
新智元报道
编辑:编辑部 XYH
刚刚,昇腾两大技术创新,突破速度瓶颈重塑 AI 推理。FusionSpec 创新的框架设计配合昇腾强大的计算能力,将投机推理框架耗时降至毫秒级,打破延迟魔咒。OptiQuant 支持灵活量化,让推理性价比更高。
「前 DeepSeek」时代,人们普遍认为「有卡才能推理,没卡寸步难行」。
而 DeepSeek 却凭借一系列软件层面的架构创新,把这一硬性门槛直接抬走,同时开创了中国人自己的 AI 大航海时代。
不过,虽然诸如 V3 和 R1 等超大规模 MoE 性能卓越,但在部署时却存在着非常大的挑战——推理的速度和延迟。
心理学和行业实验一致表明,LLM 吐出第一个 token 所用的时间(TTFT),以及每秒生成的速度直接决定了用户的「等候感」。超过 100 毫秒即可感知,超过 2 秒即可打断思考。
对于 AI 应用来说,这里有一个简单的公式可以说明:更快速度+更低延迟=更高满意度+更高转化率。

为了解决这一核心问题,华为通过两个全新的方法和思路,对 MoE 模型进行了专门的推理优化,让中国模型在中国的服务器上的推理速度来到了全新的高度!
-
FusionSpec打破了大模型推理「延迟魔咒」,依托于昇腾「超高」计算带宽比的特点,创新性地重塑了主模型和投机模型的流程,结合轻量级步间准备,将投机推理框架耗时做到了 1ms。
-
OptiQuant不仅支持主流量化算法,同时具备灵活的自定义组合能力,涵盖了业内主流评测数据集,为大模型推理提供了更强性价比。
华为挑战 MoE 推理的「两把刷子」
早期 LLM 的推理通常使用自回归解码方式,即「每次只能预测下一个 token」。
且需将历史输出作为输入进行下一步解码,导致推理过程串行、效率低下、计算密集度低。
如何解决这个问题?投机推理技术应运而生。
投机推理(Speculative Inference),也被称为推测性解码,其核心思想是利用计算代价远低于大模型的小模型(也称为投机模型),先行对后续可能的输出进行猜测,然后由大模型对这些猜测结果进行验证,从而实现并行化推理,提升整体推理速度。
这个道理其实也简单,就像写作文的时候,你先在草稿上「预测」几个可能句子(投机模型猜测),再挑出合适的句子写到正式作文里(大模型或者叫主模型验证)。
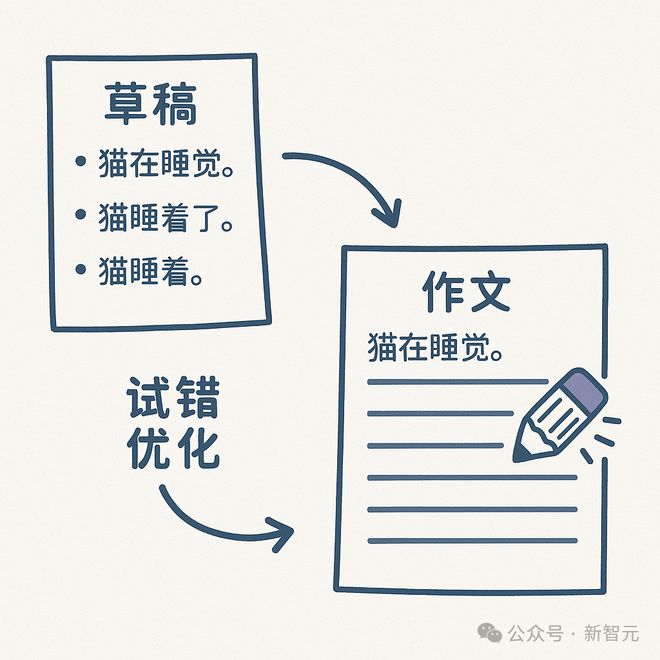
如果草稿上预测的都不对,那就把作文里的擦掉重写就好了(回退修正)。但要是预测对了,写作文的速度(大模型的输出速度)就能更快——毕竟草稿纸上的修改成本远低于正式作文。
这种「先试错再优化」的思路,让大模型能更快、更准的给出答案(也就是推理速度又快又好)。
然而,是想要完美将投机模型和主模型相结合,依然面临很大的困难。
1. 推测准确性与草稿生成效率的权衡
小模型的主要任务是快速生成可能的输出,但这往往与生成结果的准确性相矛盾。如何在两者之间找到最佳平衡点,是投机推理技术面临的一大挑战。
2. 批处理推理场景的适配
在实际应用中,批处理推理可以提高系统的整体吞吐量。投机推理本质上来说是用空闲的算力换取更高的吞吐,需要处理好投机模型和投机框架引入的耗时,不然无法发挥投机推理在批处理场景下的加速潜力。
另一方面,仅有投机推理技术也不够,推理性能提升还需与模型压缩、量化、增量式解码等有效集成。
超大规模 MoE 动辄百亿、千亿参数量,对显存带宽、计算能力和互联网带宽需求,提出了极高要求。尤其长序列推理中的 KV cache,更是堪称显存「无底洞」。
在此背景下,量化技术就成了缓解资源约束、优化部署效率的「救命稻草」——在大幅降低资源占用的同时,还能尽量保留模型精度。
以 INT8 量化为例:
-
权重量化可以将模型参数的显存需求降低 50%,配合激活值量化,利用 Cube-Core 的 INT8 算力加速矩阵乘运算。
-
KV cache 量化则进一步压缩了显存占用,支持更长的序列和更高的并发请求,大幅提升了 Decode 阶段的系统吞吐量。
尽管低比特量化被视为 LLM 推理的灵丹妙药,但若要实现高质高效的量化,并非易事。
1. 精度的损失
将模型参数从高精度压缩到低精度,不可避免会导致精度下降。尤其是,在极低比特数(如二值)情况下更为明显。
2. 算法的「两难抉择」
如何去设计高效、抗噪的量化算法,在保持精度同时,降低计算和访存复杂度,依旧是行业研究重点。
过于复杂的算法,虽能提升精度,但会增加计算开销,抵销量化的效率优势。而过于简单的算法,又会牺牲过多精度,最终导致模型效果不佳。
3. 硬件兼容的适配
量化后的模型还需与硬件深度适配,而现有的量化算法在昇腾硬件上还有很多创新优化的空间。
此外,量化误差的控制和推理过程中的动态调整策略,也充满了挑战。
4. 校准集泛化性缺失
校准集的泛化性缺失导致了在很多任务上,难以达到与原有模型相近的精度水平,甚至在某些场景下精度下降十分严重。
不论是投机推理,还是低比特量化,都是推理优化过程核心,它们所面临的难题,是 LLM 飙速推理路上最大的绊脚石。
而现在,华为的这套方案,彻底攻克所有挑战,解锁了 AI 模型的中国速度。
投机推理框架 FusionSpec
创 1ms 奇迹
具体来说,在投机推理方面,华为团队提出了投机推理框架 FusionSpec。
FusionSpec 充分利用了昇腾服务器高计算带宽比的特点,在低时延大并发场景下,深度优化了 DeepSeek 提出的 MTP 在昇腾上的推理性能,将投机推理框架耗时减小至 1ms,并在三个方面进行了重大创新:
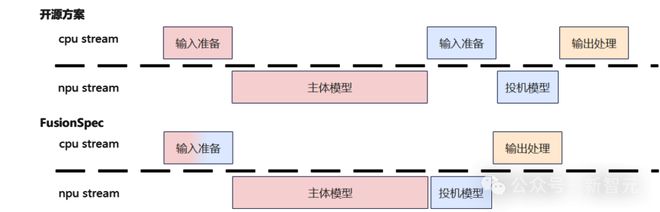
1. 考虑到 DeepSeek 的模型架构,MTP 层需要主体模型的最后一层结果作为输入,将 MTP 层的执行直接排在主体模型执行之后。
这样做带来两个优势:
-
优化后的调度顺序避免了推理的步间数据传输
-
在PD分离的部署场景下,投机模型的后置解耦了 PD 分离系统与投机框架,同时有效减少了节点间的数据传输
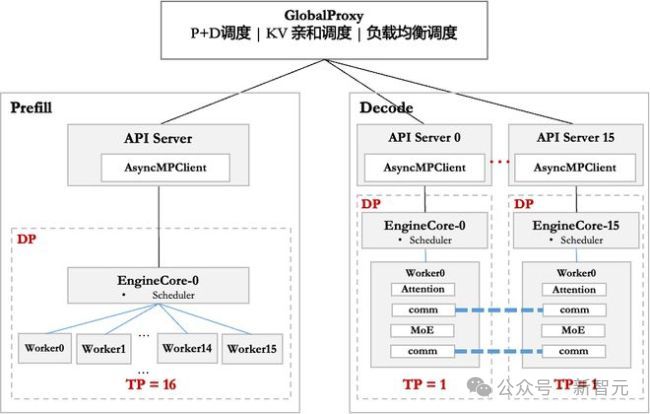
昇腾基于 PD 分离部署的 vLLM 框架调度示意图
2. 参考 MTP 层训练模式,将 MTP 层视为模型的一部分,注意力算子复用主体模型的控制参数。
DeepSeek V3/R1 为代表的主流的大语言模型采用旋转位置编码 RoPE。在使用投机模型进行预测时,会按实际推理的 token 个数进行位置编码。
但对 MTP 层而言,计算时会忽略输入的第 0 个 token。因此,研究团队把 MTP 层输入的第 0 个 token 舍去,前移其余 token,并复用主体模型的控制参数。
而 RoPE 保证了对所有 token 进行平移后的 attention score 不发生改变。这样,就可以保证 MTP 层的正确计算,同时节省 CPU 上的准备时间,并简化整个系统的 block 管理。
·参数复用省去了控制参数的重新构造,降低了框架耗时
通过主体模型前置与流程拼接,将单步投机推理中输入准备从两次降低为一次,避免主体模型和投机模型之间 CPU 同步打断流水,压缩了单步推理内主体模型与投机模型间的框架耗时,使得投机推理的整体框架时延与非投机场景一致。
基于上述优化,FusionSpec 框架实现了在较低时延下的高并发、大吞吐。
3. 实现了 NPU 上的轻量步间准备,支撑了 vLLM v0 的 multi-step 以及 vLLM v1 前后处理全异步,进一步降低了步间的框架耗时。
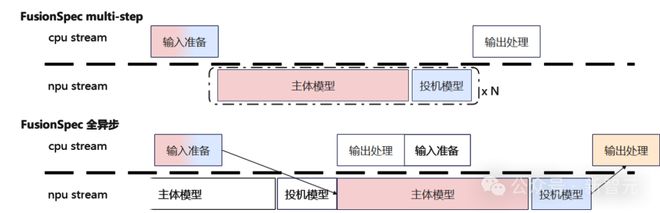
除了模型结构和框架设计优化外,在算子级别的细化加速同样关键——这就是 FusionSpec 进一步优化的重点。
· 投机场景 MLA 算子加速
DeepSeek 提出的对多头潜注意力机制 MLA,通过对 Key 和 Value 的低秩联合压缩,不仅大幅减少了所需的 KV 缓存量,同时性能还超过了传统的 MHA。
为了充分利用昇腾的计算能力,压缩端到端输出时间,FusionSpec 进一步优化了投机场景 MLA 计算流程,减少矩阵的搬运时间。
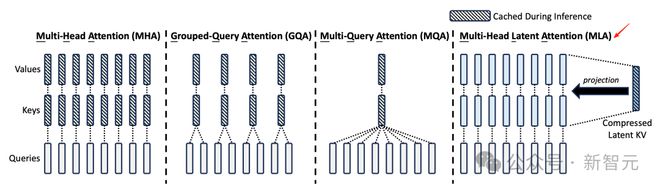
投机场景下多头潜在注意力 MLA 算子优化
·TopK、TopP 算子加速
在投机推理场景中,若预测m个 token,单步推理需进行1+m次词表采样操作,所以采样操作的速度变得更加重要。
采样操作一般包含温度、TopK、TopP 三步,其中 TopK、TopP 需要排序,并且计算前缀和,这些是采样操作的瓶颈。
未来,FusionSpec 将采用流式过滤策略、昇腾归并排序 API 优化 TopK、TopP 计算。
量化框架 OptiQuant
让 MoE 巨兽飞起来
在量化方面,华为团队则提出了 OptiQuant 量化框架。
它不仅兼容业界主流量化算法,通过一系列功能创新,为高效部署提供了强力支撑。具体来说,它有四大核心亮点:
· 丰富的量化和数值类型
OptiQuant 支持了 Int2/4/8 和 FP8/HiFloat8 等数据类型,与业界 Qserve、HQQ、LUT 等主流量化方法兼容。
在此基础上,OptiQuant 创新性提出「可学习截断」、「量化参数优化」等算法,将量化误差进一步降低。
· 业内主流评测数据集
OptiQuant 支持多样化评测任务,包括判断题、问答题、代码题和数学题等多个方向,覆盖了十种常见的语言。
为了提升量化模型的泛化能力,OptiQuant 还引入了混合校准集的方法,按一定的比例混合不同数据集。
· 量化权重以及元数据的生成
OptiQuant 提出了自适应层间混精算法和 PD 分离量化权重,并且根据对应的量化配置生成对应的权重参数,通过去冗余技术减少参数保存的参数量。
同时,FlexSmoothQuant 等算法在数据校准过程中,将搜索到的元数据进行保存,并用于后续推理过程。
· 量化权重推理
OptiQuant 提出了 KVCache 量化和 MoE TopK 专家剪枝技术。
结合昇腾亲和的量化算子,OptiQuant 通过高效数据并行/流水并行,针对不同大小的大语言模型实现精度验证性能加速,将对各个数据集精度评估性能提高了 5x 以上。
此外,OptiQuant 还支持 Vector Quantization、DFloat11、可逆变换、量化模型微调等技术点。
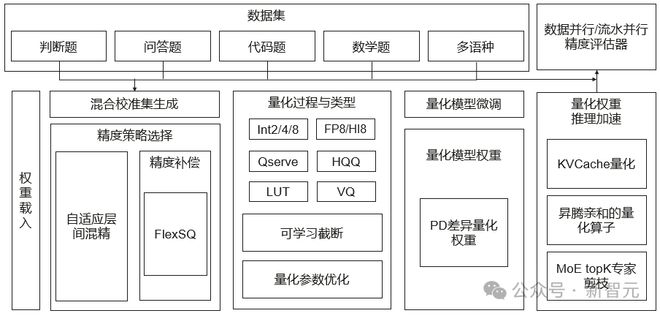
OptiQuant 量化框架
通过 OptiQuant 和相关优化算法,华为实现了 W8A8C16/W4A8C16 的模型精度,媲美 FP8 精度的效果,并充分发挥了昇腾硬件性能。
表1:DeepSeek-R1 模型精度测试结果

注1:如无特殊说明, 测试为单次结果
注2:测试 3 次以上结果取平均
注3:单次测试结果
表2:DeepSeek-V3-0324 模型精度测试结果

注1:单次测试结果
下一步,团队还将探索 PD 差异量化、KV cache 量化、TopK 专家剪枝、通用的等价变换建模、和量化微调等方向,实现更高效、更低比特的权重、激活和 KV cache 的量化模型推理技术。
总而言之,FusionSpec 和 OptiQuant 的双剑合璧,将为超大规模 MoE 模型推理开辟了全新路径。
这两大框架的提出,打破了 LLM 推理的延迟魔咒、资源瓶颈。
这不仅仅是一次技术的突破,更是中国 AI 在全球舞台上的一次强势发声。
未来,FusionSpec 推理框架和 OptiQuant 量化框架有机融合,将促使更多的创新涌现出来。
技术报告:
技术博客:






