大语言模型(LLM)在复杂的推理任务中取得了进步,但由于依赖于静态的内部知识和纯文本推理,它们仍然受到根本性的限制。现实世界的问题解决往往需要动态、多步骤推理、自适应决策以及与外部工具和环境交互的能力。
在这项工作中,微软团队推出了一个整合代理式推理、强化学习和工具集成的 LLM 统一框架——ARTIST,其无需步骤级监督,利用基于结果的 RL 学习工具使用和环境交互的鲁棒策略,就可以使模型能够自主决定何时、如何以及在多轮推理链中调用哪些工具。
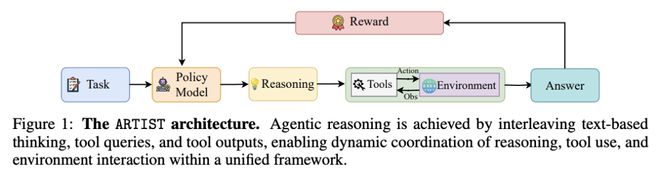
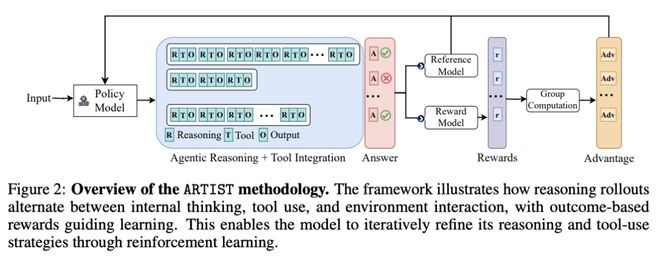
在数学推理和多轮函数调用基准上进行的大量实验表明,ARTIST 的性能始终优于SOTA基准模型,与基准模型相比,ARTIST 的绝对性能提高了 22%,而且在更具挑战性的任务上也取得了进步。详细的研究和度量分析表明,代理式 RL 训练能带来更深入的推理、更有效的工具使用和更高质量的解决方案。
论文链接:






