的首个为图神经网络生成自然语言解释的工具。通过构造和优化解释伪标签,再将这些标签蒸馏到一个端到端模型中,使模型能直接输出高质量的自然语言解释,让复杂的图神经网络决策过程变得透明可理解,且在多个真实数据集上验证了其有效性。
图神经网络(GNN)已成为处理结构化数据的核心工具,广泛应用于社交网络、药物设计、金融风控等场景。
然而,现有 GNN 的决策过程高度复杂,且常常缺乏透明度:为什么模型做出这样的预测?关键依据在哪?这成为阻碍其大规模落地的重要瓶颈。
已有方法多基于「重要子图提取」或「节点-边归因」,如 GNNExplainer、PGExplainer 等,但它们只能输出结构片段,不具备人类可读性,且缺乏对文本属性节点的处理能力(如文献图、商品图)。
Emory 大学的研究团队提出了首个面向图神经网络的自然语言解释生成器 GraphNarrator,首次实现从 GNN 输入输出中,生成高质量的自然语言解释,让图神经网络从「黑盒模型」变为「有理有据的决策体」。

论文链接:https://arxiv.org/pdf/2410.15268
代码链接:https://github.com/pb0316/GraphNarrator
GraphNarrator 聚焦于一种重要的图类型 Text-Attributed Graphs (TAGs),即节点特征为自然语言文本(如论文摘要、商品介绍、疾病描述等)。
论文贡献包括:
-
提出首个自然语言解释框架,将 TAG 图解释从结构层面扩展至语言层;
-
统一结构化与语言信息,桥接图结构推理与 LLM 理解能力;
-
开源工具链,提供高质量伪标签构造器+自监督蒸馏方法,便于迁移至任意 GNN 任务。
论文第一作者为 Emory 大学博士生 Bo Pan,长期从事图学习与可解释人工智能方向研究。
共同第一作者为 USC 硕士生 Zhen Xiong 和 Emory 大学博士生 Guanchen Wu,通讯作者为 Emory 计算机系副教授 Liang Zhao。
该研究获得 ACL2025 主会接收,提出首个面向图神经网络的自然语言解释生成器 GraphNarrator。
让 GNN 开口说话

GraphNarrator 总体包含三步:
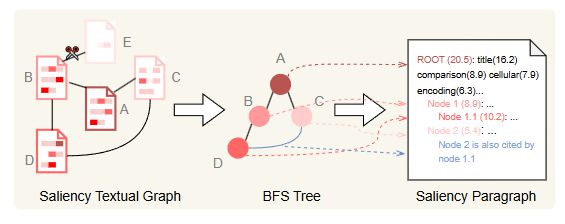
1. 构造解释伪标签(Pseudo-label Generation)
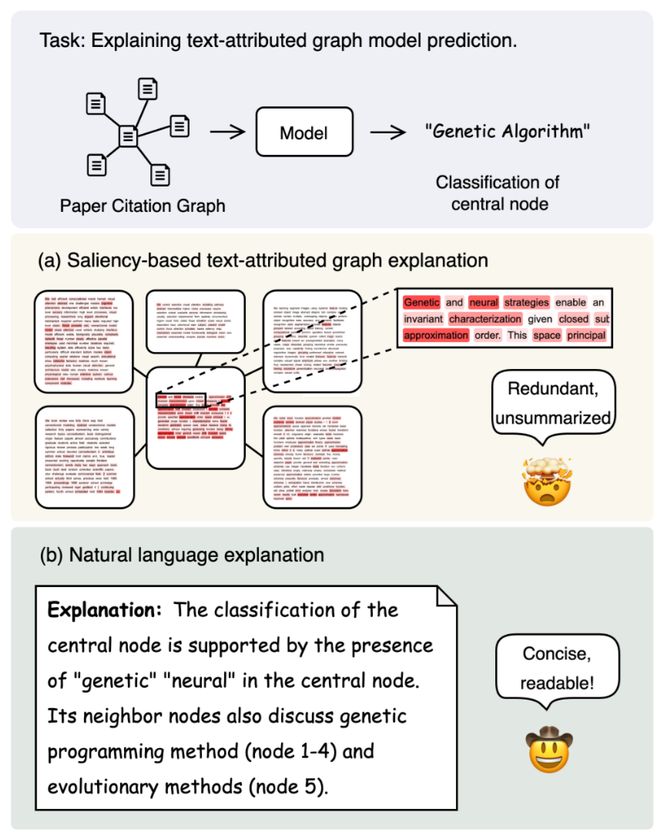
使用 saliency-based 解释方法提取「重要文本+关键邻居节点」,形式是每个特征(节点、边、token)的重要性。
将这些结构转化为结构化 Prompt,和问题与预测一起输入 GPT 模型,生成可解释伪标签。
2. 优化伪标签(Filtering via Expert-Designed Criteria)
通过两大标准筛选质量更高的伪标签:
忠实性(faithfulness):与模型预测一致,研究人员通过互信息(mutual information)的方式计算生成的文字解释与输入、输出之间的忠实性。
简洁性(conciseness):信息浓缩、可读性强,鼓励长度更短
GraphNarrator 通过专家迭代(Expert Iteration)同时优化这两个目标,确保教师模型(teacher model)生成高质量的解释。
3. 蒸馏解释器(Training Final Explainer)
将伪标签蒸馏进一个端到端模型(文章中使用 LlaMA 3.1 8B),直接输入图结构与文本,即可自动输出解释语句。
忠实、可读、用户更爱看!
数据集
研究人员在多个真实世界的 Text-Attributed Graph(TAG)数据集上对 GraphNarrator 进行了系统评估,包括:
-
Cora:论文引文图,节点为论文,文本为摘要
-
DBLP:作者合作图,文本为论文列表
-
PubMed:生物医学文献图
对比方法:
-
各主流 LLM(LLaMA 3.1-8B、GPT‑3.5、GPT‑4o)Zero-shot 生成解释
-
SMV:基于 GPT‑4o 的 saliency 解释模板转换方法
-
GraphNarrator(基于 LLaMA 3.1-8B)
评估目标是检验 GraphNarrator 生成的自然语言解释是否忠实、准确、可读、受用户喜爱。
评测结果
研究人员通过自动方式和人工方式评测该方法生成的解释质量。
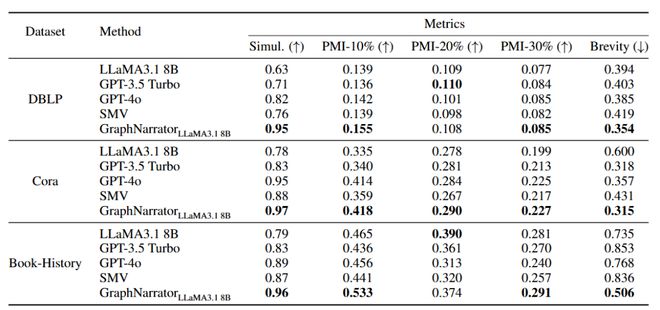
自动评测中,GraphNarrator 在Simulatability上全面领先(+8‐10%),证明解释内容高度还原了 GNN 预测;
PMI‑10% 覆盖率提升显著(平均 +8.2%),表明能捕捉到最重要的 token; Brevity(解释长度/输入长度)下降超 13%,验证其「短小精炼」能力。
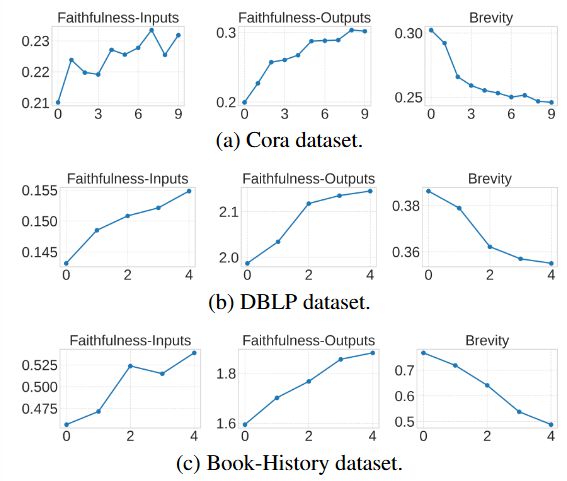
人工评测中,有计算语言学背景的评审从易读性、洞察力、结构信息、语义信息4 个方向打分(1–7 分制)。
结果表明各项均优于 GPT‑4o、SMV,尤其在结构理解上优势明显(+33%),解释更流畅、逻辑清晰,获得真实用户的更高信任。
参考资料:






