
新智元报道
编辑:桃子
不到两年,我们会见证 AI 数学家的重大突破!最新实验中,o4-mini 与 40 位数学家,一同挑战 300 道菲尔兹奖级难题。o4-mini 一举击败 6 组团队,超越人类平均水平。
八支「数学家天团」和 o4-mini-medium 同台竞技,谁会最终胜出?
最近,Epoch AI 团队举办了一场竞赛,专门考察 AI 数学能力的进展。

这场比赛邀请了约 40 位数学精英,分成 8 组,每组由学科专家和优秀本科生组成。
他们要与 AI 一同在陶哲轩等人提出的 FrontierMath 基准上,展开终极对决。
比赛一共 23 题,限时 4.5 小时,实验最终得出:
o4-mini-medium 碾压人类平均水平(19%),解决了约 22% 题目。
不过,o4-mini 能够解决的问题,至少被一组数学家团队破解。由此,人类团队总体上解决了约 35% 的题目。
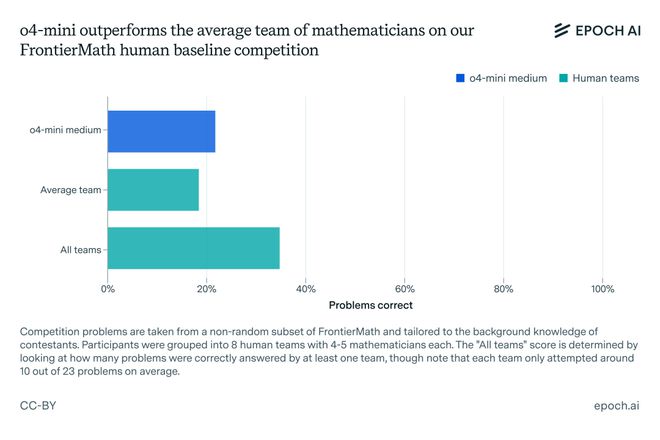
结果显示,o4-mini 一共击败六组团队,在数学领域展现了惊人的潜力。
谷歌前 CEO Eric Schmidt 预测,未来1-2 年内,「超级程序员」和「AI 数学家」将取得重大突破。

o4-mini,作为 AI 的代表,便是一个很好的开始。
菲尔兹奖得主出题,AI 击败 6 队
提及 FrontierMath,想必圈内人无人不知。
这一基准于 24 年 11 月首次亮相,由菲尔兹奖得主与业内多位著名数学家共同出题,挑战 AI 数学能力的极限。

它包含 300 个问题,难度从高年级本科生水平到菲尔兹奖得主都认为具有挑战性的问题。
那么,这么多数学难题,人类在其表现中如何呢?
为了确定人类极限,Epoch AI 便在 MIT 组织了这场比赛——FrontierMath Competition。

如上所述,每组被分成4-5 人的 8 组团队,在联网情况下,最多用 4.5h 去解决 23 个数学题。最后,再与 o4-mini-medium 进行比拼。
o4-mini-medium 的表现虽超过了平均人类团队,但不如所有团队的综合得分。
因此,在 FrontierMath 上,AI 尚未完全超越人类,但 Epoch AI 认为顶尖模型很快就会做到。
目前,这份数据仅代表 FrontierMath 的一个小型非代表性子集。
若综合考虑,人类整体基准大约在 30-50% 之间。
接下来,Epoch AI 详细解释了关于人类基准结果的四个关键点,包括其中来源和含义。
人类选手,并不代表数学 SOTA
人类团队的表现,因团队而异构成。
由于参赛者主要来自波士顿数学社区,分析领域的专家较少,导致了整体专长分布不均。
每队虽至少有一名某一领域的专家,但也没有哪支队伍在所有高级领域,如拓扑学、代数几何、组合数学、数论等都有专家覆盖。
这使得人类平均分,可能低估了真实水平。
最重要的是,比赛 4.5 小时时间,可能限制了人类的表现。AI 解决每题只需5-20 分钟,而人类平均耗时约 40 分钟。
此前研究表明,人类在长时间任务上表现更具潜力,而 AI 性能可能在一定时间后趋于平稳。
为了更全面评估,研究团队采用了两种方式计算人类基准:
1. 团队平均得分:每支队伍独立表现,得分约 19%
2. 综合得分:如果任一队答对某题就算正确,得分提升至约 35%
若要为整个 FrontierMath 设定人类基准,还需解决第二个问题:比赛问题的难度分布与完整 FrontierMath 数据集不同。
为此,研究人员按难度层级拆分结果,并根据完整基准的难度分布加权总体得分。

结果,按整体难度分布加权后,人类基准提升到约 30%,基于「多次尝试」方法,更是刷新到了 52%。
而此时,AI 的加权得分约为 37%。
Epoch AI 指出,o4-mini-medium 得分提升,是因为比赛中的 Tier 1/Tier 2 问题相对完整基准的同级问题较简单,说明了这一调整方法仍不理想。
设计巧思:推理而非知识
FrontierMath 比赛的独特之处在于,它更注重数学推理能力,而非单纯的知识储备。
当前,AI 在知识广度上远超人类——可以轻松调用数学、微分几何等庞大知识库,而人类很难精通所有领域。
因此,比赛题目被精心设计,尽量减少对背景知识的依赖。
比如,研究人员选用了 7 道适合优秀本科生的「通用问题」,以及 16 道专为专家定制的「高级问题」。
这些题目主要覆盖了四大类:拓扑学、代数几何、组合数学和数论。
为了激励参赛者挑战高难度题目,比赛还采用了特殊计分规则:
高级题目每题 2 分,通用题目每题 1 分;每个领域至少答对一题可额外加 1 分。
此外,奖金池也非常诱人,第一名 1000 美元,第二名 800 美元,第三名 400 美元。
全面超越人类,指日可待?
尽管 o4-mini-medium 在 FrontierMath 上,尚未完全超越人类,但其表现已令人瞩目。
它在比赛的得分不仅于人类顶尖团队相当,而且在知识广度上占据巨大优势。
Epoch AI 预测,到 2025 年底,AI 和可能明确超越 30%-50% 的人类基准。

有网友对此表示,要让 AI 成为超人的存在,必须定期解决人类数学家无法解决的问题。

然而,AI 的成功机制依然是一道谜题。
它们究竟是靠猜测解题,还是真正掌握了数学推理?与人类的方法相比,有何不同?
在研究人员看来,这些问题有待进一步探索。
此外,FrontierMath 的题目并非实际数学研究的直接代表,o4-mini 的超人表现是否会转化为研究突破,仍需要时间来验证。
参考资料:






