
5 月 23 日消息,美国时间周四,AI 独角兽 Anthropic 震撼发布最新大模型 Claude Opus 4 与 Claude Sonnet 4,将无监督(无人干预)AI 的任务处理能力推至全新高度。
其旗舰产品 Claude Opus 4 在乐天集团压力测试中连续 7 小时专注开源代码重构,这项突破使 AI 从即时应答工具蜕变为全天候项目协作者。
这种持续专注能力标志着 AI 模型的注意力跨度实现数量级跃迁——从分钟级跨越至小时级。技术突破带来根本性变革:AI 现已具备从项目设计到交付全周期的复杂软件开发能力,全程保持上下文一致性。
Anthropic 官方宣称,Claude Opus 4 在严格评测软件工程能力的 SWE-bench 测试中斩获 72.5% 得分,大幅超越 OpenAI 四月亮相的 GPT-4.1(54.6%)。此举奠定该公司在 AI 赛道白热化竞争中的强劲挑战者地位。
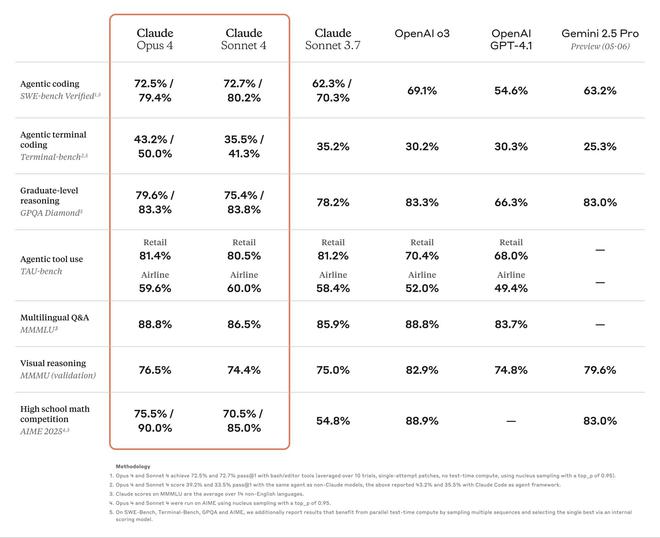
超越快速应答:推理革命重构 AI 底层逻辑
2025 年人工智能行业经历剧烈转向,全面拥抱推理模型。这类系统在响应前会系统化推演问题解决路径,模拟类人思维机制,而非简单依赖训练数据的模式匹配。
OpenAI 于 2024 年 12 月通过"O"系列模型开启变革,谷歌随即在 Gemini 2.5 Pro 中搭载实验性"深度思考"模块。而 DeepSeek 的 R1 模型凭借卓越问题解决能力与价格优势,意外攻占市场。
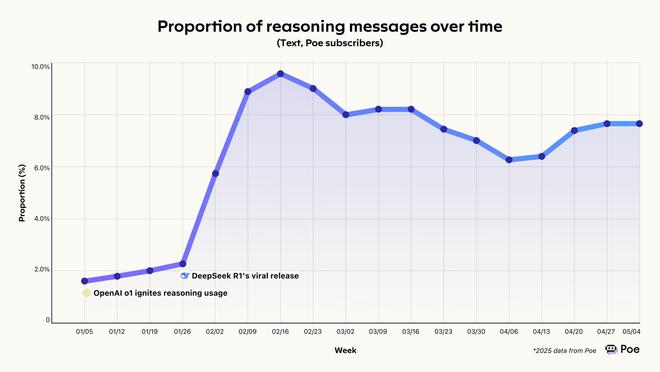
这场转型标志着人机交互范式的根本转变。Poe《2025 春季 AI 模型使用趋势报告》显示,推理模型使用率四个月内激增五倍,在 AI 交互中占比从2% 飙升至 10%。用户逐渐将 AI 视为复杂问题的认知协作者,而非问答机器。
Claude 新模型的差异化优势在于工具调用与推理流程的深度整合。这种"研究-推理并行"机制,相较传统"先信息采集后分析"模式更贴近人类认知神经科学原理。推理过程中主动暂停以检索数据、整合新发现的能力,创造了更符合直觉的问题解决体验。
双模态架构:速度与深度的动态平衡
Anthropic 通过混合架构破解了 AI 用户体验的持续性痛点。Claude 4 系列既能毫秒级响应简单查询,又可启动长达数分钟的深度推演,彻底消除早期推理模型连基础问题都延迟响应的挫败感。
这种双模态功能在保持用户预期的迅捷交互同时,解锁了深层次分析潜能。系统根据任务复杂度动态分配计算资源,达成前代模型未能实现的黄金平衡点。
记忆持久化是另一里程碑突破。Claude 4 系列可从文档提取关键信息生成知识图谱,并在获得授权后实现跨会话记忆继承。这解决了制约 AI 在长周期项目中应用的"记忆缺失"顽疾,使上下文关联可持续数周。
技术实现层面,Claude 4 运作机制仿效人类专家知识管理系统:AI 自动将信息组织为树状结构数据库,优化未来检索效率。这种方式使 Claude 能在持续交互中渐进完善对复杂领域的认知建模。
竞争升级:AI 巨头打响市场份额争夺战
Anthropic 发布 Claude 4 的时机,精准折射出高阶 AI 市场的加速度竞争。距 OpenAI 发布 GPT-4.1 系列仅隔五周,Anthropic 便推出关键指标超越前者的模型。谷歌本月初升级 Gemini 2.5 产品线,Meta 则发布搭载多模态能力与千万 token 级上下文窗口的 Llama 4。
在垂直化程度激增的 AI 市场,头部实验室已形成差异化护城河:OpenAI 领跑通用推理与工具链整合,谷歌称霸多模态理解,Anthropic 则以持续算力输出与专业级代码应用登顶。
这对企业客户的战略决策产生深远影响:组织机构必须基于具体场景选择专用 AI 系统,全维度碾压型模型已成历史。市场碎片化趋势既为具备 AI 架构能力的企业创造优势,也对寻求标准化解决方案的公司构成挑战。
开发者工具成熟化驱动企业级融合
Anthropic 通过正式发布 Claude Code,深度集成开发工作流。该系统现支持 GitHub Actions 后台任务执行,并深度集成 VS Code 和 JetBrains IDE,直接在开发者文档中呈现代码优化建议。
GitHub 决定采用 Claude Sonnet 4 作为 GitHub Copilot 新代码智能体的基础模型,这为 Anthropic 提供了关键市场认证。与微软开发平台的此次合作,揭示科技巨头正构建多元化 AI 生态联盟,摒弃单一供应商依赖模式。
Anthropic 同步推出四大新 API 功能:代码执行工具、MCP 连接器、文件 API 及长达 1 小时的提示缓存。这些升级赋能开发者创建可贯穿复杂工作流的智能体系统,成为企业级应用落地的技术基座。
模型越精密,透明度困局越凸显
Anthropic 在 4 月发布的《推理模型并不总会表露真实思维》研究论文,揭示了这类系统在思维过程阐述中的系统性缺陷。数据显示,Claude 3.7 Sonnet 仅在 25% 的问题解决场景中主动披露其使用的关键推理线索,这引发对 AI 决策透明度的根本性质疑。
该研究直指行业痛点:模型能力演进与可解释性背道而驰。Claude Opus 4 的七小时自主编程演示在彰显持久工作能力的同时,也暴露出人类审计超长推理链的技术鸿沟。
人工智能行业正面临一个悖论:性能越卓越,黑箱效应越显著。破解这一困局需要平衡性能与可追溯性的新型监管框架——Anthropic 虽公开承认该挑战,但尚未给出系统性解决方案。
持续型 AI 协作范式初现
Claude Opus 4 的七小时连续作业,勾勒出 AI 在知识工作领域的未来图景。随着模型获得跨时段的注意力维持与记忆优化能力,其正从工具进化为全天候协作者,能在最小化人类干预下完成复杂的长周期任务。
这一演进将重构知识工作体系:曾经依赖人类持续专注的工作流,现可委托给具备多日上下文维持能力的 AI 系统。在软件开发等长期面临人才缺口与高人力成本的领域,其引发的经济范式变革将尤为剧烈。
当 Claude 4 持续模糊人机智能边界,职场生态正在经历范式迁移。我们的核心挑战已从"AI 能否达到人类水平",转变为如何适应数字智能体成为高效生产力伙伴的新常态。(小小)






