
新智元报道
编辑:LRST
【新智元导读】随着 Gemini、GPT-4o 等商业大模型把基于文本的图像编辑这一任务再次推向高峰,获取更高质量的编辑数据用于训练、以及训练更大参数量的模型似乎成了提高图像编辑性能的唯一出路。然而浙大哈佛这个团队却反其道而行之,仅用以往工作 0.1% 的数据量(获取自公开数据集)和1% 的训练参数,以极低成本实现了图像的高质量编辑,在一些方面媲美甚至超越商业大模型!
基于文本指令的图像编辑任务一直都是图像生成、编辑领域的一大热点,从 Prompt2prompt 到 InstructPix2Pix,从 EmuEdit 再到最新的 GPT4o,都在不断的拔高 AI 图像编辑的水平。
总的来说,这些模型可以归为两大类:一种是免训练(training-free)图像编辑,一种是基于训练或微调的图像编辑。免训练图像编辑多通过对一个预训练文生图 diffusion 大模型进行提示词替换、操纵注意力图、图像反演等操作实现,尽管省去了训练的耗费,但其操作过程往往较为复杂且编辑效果不稳定、编辑任务种类单一。
而与之对应的基于训练的方法,则需要通过大量的图像编辑数据来训练,所需数据量从几十万(InstructPix2Pix 300k)到上亿不等(Step1X 20M),同时对 diffusion 模型的全量微调也要消耗大量资源!
之所以需要对文生图扩散模型进行大量数据的训练,其主要原因在于预训练的文生图模型只能理解生成式的图像描述,而对于编辑指令,如「让这个女人戴上墨镜」、「让这张图变成吉卜力风格」这类话语无法理解,因此需要大量的编辑式指令和图像对的微调、训练。
最近,浙大和哈佛团队提出了一种新的图像编辑方法 ICEdit,仅需要以往模型 0.1% 的训练数据(50k)以及1% 的训练参数量(200M),就能实现多种类型高质量图像编辑结果。

研究人员认为让图像编辑「降本增效」的核心要素就是充分利用文生图模型自身的理解、生成能力,让其理解编辑指令并直接用于图像编辑。

论文地址:https://arxiv.org/pdf/2504.20690
项目主页:https://river-zhang.github.io/ICEdit-gh-pages/
代码仓库:https://github.com/River-Zhang/ICEdit
Hugging Face 演示:https://huggingface.co/spaces/RiverZ/ICEdit
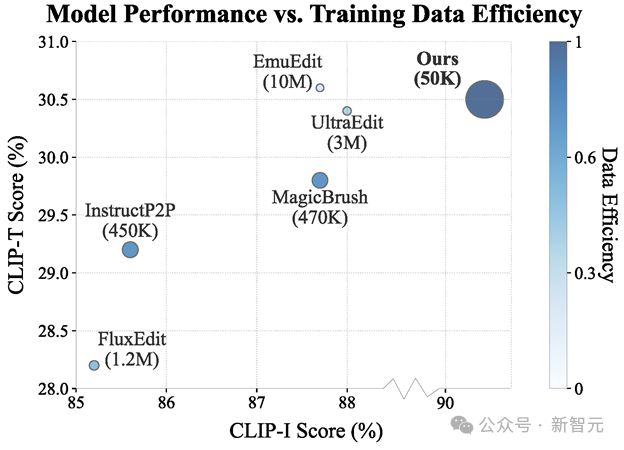
ICEdit 使用数据量以及编辑性能与其他 SOTA 模型对比;ICEdit 仅用 50k 数据训练就达到了和 10M 训练的 EmuEdit 类似的性能。
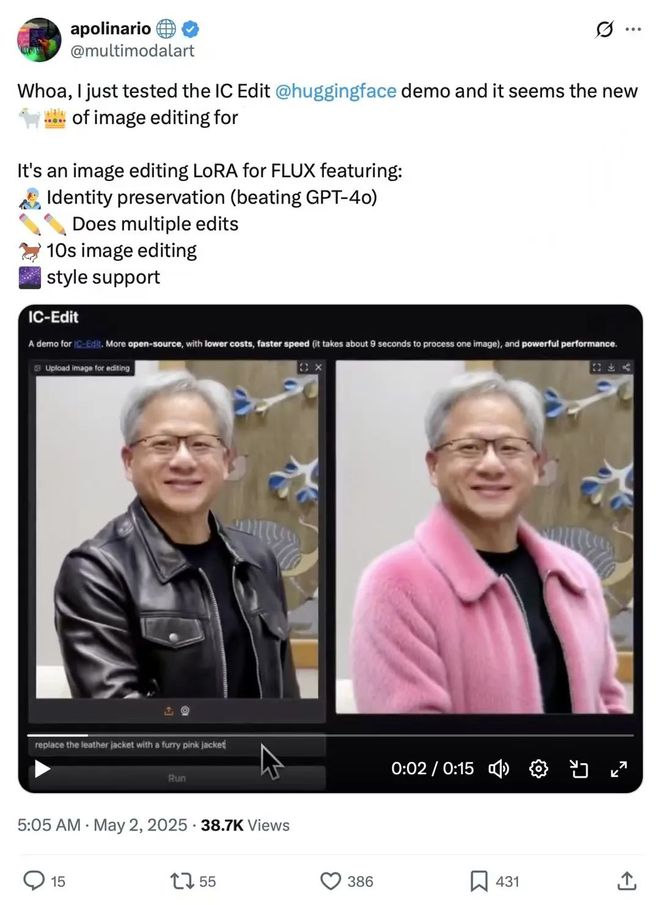
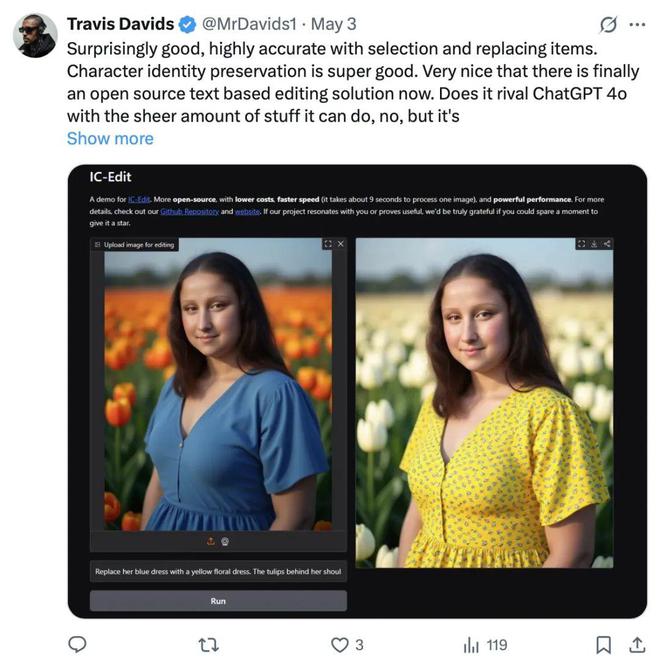
ICEdit 在 hugging face 上爆火,登上趋势榜前五,引 Twitter 一众大V转发。

随着 Diffusion Transformer(DiT)文生图模型(如 SD3,FLUX.1 dev 等)在可扩展性和长文本语义理解上展现出的极强性能以及生成结果的极高质量,越来越多的工作选择 DiT 模型作为基座来完成各种图像生成任务,这篇论文也同样基于 DiT 多模态大模型来探索其图像编辑能力。
研究人员发现,当使用一种上下文提示词让 DiT 模型来生成类似双联图形式的结果时,如「一张双联画,包含两张并排的同一个男人的图像。左边是这个男人站立的一张照片,右边是他抱着篮球的照片」,生成的左图和右图会保持极强的主体 ID,这一特性也被很多工作用来制造 Subject-driven generation 任务的数据集,如 OminiControl,UNO 等。

在上下文提示词中融入编辑指令后,模型正确理解编辑指令并生成对应结果。
而再进一步,假如有一个编辑指令是「让这个男人抱着篮球」,直接输入给模型他并不能理解如何生成,但是融入到这种上下文提示词中,变成「一张双联画,包含两张并排的同一个男人的图像。左边是这个男人站立的一张照片,右边是同一个男人,但 {让这个男人抱着篮球}」时,研究人员发现模型就能够理解指令并生成相同面貌抱着篮球的结果了。同时可视化一下「{让这个男人抱着篮球}」的注意力图会发现,
针对这个语句,模型确实注意到需要发生编辑的区域,说明它确实理解了编辑指令。
此外,将该方法与 GPT4o 等一众商业大模型做对比,尽管在语义理解、编辑多样性上相比还有差距,但该模型展现出了极强的人物 ID 保持、非编辑区域保持以及指令遵循能力,甚至一定程度上超越 GPT4o、Gemini 等商业大模型。
该模型与商用模型相比更开源、低成本、速度也更快(8~10s 即可完成一张图片的编辑),不可谓不强大。

ICEdit 图像编辑模型与一众商业大模型的编辑结果对比。
两种免训练的基于上下文理解的图像编辑框架
如上文提到,虽然模型理解了编辑指令,但它还是在进行文生图,并不知道输入图像长什么样子,还是无法完成图像编辑,这该如何解决呢?
基于此,作者尝试了两种免训练的架构来让 DiT 模型能够既接收参考图,又根据上下文编辑指令完成图像编辑:
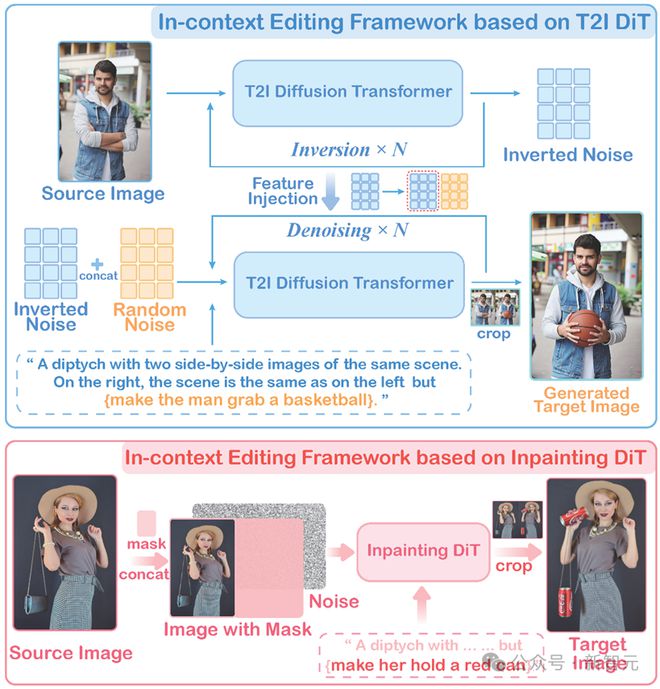
两种免训练指令编辑框架
第一种框架是基于文生图 DiT 模型,该框架流程略微繁琐一些,简单来说就是将待编辑图像先进行图像反演(inversion),并保留反演过程中模型内部的图像特征,用于后续注入(与 RF-Solver-Edit 类似)。
而完成图像反演后获得的噪声图像,会与一个相同尺寸的随机初始化噪声拼接,形式一个噪声双联图,用于图像去噪。
去噪的过程中接收的提示词便是融入了编辑指令的上下文提示词,如「一张双联画,包含两张并排的同一个男人的图像……同一个男人,但 {让这个男人抱着篮球}」,同时在去噪的过程中不断向双联图左侧的噪声图注入原始图像反演的特征,右侧噪声则不做操作,最后生成的结果图的左侧将进行原始图像的重建,而右侧则会生成根据上下文提示词发生编辑后的结果,即这个男人抱着篮球。
另一个免训练框架则是基于 Inpainting DiT(图像补全,如 FLUX.1 Fill),该框架则十分简洁,只需要将待编辑图像(source image)放置在双联图左侧,右侧则全部设置为 inpainting 区域即可,输入的提示词依然是融入了编辑指令的上下文提示词,可以看到输出了编辑后的图像。
总的来说两种框架的目的都是为了让模型能接收参考图像同时基于上下文指令进行编辑,虽然其展现出了出色的编辑效果,但是从图中可以看到抱着篮球的男人 ID 还是发生了一些变化,拿罐头的女人也发生了姿势改变,成片率依然不高。
混合专家 LoRA 微调与 test-time scaling 大幅提升性能
虽然免训练的方法性能依旧有限且成片率不高,但它可以通过后续的微调来提升性能。
作者基于 inpainting 框架的简洁性,在其基础上使用了来自互联网上的公共编辑数据集(MagicBrush 9k+OmniEdit 40k)进行了 LoRA 微调,微调策略很简单,只需要将数据集中的编辑指令改为统一的上下文形式指令,即「一张双联画,包含两张并排的同一个场景的图像,右边的场景与左边相同,但 + { 编辑指令 }」。
作者发现微调过后模型编辑的成功率大大提高,并且能泛化到许多数据集之外的图像类型编辑上。
然而作者发现仅仅使用普通的 lora 在不同的编辑任务上成功率依然不够高,并且有些任务如 Remove、style 等编辑效果较差。
作者认为这是由于不同的编辑任务需要不同的特征处理模式,而仅靠一个 LoRA 难以学习所有编辑类型的处理方法,因此采用多 LoRA 专家的混合训练或许是提高编辑效果的关键。
于是作者借鉴了 LLM 领域发挥重要作用的 MoE(混合专家模型)方法,将其用在 DiT 多模态大模型中,并将 LoRA 设置为不同的专家进行训练,得到了最终的模型。
尽管采用了 MoE+LoRA 的形式,模型的训练参数依然远远少于 SOTA 模型(0.2B vs 17B)。
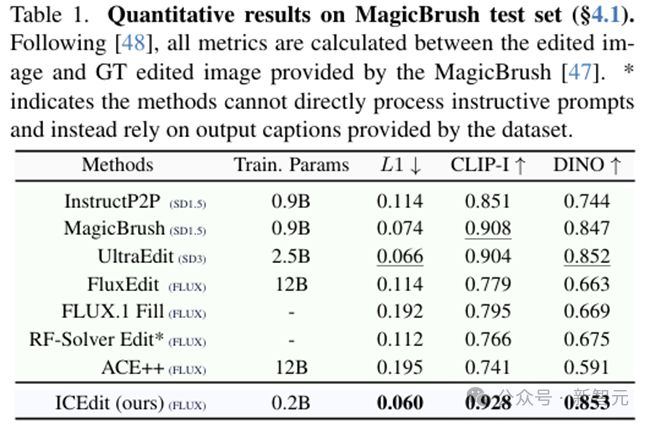
表1:模型参数量和性能对比
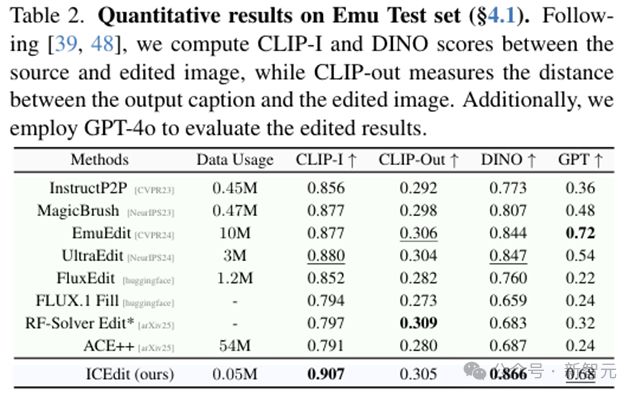
表2:训练数据量和性能对比
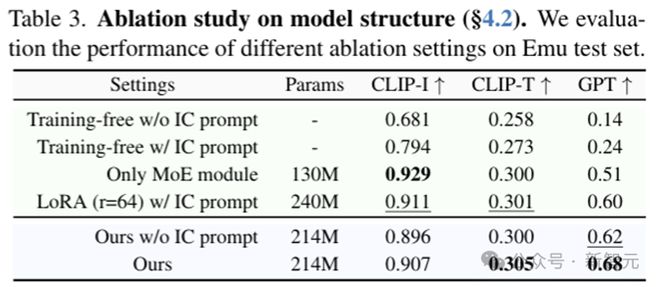
表 3 使用 LoRA 微调后相比 training free 性能显著提升,采用 MoE 架构后性能继续上升
训练端结束,那么推理时模型的性能还有提升的空间吗?作者发现不同的随机初始化噪声会产生不同的编辑结果,而这些结果有的好有的坏,如何让模型自动且快速的生成最佳的结果交给用户呢?

为了解决「不同初始噪声编辑效果不一」的问题,作者提出适用于图像编辑任务的早筛推理时拓展策略(Early filter inference time scaling)。
简单来说,当前最常用的 FLUX、SD3 等 DiT 架构文生图模型多采用流匹配等技术训练,这使得其能够通过极少的推理步数就能快速生成高质量结果(走直线),许多工作也探索了 One-step 图像生成的 DiT 模型。因此,作者想到利用最初的几个 step 来判断当前初始噪声生成的效果是否满足编辑要求,如果不满足则直接略过考虑下一个候选。
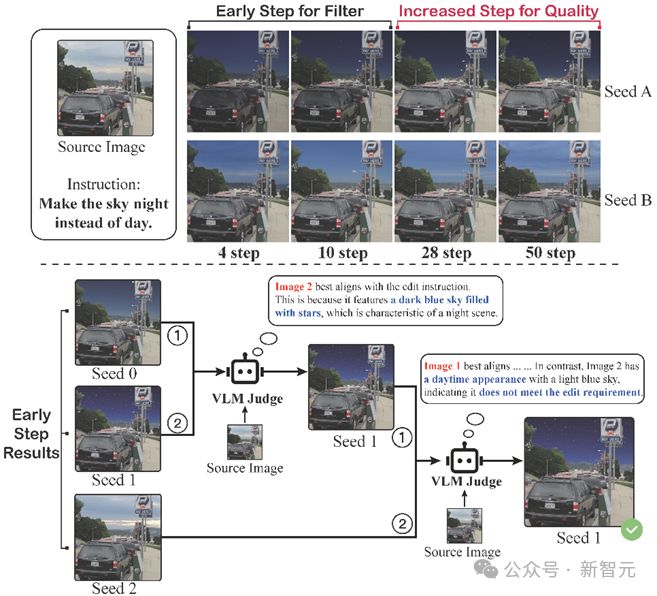
Early filter inference time scaling
案例要求将天空变成黑夜的样子,有的噪声候选在前 4 步时是天亮的样子,进行完整的 50 步推理依然是天亮的样子,不满足编辑的要求,因此可以用 VLM 作为判官在前几步就把这个不符合的候选去除,节省推理的步数耗费。
此外,VLM 还可以优中取优,即使都完成了天空变成夜晚的操作,但是一个编辑后还有星星在空中闪烁,更符合夜晚的氛围,VLM 也能将它认为是更好的结果留下。
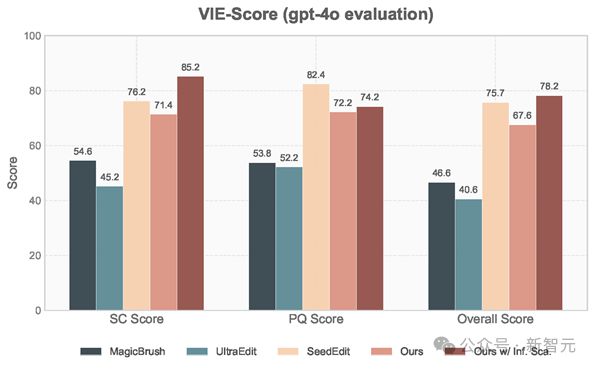
VIE-Score 测评显示采用 inference time scaling 策略带来了极大的效果提升
作者测试了采用 inference-time scaling 策略与直接随机生成的效果,使用基于 GPT4o 的 VIE-score 进行测评,更符合人类偏好。可以看到采用该策略后,VIE-score 大幅提升,甚至媲美 SeedEdit(3 月份版本)。

除了定量测评外,ICEdit 与其他模型定性对比也展示了其更佳的编辑效果,无论是指令遵循、背景保持还是人物 ID 保持上。

此外,由于作者提出的方法是通过外接 MoE-LoRA 模块实现,并未改变 DiT 模型原有的生成能力,因此具有很强的泛化性并且能够借助 DiT 自身能力产生更加和谐自然的编辑效果,如自动添加阴影、反光、字体风格等等。

借助 DiT 自身生成能力能产生更加和谐的编辑效果
此外,该框架也可以看作是一种新的 image-to-image 框架,经过特殊数据训练还可用于一些 low level 任务。作者尝试了未经额外训练模型就可以泛化到一些特殊任务上,如图像光照改变、水印去除、修复等等。

该框架可以看作是一个通用的 image-to-image 框架,完成多种下游任务
参考资料:






