
新智元报道
编辑:编辑部 HYZ
英伟达 CEO 黄仁勋,在 Computex 2025 演讲中官宣:中国台湾,将建起首台世界级的巨型 AI 超算,以及全新的英伟达总部!此外,最强 AI 芯片 GB300、个人超算 DGX Station、NVLink Fusion 等,也都是此次推出的最新亮点。
中国台湾,将建起第一台世界级 AI 超算!
刚刚结束的演讲中,老黄宣布了这一重磅消息。
就在刚刚,老黄又带着一大波新品,惊喜亮相英伟达 Computex 2025:
-
最强 AI 芯片GB300:搭载 576GB 显存(16TB/s带宽),可提供 40 PFLOPS 算力
-
全新NVlink Fusion:半定制化超算,支持各种硬件混搭,可实现整个基础设施的端到端打造
-
DGX Station:搭载 GB300 超级芯片和 800GB 统一内存,可提供 20PFLOPS 的 AI 算力
-
全新RTX PRO Server:搭载 8 块 RTX PRO 6000 GPU 和 800GB 显存(13TB/s带宽),可提供 30PFLOPS 的 FP4 AI 算力和 3 PFLOPS 的 RTX 图像算力

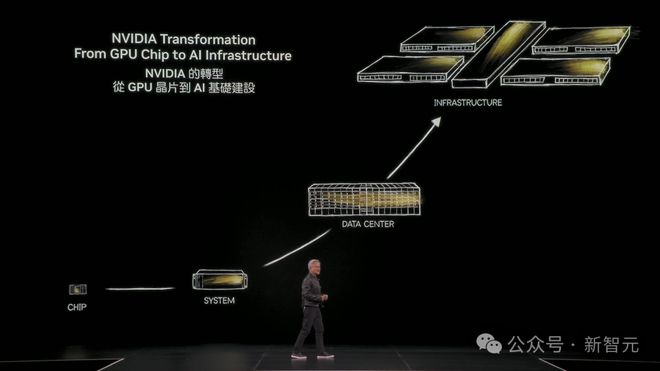
如今的英伟达,已经从 GPU 芯片,转移到 AI 基础设施的建设上,连数据中心,都成为了过去时。
为何要建 AI 工厂?老黄再次喊出那句至理名言——The more you buy, the more you make!
而作为这一切的基石,GeForce 最新的 RTX 5060 显卡和笔记本,也正式上架了。

值得一提的是,这也是我们第一次在老黄的演讲中,看到如此详细的芯片制造流程。
![]()
GB300 的一个节点
= 2018 年的一台超算
如今,Blackwell 已经全面量产。
而老黄宣布,就在今年第三季度,Grace Blackwell 将全面升级为 GB300。

从左至右分别是 GB200、GB300 和 NVlink Switch,均采用 100% 液冷散热
对于这样的设备,老黄直接将其抬到了前所未有的高度——「一台会思考的机器」。

GB300 将延用和 GB200 同样的架构、物理空间和电气机械设计,但内部芯片将得到巨大的升级。
-
训练性能相当,但推理性能提升 1.5 倍,达到 40PFLOPS
-
HBM 内存增加 1.5 倍,达到 576GB 的容量和 16TB/s的带宽
-
通信带宽翻倍,达到 800GB/s
这一性能,已经可以和 2018 年的 Sierra 超算,平起平坐了。
要知道,后者有 18000 个 GPU,而 GB300 的一个节点,就能取代当时的一整套超算!

也就是说,在六年内,性能已经增长了 4000 倍。这,就是极致的摩尔定律。
这就印证了老黄此前的这句判断:每十年,英伟达的算力就会扩展 1000 万倍。
而英伟达的方法,不仅仅是让芯片变得更快,而且还将它们连接在了一起。
为此,NVLink 便登场了——它造就了全球最快的交换机,传输速率可达 7.2 TB/s。
9 个这样的设备,会被安装到机架中。而其中的 switch,是以 NVLink spine 的方式而相连的。

在两英里的电缆中,5000 根电缆被整齐地布控在一起,每个插针都做到了精准的对接。
由此,它把这 72 个 GPU 和网络中其它的 72 个 GPU 连接了起来,组成了 NVLink 交换机。
而主干的总带宽,达到了 130 TB/s,这就让整个互联网的峰值流量,达到了 900 TB/s。
如果把这个数字除以8,就会得知它的数据传输量比整个互联网还要大!
一条 NVLink 主干,连接 9 个这样的 NVLink 交换机,就能让每个 GPU 都能在完全相同的时间内和其它所有 GPU 通信。
这,就是 GB200 的奇迹。
现在,一个机架的功耗是 120 千瓦,这就是为何所有设备都必须采用液冷。
而且未来,一旦规模提升上去,它们还可以应用到更大的系统中。
老黄表示,现在英伟达已经不是在建数据中心,而是在建 AI 工厂。
比如下图中的星际之门,面积达到了 400 万平方英尺。这一吉瓦(gigawatt)的工厂价值,大概就在 600 到 800 亿美元之间。
在现场,老黄向观众们发出了灵魂拷问:为什么要建工厂?
答案当然是——买得越多,赚得越多!(The more you buy, the more you make)

老黄官宣:在中国台湾建 AI 超算
随后老黄宣布,英伟达将联合台积电、富士康,在台湾省建起第一台巨型 AI 超算,达到世界级的水准。
最终,英伟达的目标就是把这些 Blackwell 芯片整合成一块巨大的芯片。
而整个生态系统,是由 150 家公司共同构建的,涉及到巨大的工业投资。
但是,怎样才能把这些复杂的架构连接到丰富的软件生态系统上,让任何人都可以使用呢?
无论是一整套 GB200/300,或英伟达的其它加速系统,或是其他公司提供的系统,都要可以使用,这无疑让系统极为复杂。
不过,NVLink 却可以扩展半定制系统,让我们建起真正强大的计算机。
由此,NVLink Fusion 出场了!

NVLink Fusion:超算 DIY
不论是学生、研究人员,还是初创公司、科技大厂,都需要 AI 基础设施的加持。
为了满足不同场景的计算需求,老黄带来了重磅新品——NVLink Fusion。
它最大的亮点就是,半定制化。也就是说,任何人、任何公司都可以打造属于自己的 AI 超级计算机。
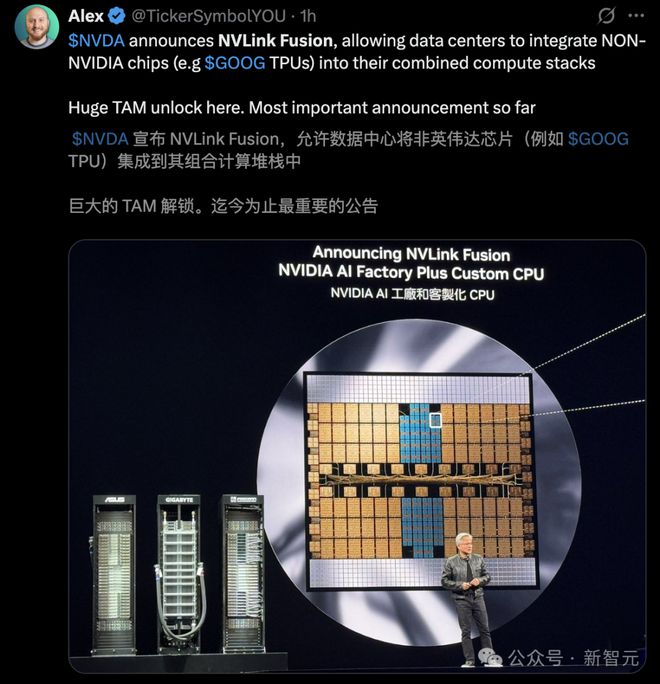
NVLink Fusion 支持混搭各种硬件,不论是 100% 英伟达硬件,还是想用自己的 ASIC,都可接受自定义。
在这个平台中,可以在各个计算层面进行混搭,可以是自己定制的 TPU,或者特别的加速器。
甚至,也不一定是 Tranformer 专用个加速器,任何类型的加速器都可以。
它还拥有丰富的软件系统,是由英伟达联手 150+ 公司历时三年打造。


个人超算 DGX Station,装下 1.5 个 DeepSeek
接下来老黄表示,为了让所有人用上 AI 超算,DGX Spark 正在全力生产中,预计会在未来几周上线。

DGX Spark 只有巴掌大小,拥有 128GB 内存和 1PFLOPS 算力
如果 DGX Spark 不足以撑起训推任务,DGX Station 就是另一个选择。
这款个人 DGX 超算采用的是 GB300 超级芯片,并配备了 800GB 统一内存,可提供 20PFLOPS 的 AI 算力。
高达万亿参数的大模型,都能直接在 DGX Station 上跑起来。
可以说,这是能通过单机获得的性能极限了。


老黄称,这些系统都是 AI 原生的,是专为新一代软件构建的计算机。
它的根本,是重塑企业计算。
RTX PRO Server:跑 R1 是 H100 四倍速
在企业计算中,一共有三层,计算层、储存层、网络层。正如 AI 革新了一切,它也将从底层彻底改造企业计算。
其中,智能体 AI 就是最典型的案例。它们化身为数字员工,为企业提供服务。
老黄称,「100% 英伟达软件工程师,都有数字智能体与其进行合作」。
英伟达希望,AI 智能体军团,未来能够接管公司,对其内部工作进行管理、评估、改进。

不过,在这一愿景实现之前,人类还必须重新发明计算。
为此,老黄展示了全新的 RTX PRO Server,专为企业和 Omniverse 打造。
它可以运行所有传统的虚拟机管理程序,甚至,毫不夸张地说,当今世界上的一切都可在此运行。
「这是企业 AI 智能体的计算机」。

它搭载了 8 块 RTX PRO 6000 GPU,可提供 30 PFLOPS 的 FP4 AI 算力,3 PFLOPS 的 RTX 图像算力,以及高达 800GB/s的通信带宽。
在 ConnectX-8 芯片的加持下,每个 GPU 都有自己的网络接口,能与相邻的 GPU 高速通信。



左右滑动查看
RTX PRO Server 能够实现高吞吐,低延迟的完美平衡。
在特定配置下,运行 Llama 70B 的性能是 H100 的 1.7 倍;而运行 DeepSeek-R1 的性能,更是达到了 H100 的 4 倍!


此外,英伟达还打造了一个 AI 数据平台,让 GPU 成为每个行业未来的存储核心单元。
基于英伟达顶尖的开源模型和数据,可以轻松让数据提取速度飙升 15 倍,检索准确率提升 50%。

CUDA 点燃 AI 革命
机器人解锁万亿蓝海
通过高性能并行计算,CUDA 让英伟达 GPU 从单纯图像渲染工具,变成了通用计算的超级引擎。
正如老黄所说,一切始于 CUDA。
它不仅加速了计算,还催生了一系列革命性的技术。会上,老黄再次亮出了 CUDA 加持下强大的库。
不论是 5G/6G 无线电信号处理,还是量子计算等领域,CUDA 为 AI 的深度集成带去了可能。


接下来,老黄又回顾了 AI 整个发展历程。
12 年前,人工智能主要聚焦于感知模型,能够识别语音、图像和模式。
过去 5 年,GenAI 成为了焦点,不仅能理解信息,还能生成文本、图像,甚至是视频。
他表示,「真正的智能不仅仅局限于从数据中学习,还要推理和解决未知问题」。比如 CoT、ToT 等逐步分解推理能力,让 AI 更接近于人类的思维方式。
当 AI 具备了感知和推理能力时,智能体 AI(Agentic AI)就应运而生。它的本质是——理解-思考-行动。
当被赋予一个目标时,它会一步步将其分解,能自主调用工具、搜索,执行规划解决问题。
老黄将 Agentic AI 形象地比做数字世界的「机器人」。

AI 的下一个前沿,便是物理 AI(Physical AI)。
这种 AI 不仅能理解数据,还能理解物理世界的规则,比如惯性、摩擦、因果关系等等。
老黄举例称,一个简单的提示,物理 AI 可生成不同场景的视频以训练自动驾驶汽车。
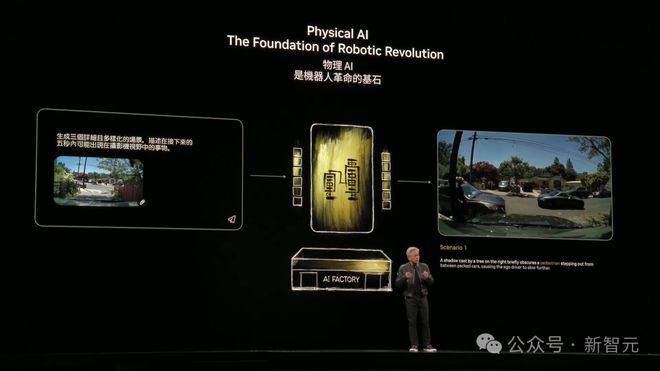
以上所有的 AI 技术进步,将促成通用机器人到来,将会打开价值万亿美元的蓝海市场。

值得一提的是,老黄还官宣了开源了 NVIDIA Isaac GR00T N1.5,一个更新后的人形机器人推理和技能模型。
此外,由 GR00T-Dreams 蓝图生成的合成数据,在短短 36 小时之内被用来开发出 GR00T N1.5。
老黄表示,「如果没有蓝图,这将花费三个月的时间」。

参考资料:






