
文 | 市象,作者 | Jeff,编辑 | 杨舟
AI 的最广泛应用入口仍旧是搜索,在这个超级通道里,三个玩家已经完成自我革命挤上牌桌。
01 谷歌拉响红色警报
2022 年《纽约时报》报道,ChatGPT 发布不久,就有网友使用后给出了很高评价“ChatGPT 好强,能够替代谷歌搜索”,当时谷歌高层对此并不担心,因为这完全在他们的“意料之中”。
但乐观并没有持续多久,谷歌迅速来了一个 180 度大转弯,Pichai 亲手拉响了罕见的红色警报——在谷歌内部,“红色警报”代表的是当前、紧急、直接的危机。比如搜索或者 Gmail 这样的核心产品突然宕机,即使程序员不睡觉,也必须抢时间立刻修复。
Pichai 拉响这次警报,大概的意思是:“你们要把这次 ChatGPT 对谷歌带来的威胁,当做和谷歌搜索宕机事故一样的严重性看待。”
之前不担心,是因为早在 2021 年,谷歌就已经使用 1.56 万亿个单词在内的庞大的文档、对话等样本训练出 AI 聊天机器人 LaMDA (Language Model for Dialog Applications) ,并且 LaMDA 被《华盛顿邮报》报道后也曾引发轰动,谷歌内部工程师发现 LaMDA 不仅具有深入思考的能力,而且聊天过程中始终声称自己拥有意识和情感。 LaMDA 实际上已经具备了和 ChatGPT 基本相同的能力。

谷歌已经有自己的同类产品,甚至比 ChatGPT 问世还早,但是从 2021 年I/O大会到 2022 年年底,LaMDA 发布已经有一年半的时间了,却仍然没有像 ChatGPT 那样面向公众大规模开放。
真正让谷歌震撼的是,ChatGPT-3.5,成为了第一个从 AI 学术界破圈进入主流用户群体的产品,而自己居然没意识到:LaMDA 明明更早发布,却落后于 ChatGPT,是一个重大的错误,其严重性和紧迫性,应该被当作真实生产环境事故一样对待。
02 Perplexity 增长神话
目前市面上的 AI 搜索产品主要有三大类,一是专门的 AI 搜索,二是传统搜索引擎加入了 AI 能力,以及第三类大模型厂商做的有搜索能力的产品。
第一类以 Perplexity、纳米 AI 搜索、夸克 AI 搜索代表,第二类以 New Bing、Google AI Overview 为代表,第三类以 Kimi、豆包、腾讯元宝为代表。特别是第一类原生 AI 搜索的当红炸子鸡 Perplexity,它引发了众多后来者的“模仿”。
Perplexity 是一家神奇的公司,它以“答案引擎”来替代“搜索引擎”,这背后的逻辑——搜索是为了获得答案,答案引擎才是第一性原理。
2023 年,Perplexity 被 Google 封杀,完全禁掉流量流入,每天都挣扎在倒闭边缘。
2024 年,全世界的投资人都争先恐后地要投资,世界 10 强公司想高价收购但被它拒绝。
由前 OpenAI 研究科学家 Aravind Srinivas 联合几位合伙人共同创办的 Perplexity,在没有任何用户基础的情况下 MAU(月度活跃用户)超过千万,而这仅用了短短不到两年时间。
这样的快速增长,让许多人注意到 AI 搜索可能上演的变革——颠覆搜索引擎的往往不是另一个搜索引擎,而是跨界创新、从未见过的新物种。
Perplexity 的初代产品是一款自然语言到 SQL 的转换工具,最初面向企业客户。创始团队在市场调研中发现了传统搜索引擎的几个问题:
·传统搜索引擎结果中充斥大量广告,用户体验差。
·信息过载导致用户难以快速找到准确答案。
意识到 AI 能够从根本上革新搜索体验后,Perplexity 迅速变换方向,开发出 AI 驱动的对话式搜索引擎。Perplexity 诞生了两个重要的产品创新:
·以 AI Overview 给出的答案来替代传统搜索的网页排序。
·给出的答案标注参考出处,附带了可靠的来源链接,信息可以追溯。
简单来说,Perplexity 比 Google 更懂你的问题,又比 ChatGPT 多了真实世界的数据感知力。
传统搜索引擎需要用户不停筛选信息,阅读链接,效率低下。DeepSeek 等生成式 AI 虽然方便,但偶尔“幻觉频发” 查学术资料、做投资调研时,很难找到权威且准确的结果。
与传统搜索引擎相比,Perplexity 直接给出总结答案,它更高效、更精准。相比 DeepSeek 和 ChatGPT 这些 chatBot 输出的对话内容,又不用担心出现幻觉问题。这是它的价值所在。
Perplexity 的高质量回答还体现在学术级精准度。对于查找论文、学术资料的用户来说,Perplexity 能显著降低错误率,检索误差减少 70%。英伟达创始人黄仁勋曾说他几乎“每天都会用 Perplexity”,并且举例,想了解计算机辅助药物研发的时候,就会用 Perplexity 进行搜索。
Perplexity 还有另一个显著特点,它支持连续追问,有点像“AI 问答社区”。Perplexity 创始团队有来自美版知乎 Quora 的成员,使用 Perplexity 时你可以一问再问,它会“记住你前一个问题”,在上下文里逐步深入。不像传统搜索,每次都是“一问一搜”,用户得自己整合答案。
Perplexity 的成功,也不仅仅局限在 AI 阅读网页结合用户提问,在 AI Overview 后直接给出答案,以及答案会标注信息来源,这些已经成为了现在 AI 搜索的标配。在源头将用户提问进行深度处理,对问题本身的挖掘也是关键。根据流传的采访片段,Perplexity 创始人 Aravind Srinivas 相信“用户不会有犯错”的信念:
“虽然每个人都有很强的好奇心,但能将好奇心转化为精确问题的人很少。”Aravind Srinivas 说,Perplexity 因此花了大量时间在处理、分析和重组用户查询的问题上,也就是说,当用户提出相对含糊的问题后,Perplexity 会首先将问题处理成更有逻辑的提问方式,即优化用户的 Prompt 后,才将问题交给模型回答。
像知乎一样“相关问题”和“发现”功能的设计也出于同一逻辑,Aravind Srinivas 称,他会亲自参与“发现”选项卡背后的内容挑选,以便持续了解产品是否一直“足够简单,连普通新用户都能轻松理解”。Perplexity 首席商务官 Dmitry Shevelenko 提供的数据称,由“相关的问题”产生的用户查询占据 Perplexity 总查询量的 40%。
持续改进产品,不断提升 AI 回答质量,同时保持产品容易上手的特性,对新用户友好。Perplexity 不仅在巨头的绞杀中脱颖而出,估值更是坐上了火箭:
·2024 年初:约 5 亿美元
·2024 年 6 月:30 亿美元
·2024 年 12 月:90 亿美元
·2025 年 5 月:140 亿美元
Perplexity 最新的估值来到了 140 亿美元,ARR 在 2024 年达到了 1.2 亿美元。根据国内 AI 产品榜、36kr、硅星人|沃垠 AI 联名发布的第 23 期 AI 产品榜,仅仅在网站(web)端,4 月 Perplexity 的月度访问量达到了 1.17 亿。
03 纳米 AI 搜索“异军突起”
Perplexity 称自己为“答案引擎”的原因——作为一个从搜索 API 到底层大模型都直接“套壳”的产品,Perplexity 并不提供直接的搜索能力,而是通过接入 API 获取了搜索引擎检索的内容之后,再通过 GPT-4、Claude 等大模型将答案进行总结,最终整理成固定的格式呈现给用户。
换句话说,Perplexity 140 亿美元估值建立在精巧的产品设计之上。
Perplexity 展示的思路:AI 搜索不是搜索,而是高质量的 AI overview。Perplexity 一系列产品手段,可以总结为——对用户输入问题的“修正、定位和延续”,以及对 AI 输出回答降低幻觉、增加专业性。
AI 搜索产品真正比拼的也不是底层的技术能力,而是技术之上,谁能提供更准确可靠的答案、更快的响应速度、更智能化的用户体验。其中,“准确可靠”是拉开差距的关键,Perplexity 的隐忧恰恰也在于此。
AI Overview 要想得到高质量的答案,底层数据的质量和数量至关重要。只有底层数据库足够大、容纳的信息足够多、信息更新得足够及时,才能保证大模型在内容获取的时候“有据可依”,从而总结和输出更准确、更有时效性的内容。这也是谷歌为什么在搜索引擎领域常年保持 90% 以上市占率的原因——他们从 1998 年成立的第一天起就开始做索引,拥有全世界最大、最全的索引库,能够提供最准确和及时的搜索结果。
因此,想要让搜索结果变得更准确,自建索引库是很重要的解决办法。
目前,绝大多数 AI 搜索产品都只是接入了传统搜索引擎的 API,没有重新做一套底层的搜索系统,只有少部分如秘塔 AI 搜索(播客和文库板块)、纳米 AI 搜索以及少数的垂直 AI 搜索引擎搭建了索引库。这主要是由于接入传统搜索引擎的 API 已经能解决 95% 的问题了,加之自建索引库的成本非常高昂,需要大量的人力财力和时间,因此,如果自建的索引库不能提供比 Google 和 Bing 的 API 更加优质的内容,就没有必要自建索引库。
自建索引库的成本有多高呢?360 副总裁梁志辉曾经在一次播客中表示,爬取 5000 万网页的成本大约在 100 万-200 万人民币左右,但是 5000 万网页对于搜索引擎来说是很小的一个数字,基本上做一个搜索引擎,起码要爬取 1000 亿的网页;如果要索引全球网页的话,基本上需要 3000 台-1 万台服务器提供支持。
也就是说,做一个最简单的搜索引擎,起码要有 20 亿-40 亿元的预算,这还不包括 PageRank(网页排名)的服务器成本、终端厂商的保护费成本和人员成本。这对于任何一家中小型创业公司都是难以逾越的成本。
这也是为什么目前搜索引擎只有谷歌、微软、百度、360 等几家大厂在做的原因——做搜索引擎成本太高了,只有大厂才有充足的资金、人才去做这件事。
而除了成本高昂,搜索技术和算法也是相当有壁垒的一件事。以谷歌引以为傲的排名算法为例,它考虑了数百个不同的因素,包括内容质量、用户体验、移动友好性、页面加载速度、安全性等,不仅结构复杂,而且还会根据外界环境实时进行更新。据了解,谷歌平均每天发布 6 次算法更新,每年高达 2000 次;而且算法保密度极高,谷歌公司内部都没几个人知道其搜索排名算法的全貌。
可以想见,在如此巨大的成本+超高的技术门槛下,中小搜索引擎/AI 搜索公司想要自建面向全网索引库的难度无异于愚公移山。
套壳式产品,接入传统搜索引擎 API 不仅有“被掌控”的风险,第三方搜索引擎完全可以进行“区别对待”。自建索引库,有更精准可靠的信息来源,却是一件门槛极高的事情。
这也是 Perplexity 这样 AI 原生搜索引擎的真正软肋。没有自己的搜索,进行 AI Overview 时最关键的原始素材——搜出来的内容质量和数量都不能保证。Perplexity 单纯靠产品设计,长期来看并不能高枕无忧,有搜索的大厂想复制不难。
一个最近的例子,根据 AI 产品榜 web 端最新的数据,纳米 AI 位列 AI 搜索中国第一,也超过估值 140 亿美元的 Perplexity;在全球,New Bing 悄无声息地登顶。New Bing 和纳米 AI 恰好都有传统搜索的底子,Bing 之前一直是全球市场第二,而纳米 AI 源自 360 搜索,基本上也处在中国市场第二。两家在传统搜索有积累却无法登顶的公司,在 AI 搜索出来后,迅速发力。
像谷歌这样的搜索引擎霸主,让它复制一个 Perplexity 并不难,无论自家搜索还是自己的大模型 Gemini,它能完全从底层重新构建。让它纠结的是,在自己传统搜索产品的市场份额非常稳固,商业模式完全定型、异常成熟的时候,是否要冒着收入下降的风险,将搜索改成一个不确定性很高的新形态。
一个没有历史包袱,又有搜索积累的厂商,做 AI 搜索可能才是真正的狼来了。比如榜单靠前的纳米 AI 搜索,在 360 的搜索和浏览器、客户端的技术积累下,产品动作相当快:
·以多模融合、循环推理进行 AI Overview ,是春节期间第一个接入满血版 DeepSeek 的 AI 搜索;
·搞免费容量最高的知识库(第二大脑),搜索生成答案从公域走向私域,更加垂直和专业,让搜索开始满足个人和行业的深度定制;
·上线 MCP 万能工具箱,普通用户可以手搓超级智能体;
·超级 Agent 门槛直接拉低。开发深入办公、生活服务的高阶 Agent,成为像 App Store 这样一键下载的 App。
纳米 AI 还在做对 Deep Research(AI 深度研究搜索)的进一步扩展,能够以搜索为起点,执行任务、交付结果。用户真正的需求并不是搜索,而是搜索后做购买决策、做旅游攻略、深入研究课题、完成一个视频制作。
纳米 AI 目前支持以自然语言对话来实现超级搜索。对于用户来说,纳米 AI 能够从简单交互对话中精准感知用户意图和需求,自主规划相关搜索任务,进行目标任务拆解,每个子任务都能实现独立的深度搜索、调用工具、甚至路由调用高阶智能体,在多轮循环推理和内容生成后,最终交付执行结果。纳米 AI 超级搜索超越了传统一问一答和简单的大模型信息总结,能够实现从模糊搜索需求到具体任务执行,“端到端”的搜索体验。
当在搜索框输入“预算 500-1000,你帮我推荐几个口碑最好的运动休闲的男鞋,鞋子品牌可以是 Nike、Adidas 和安德玛”。纳米 AI 超级搜索就将任务拆解为四个子任务,查找购买攻略、分析商品信息、进行商品对比、加入购物车。

每个子任务单独进行信息搜索和 MCP 工具调用,比如在小红书收集各个品牌的购买攻略。
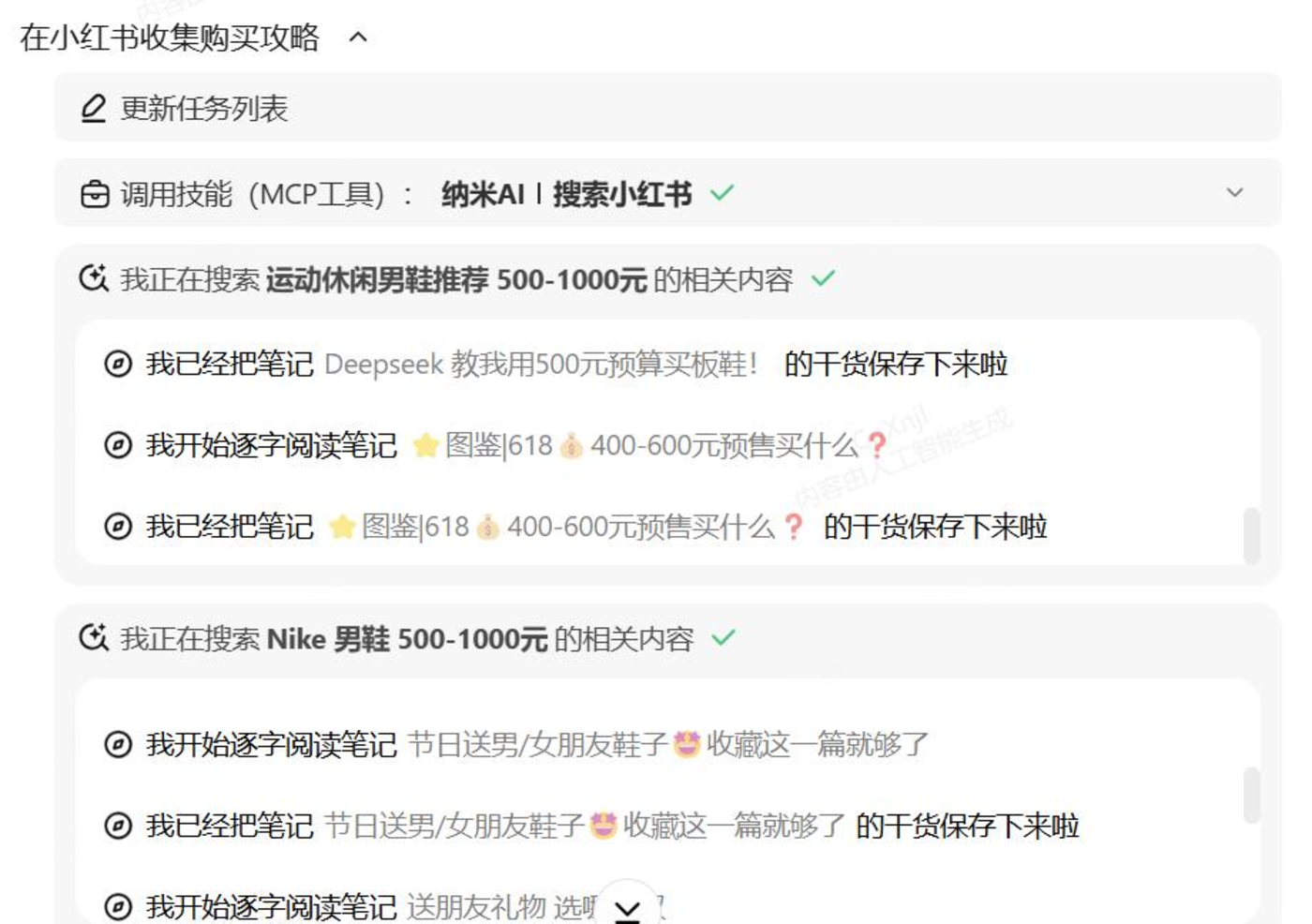
在淘宝、京东等电商平台,收集和分析相应的商品价格信息。
纳米 AI 超级搜索更与众不同的地方,子任务拆解也并不仅仅是类似 Deep Research 的过程,在目标任务的分配中,可以路由到具体的垂直智能体,实际体验下来,功能相当的强悍。
04 谷歌以“AI Mode”反击
时间跨到 2025 年 5 月,Perplexit 估值达到了 140 亿美金,谷歌也开始了“反击”——将包括搜索、浏览器在内的产品,一瞬切换到“AI Model",特别是搜索,彻彻底底向“AI 智能搜索”脱胎换骨。
谷歌搜索将不满足于在生成结果中显示“谷歌摘要”的简单 AI Overview,而是直接在结果分类中新增“AI 模式”标签,展示效果类似独立 AI 搜索应用。
其中三个特点几乎跟纳米 AI 超级搜索“重合”:
纳米 AI 超级搜索是将复杂意图拆解成子任务,每个子任务都能独立调用搜索和 MCP 工具。谷歌 AI 智能搜索,支持复杂、多轮、多模态提问;通过 “query fan-out”机制,将问题自动拆解成多个子查询,深入搜索更广泛网页资源; 并且整合 Gemini 2.5 定制版本,提升理解力、回应准确性与逻辑结构。
纳米 AI 在子任务上即可发起类似 Deep Research 的搜索和信息整合过程。谷歌 AI 智能搜索则是深度功能拓展:自动生成专家级研究报告,针对复杂查询(如论文研究、技术主题),AI Mode 可发起上百次自动搜索,汇总、推理并形成完整引用的深入报告,节省数小时调研时间,适合高等教育、商业研究与学术探索场景。
纳米 AI 超级搜索可以根据目标,路由到相关智能体去执行子任务,谷歌智能搜索同样是以智能代理(Agentic Capabilities),让 AI 为你办事。谷歌智能搜索能自动任务执行,当前支持购票、订餐、预约,未来拓展更多场景,还能实现信息同步与结账转接。
更巧的是,纳米 AI 团队有多年浏览器开发经验,定制了专用的 AI 浏览器,而谷歌 Chrome 浏览器中将加入 Gemini AI 助手,未来将能够“跨多个标签页工作,并代表用户浏览网站”。
移动互联网时代是 APP 信息孤岛时代,搜索的内容碎片化,这是普遍的用户痛点。纳米 AI 搜索融合了高阶智能体能力,以 MCP 工具调用和 AI 浏览器的 Agent 浏览动作,模仿人类的 computer use,做到了全域搜索,电商、内容、短视频此前互相割裂的内容终于被“统一”。
纳米 AI 超级搜索和谷歌 AI 智能搜索,两家都是用 AI 突破了内容高墙,并且让搜索从排序答案,到搜索意图的完整执行。
AI 搜索正在实现从搜索需求理解到交付结果的跨代。屠龙者 Perplexity 打醒了巨龙谷歌,拥有“传统搜索恶龙”和“AI 搜索屠龙者”双重身份的纳米 AI 搜索和 New Bing,正在闷声发财。






