
InfiniteHBD 团队投稿
量子位 | 公众号 QbitAI
随着大模型的参数规模不断扩大,分布式训练已成为人工智能发展的中心技术路径。
如此一来,高带宽域的设计对提升大模型训练效率至关重要。
然而,现有的 HBD 架构在可扩展性、成本和容错能力等方面存在根本性限制:
以交换机为中心的 HBD(如 NVIDIA NVL-72)成本高昂、不易扩展规模;以 GPU 为中心的 HBD(如 Google TPUv3 和 Tesla Dojo)存在严重的故障传播问题;TPUv4 等交换机-GPU 混合 HBD 采用折中方案,但在成本和容错方面仍然不甚理想。

为解决上述问题,北京大学、阶跃星辰和曦智科技的研究团队提出了InfiniteHBD,这是一种以光交换模组为中心的高带宽域架构。
InfiniteHBD 通过将低成本光交换(OCS,Optical Circuit Switching)能力嵌入每个光电转换模组,实现了数据中心规模的低成本可扩展性和节点级故障隔离能力。
InfiniteHBD 的单位成本仅为 NVL-72 的 31%,GPU 浪费率接近零(比 NVL-72 和 TPUv4 低一个数量级以上),且与 NVIDIA DGX(每节点 8 个 GPU)相比,MFU 最高提升 3.37 倍。

该项目论文已被SIGCOMM2025 接收。
现有大模型训练的 HBD 架构的三类关键组件
大模型的分布式训练涉及多种并行策略,每种策略对应不同的通信需求。
数据并行(DP,Data Parallelism)、流水线并行(PP,Pipeline Parallelism)、上下文并行(CP,Context Parallelism)和序列并行(SP,Sequence Parallelism)等策略通信开销较低,通常可通过传统数据中心网络(如 Fat-Tree 或 Rail-Optimized 架构)提供的 200–800 Gbps 带宽完成。
而张量并行和专家并行则通信密集,需依赖高带宽域(HBD,High-Bandwidth Domain)提供 Tbps 级带宽支持,因此 HBD 成为影响训练效率的关键因素。
现有用于大模型训练的 HBD 架构,可根据其提供连接的关键组件分为三类。
第一类是以交换机为中心的 HBD,如 NVIDIA 的 DGX 和 GB200 NVL 系列。
这类架构通过交换机(如 NVLink Switch)互连 GPU,能够实现高性能的任意节点通信(any-to-any communication)。
然而,以交换机为中心的 HBD 存在几个明显的局限:
- 大量使用高带宽交换机和链路,导致互连成本大幅上升,限制了系统的扩展能力,并引发严重的资源碎片化。例如,在 NVL-36 上运行 TP-16 作业时,即使无故障发生,仍有约1/9 的 GPU 无法利用,造成资源浪费。
- 存在交换机级的故障爆炸半径问题,即单个交换机故障可能导致其下所有 GPU 的带宽受损,显著影响整体训练性能。
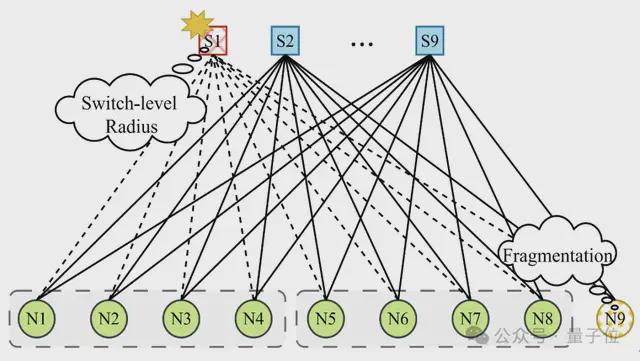
第二类是以 GPU 为中心的 HBD 架构,如 SiP-Ring、Google TPUv3 和 Tesla Dojo。
这类架构通常构建 Ring 或 Mesh 拓扑的 GPU 间直连,显著降低了互连成本并提升了扩展性。
但与此同时,它们也面临 HBD 级别的故障爆炸半径问题:单个节点故障会导致相邻一组节点的带宽降级,并且破坏整个拓扑结构。
例如,在 SiP-Ring 中,任一 GPU 故障都会中断环形连接,将原本的环状拓扑退化为一条线性拓扑,严重影响通信性能。
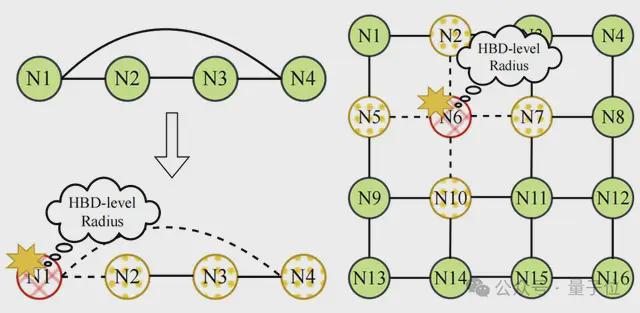
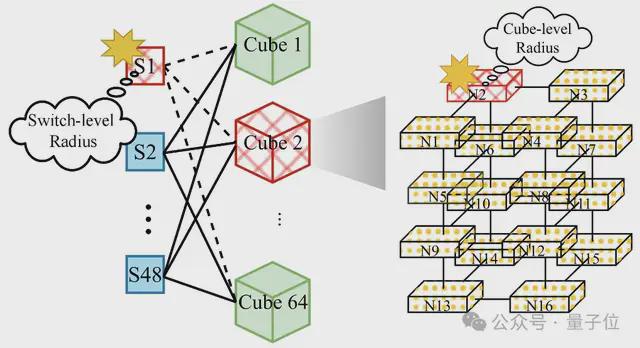
第三类是交换机-GPU 混合型 HBD 架构,这类设计结合了 GPU 间直连和交换机链路。
一个典型代表是 TPUv4,它将 TPU 组织成4×4×4 的立方体结构,并通过光交换机(OCS)互连各个立方体,支持规模扩展至 4096 个 TPU。
TPUv4 在互连成本与扩展性之间取得了一定平衡,同时能够将节点故障隔离在各自的立方体内部。
然而,TPUv4 仍存在一些显著不足:
由于 OCS 交换机故障,仍可能出现交换机级别的故障爆炸半径问题。
立方体级故障爆炸半径,即立方体内任一节点故障,可能导致整个立方体通信性能下降,影响训练效率。
如下图所示表格中所总结的,现有的 HBD 架构在可扩展性、互连成本、容错性和碎片化方面存在根本性的限制。

为了指导更优的设计,研究人员分析了现有训练工作负载,并总结出理想 HBD 应具备的三大关键属性:
- 随着集群规模和模型规模的扩大,最大化 MFU(Model FLOPs Utilization)所需的最优 TP 组大小也不断增长。这凸显了 HBD 需要支持大规模、动态可重配置 TP 大小的重要性。因此,理想的 HBD 应兼具低成本、高扩展性和灵活重构能力。
- 由于 EP 存在负载不均的问题,MoE 模型在采用大规模纯 TP 训练时,依然能够相比 EP 保持较高的效率。这表明,只需针对 TP 的 Ring-AllReduce 通信进行优化,便可覆盖大部分主流训练场景,同时大幅简化拓扑设计的复杂性。
- 此外,HBD 还应具备出色的容错能力和高 GPU 资源利用率,确保在节点故障情况下训练任务依然能够高效运行。
基于以上分析,研究团队提出设计一种面向大规模训练、支持动态重构、低成本且高容错的 HBD 架构,专门针对 TP Ring-AllReduce 通信进行优化,助力下一代大模型训练。
InfiniteHBD 包含的三项关键创新
InfiniteHBD 提出了一种以光交换模组为核心的 HBD 架构,采用了 OCS 技术。
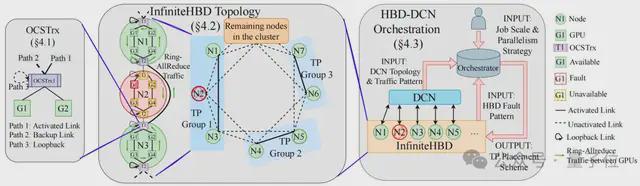
通过在光电转换模组中嵌入 OCS 能力,InfiniteHBD 实现了动态可重构的点对多点连接,具备节点级故障隔离和低资源碎片化的能力,在可扩展性和成本上全面优于现有方案。
InfiniteHBD 的设计包含三项关键创新:
- 基于硅光子技术的 OCS 光电转换模组(OCSTrx)
- 可重配置的K-Hop Ring 拓扑。
- HBD-DCN 编排算法。
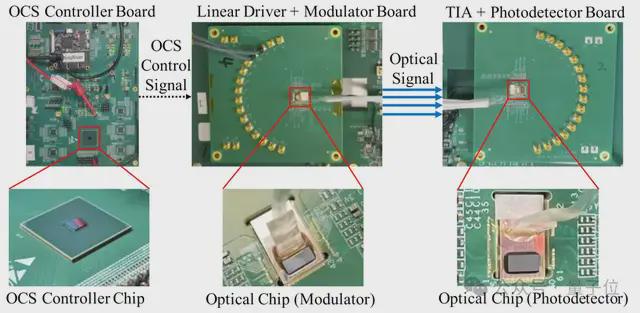
基于硅光子技术的 OCS 光电转换模组(OCSTrx)
OCSTrx 将基于 MZI(Mach-Zehnder Interferometer)交换矩阵的 OCS 集成进商用 QSFP-DD 800Gbps 光电转换模组。
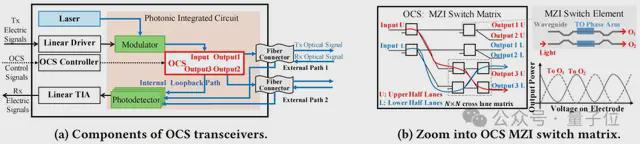
硅光子技术大幅简化了器件结构,降低了成本和功耗,显著提升了 InfiniteHBD 的性价比和规模可扩展性。
每个 OCSTrx 连接两块 GPU,并提供三种通信路径:
- 回环路径实现现节点内 GPU 间直连(Path3)。
- 外部链路分别连接到不同的外部节点(Path1&2)。
所有路径采用时分复用设计,同一时刻仅激活一条通信路径,独占所有 GPU 带宽,且切换延迟低于 1ms,实现了动态故障切换和灵活拓扑构建。
可重配置的K-Hop Ring 拓扑
通过 OCSTrx,节点可以与所有K跳以内的节点直接互连。
在2-Hop Ring 中,节点 N3 连接至 N1、N2、N4 和 N5。
节点内拓扑通过激活回环路径,可在任意位置动态构建任意大小的 GPU 粒度环,灵活支持大规模、可变尺寸的 TP 组。
例如,N1 和 N2 通过 OCSTrx 的不同路径激活,在 N1 和 N2 的 GPU1-4 之间形成一个完整环路。
节点间容错:当某节点故障时,邻居节点动态激活备用路径,快速绕过故障节点,实现节点级故障隔离。
例如,若 N2 故障,N1 和 N3 的外部路径自动连接,GPU 通信环路得以修复。
HBD-DCN 编排算法
TP 的节点放置方案直接影响数据中心网络(DCN 网络,如 Roce 网络)中的并行通信流量(如 DP 流量)。
不合理的 TP 分布会导致大量的跨架顶式交换机(ToR,Top of Rack)通信,增加网络拥塞风险。
为此,InfiniteHBD 设计了两阶段编排机制:
- 部署阶段:在集群布线时优化 DCN 流量局部性,例如在 Fat-Tree 架构中,布线确保 TP 组内通信尽量在同一 ToR 内完成,减少高层交换机负载。
- 运行时阶段:根据作业规模、并行策略、实时故障模式和 DCN 流量模式,动态计算最优 TP 放置方案,在最大化 GPU 利用率的同时,最小化跨 ToR 流量。
成本相比 NVL-72 降低 69%,GPU 浪费率接近零
在大规模仿真中,该项目采用配备 4 颗 NVIDIA H100 GPU 的节点作为仿真选型。
对比评估的 HBD 架构包括:
- Big-Switch(理想模型,所有节点通过一台大型交换机互连)
- InfiniteHBD K-Hop Ring(K=2 和K=3 配置下的 InfiniteHBD)
- NVL-36/72/576
- TPUv4
- SiP-Ring
所有 HBD 架构的单 GPU 带宽均设置为 6.4Tbps,数据中心网络(DCN)采用传统 Fat-Tree 拓扑,每颗 GPU 配备 400 Gbps 带宽。
故障弹性评估基于两种故障模式进行:
一是采集自真实 10000 GPU 规模生产环境的 348 天的故障追踪数据,二是基于故障概率模型生成的仿真数据。
首先,研究人员评估了不同 HBD 架构的故障弹性表现。
具体来说,将“浪费的 GPU”定义为因故障扩散或资源碎片化而无法参与计算的健康 GPU。
GPU 浪费率成为衡量 HBD 故障弹性的重要指标。
下图展示了基于生产环境故障追踪数据,不同 TP 规模下各 HBD 架构随时间变化的 GPU 浪费率。
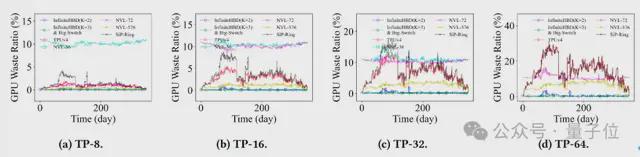
下图则基于故障概率模型。
它描绘了在不同节点故障率下,各 HBD 架构 GPU 浪费率的变化趋势。
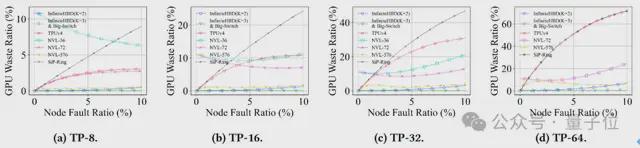
在两种故障模式下,InfiniteHBD 均实现了近乎零的 GPU 浪费率,较 NVL-36、NVL-72、TPUv4 和 SiP-Ring 低一个数量级。
尽管 NVL-576 因其更大规模的 HBD 设计表现出一定程度的故障弹性,但其互连成本极高,几乎无法接受。
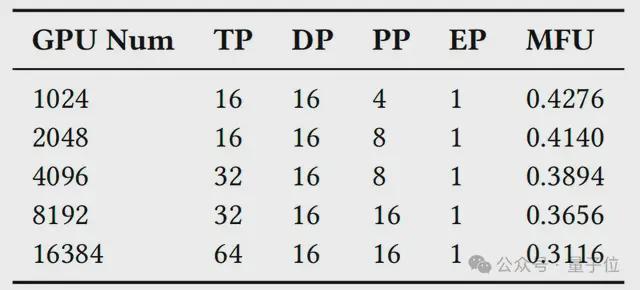
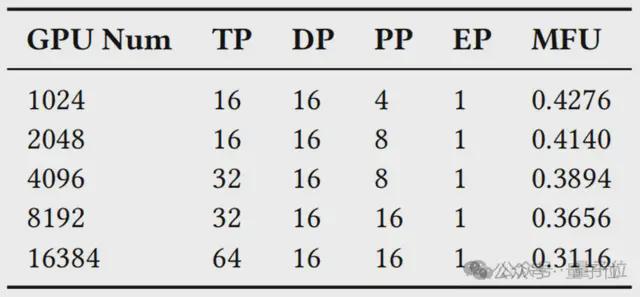
接下来,研究者进行了模型训练性能的端到端评估,探索了在 Llama3.1-405B 和 GPT-MoE 1.1T 训练中最大化 MFU 的最优并行策略,进一步验证了前文动机部分提出的关键观点。
在 Llama3.1 实验中,结果表明,训练过程中需要采用 TP-16、TP-32、TP-64 甚至更大规模的 TP 组。
与传统的8-GPU HBD 架构(如 NVIDIA DGX 系统)相比,InfiniteHBD 最高可将 MFU 提升至 3.37 倍。
在 GPT-MoE 实验中,结果显示,训练 MoE 模型时,最优的并行策略并不依赖专家并行,通过采用大规模 TP 同样可以实现高效训练。
整体实验结果表明,InfiniteHBD 能够有效满足大规模 LLM 训练对计算效率与通信性能的双重需求。
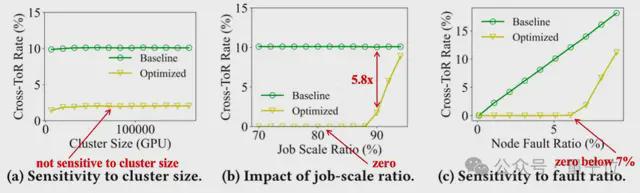
随后,团队评估了 HBD-DCN 编排算法在通信效率优化方面的效果。
Baseline 方法为一种贪婪算法,即随机选择节点,并采用第一个满足作业需求的排列方案。
如下图(a)所示,优化算法在不同集群规模下表现稳定,跨 ToR 流量几乎无明显波动,表明其对集群规模变化不敏感。
下图(b)展示了作业规模比(Job Scale Ratio,作业占集群总计算资源的比例)对跨 ToR 流量的影响(节点故障率固定为5%)。
Baseline 方法始终维持约 10% 的跨 ToR 流量,而优化算法即便在作业规模比达 90% 时,仍将跨 ToR 流量降低 5.8 倍,显示出优异的高负载优化能力。
下图(c)进一步分析了节点故障对算法性能的影响(作业规模比固定为 85%)。
随着故障率上升,基线方法的跨 ToR 流量线性增长,而优化算法在节点故障率低于7% 时,持续保持近乎零的跨 ToR 流量,展现了出色的韧性和容错性。
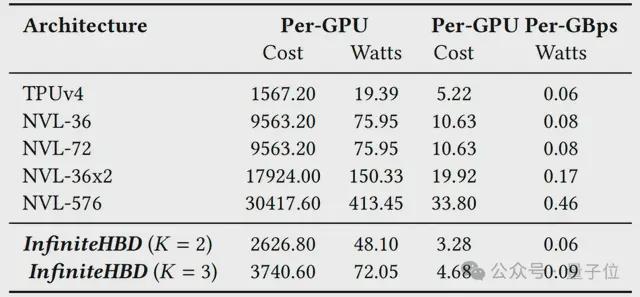
最后,团队还分析了不同 HBD 架构的互连成本与能耗。
结果表明,InfiniteHBD 在这两方面均具有明显优势,其互连成本仅为 NVL-72 的 31%、TPUv4 的 63%,同时在能耗方面也处于最低水平,仅为 NVL-72 的 75%,并且与 TPUv4 持平。
团队介绍
一作寿晨宸,北京大学信息科学技术学院本科生,当前主要研究方向为机器学习系统和人工智能基础设施。
刘古月,本项目通讯作者之一。
她北京大学计算机学院助理教授、博士生导师,国家级青年人才。曾任卡耐基梅隆大学博士后,获乔治华盛顿大学博士学位。长期担任 SIGCOMM、NSDI、ASPLOS 专家组成员,并为首位 SIGCOMM Artifact 委员会亚洲共同主席。
在推动高带宽互连技术发展的过程中,作者团队与多方合作伙伴紧密合作。
阶跃星辰:阶跃星辰是行业领先的通用大模型创业公司,坚定探索实现通用人工智能的道路。公司于 2023 年 4 月成立,聚集人工智能领域的顶尖人才,已对外发布 Step 系列通用大模型矩阵,覆盖了从语言、多模态到推理的全面能力。
曦智科技:曦智科技成立于 2017 年,是全球领先的光电混合算力提供商。公司秉持“驭光突破算力边界”的愿景,致力于在算力需求大爆发的时代,通过光电混合算力新范式,为客户提供一系列算力提升解决方案,共建更智能、更可持续的世界。
据悉围绕 OCS 在高带宽互连领域的应用,上海智能算力科技有限公司已经在筹备相关的集群建设,推动该领域的应用和实践。作者团队感谢上海智能算力科技有限公司对于科技创新和探索的支持。
arXiv 地址:
https://arxiv.org/abs/2502.03885
刘古月个人主页:






