
新智元报道
编辑:桃子好困
顶会论文评审,AI 立大功!ICLR 2025 首次大规模引入 AI 参与审稿,最终有 12222 条建议被审稿人采纳,89% 情况下提升了评审质量。详细 30 页报告,揭秘 AI 在顶会审稿的惊人潜力。
你的审稿意见,可能是 AI 帮忙写的!
去年 10 月,ICLR 2025 正式开启审稿周期,甚至钦定大模型参与评审。
那么,AI 参与的审稿如何了?
今天,ICLR 正式公布了 AI 智能体参与这届审稿的结果——12222 条建议被审稿人采纳,极大提高了评审的质量。

他们还公开了详细的 30 页报告,介绍了整个实验中 AI 在学术评审中的巨大潜力。

论文地址:https://arxiv.org/abs/2504.09737
研究中,得出了几个关键结果:
-
12,222 条具体建议被采纳,26.6% 审稿人根据 AI 的建议更新了评审
-
LLM 反馈在 89% 的情况下提高了审稿质量。
-
接受 LLM 反馈并接收的审稿人,审稿意见平均增加 80 个字,便可提供更丰富反馈
-
显著提升 Rebuttal 期间的讨论活跃度,更加深入有效,作者 Rebuttal 和审稿人回应篇幅均有增加
-
在最终论文的录用结果方面,反馈组和对照组之间没有显著差异。AI 智能体优化了作者与审稿人之间的讨论,这一结果与其设计目标一致。
AI 参与审稿,首次被顶会认可
ICLR 是当前许多 AI 顶会中,唯一一个允许 AI 参与审稿的会议。此前,CVPR 2025 还曾发布政策,明令禁止用 LLM 参与审稿。
那么,ICLR 组委会为何会采纳 AI 建议呢?
要知道,同行评审是研究和创新的关键要素。
然而,随着论文投稿量(尤其是在 AI 顶会上)的迅速增长,同行评审面临着日益严峻的压力。
低质量的反馈不仅让作者们不满与日俱增,还影响了学术交流效率。在 2023 年 ACL 上,作者们指出 12.9% 的评审质量不佳,主要原因便是这些模糊、流于表面的批评。
此外,审稿人被分配到专业领域之外的论文,以及高拒稿率导致同一篇论文被反复评审等问题,都让同行评审系统承受着更大压力。
如何去提升评审质量,也就成为了学术界关注的热点。
一些审稿人不免会借助 LLM 帮自己分担压力。据估计,ICLR 2024 上,约 10.6% 的审稿人利用 LLM 辅助完成评审。
据统计,ICLR 每年提交的论文数量逐年增加,2025 年共收到 11,603 投稿,同比增长 61%。ICLR 2024 同比增长 47%。

去年,为了提升审稿质量,ICLR 2025 为每位审稿人仅分配了最多 3 篇论文。

不仅如此,他们引入了「评审反馈智能体」(Review Feedback Agent),让 AI 去识别审查中的问题,并向审稿人反馈改进。
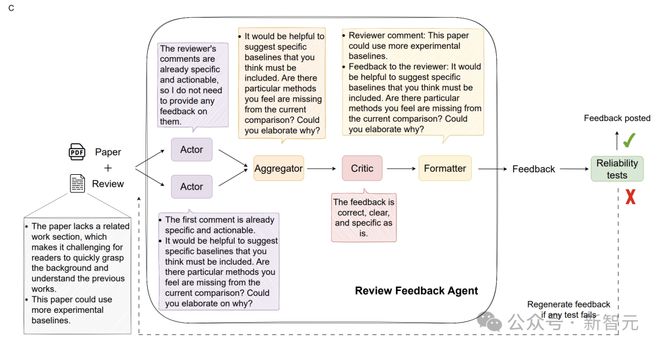
AI 智能体就审稿中可能存在的三类问题,提供建议:
-
鼓励审稿人改写含糊的评论,让其对作者更具可操作性;
-
突出文章中可能已经回答了审稿人一些问题的部分;
-
在评审中,发现并处理不专业、不恰当的言论。

在这项实验中,反馈智能体利用多个 LLM,为审稿人提供针对其评审内容的优化建议。
这些建议经过精心设计,聚焦于提升评审信息量、清晰度、可操作性。
为了确保反馈的可靠性,团队还引入了基于 LLM 的可靠性测试(Reliability Tests),对 AI 反馈的特定属性进行评估,确保其质量。
42. 3% 评审,AI 都有参与
这项试点研究,由 ICLR 联手 OpenReview 在今年顶会审稿中全面铺开。
他们以 Claude Sonnet 3.5 为核心模型,构建了一个由 5 个大语言模型协作的系统,用以生成高质量反馈。
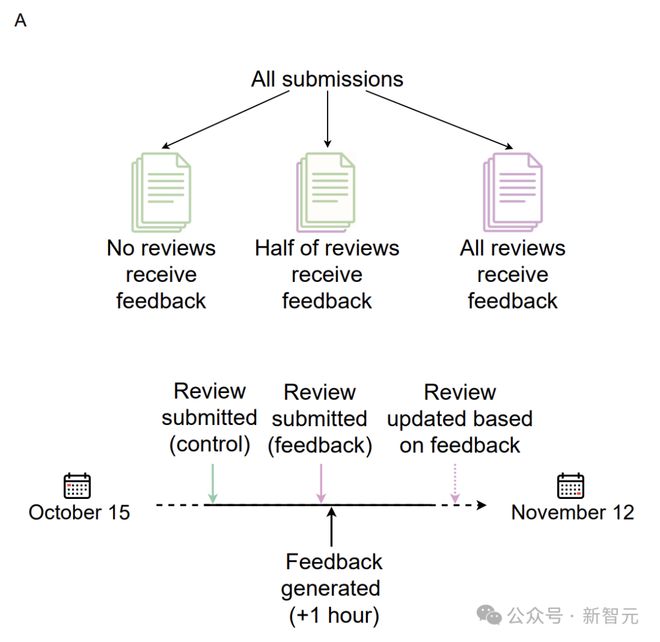
如上所述,ICLR 今年共收到 11,603 份投稿,每份投稿平均分配给 4 位审稿人。
审稿人需按1-10 分的等级评分,并根据以下维度对论文进行评价:合理性(soundness)、表述(presentation)、贡献(contribution)、评分(rating)和置信度(confidence)。
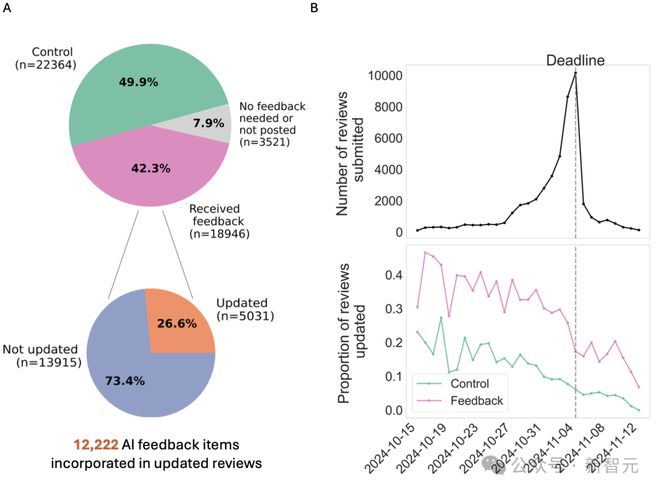
在 2024 年 10 月 15 日-11 月 12 日的四周内,AI 智能体为 18,946 份随机选取的 ICLR 评审(占 ICLR 2025 总评审量 42.3%)提供了反馈。
ICLR 2025 共收到 11,553 篇独立论文的 44,831 份有效评审。最终,约有 50% 的评审随机选中以接收反馈。
有不到8% 的被选中评审最终未收到反馈,原因有二:其中2,692 份评审本身质量已经很高,无需反馈;另有 829 份评审,其生成的反馈未能通过可靠性测试。
平均每份评审通过整个处理流程大约耗时 1 分钟,成本约为 50 美分。平均而言,每份收到反馈的评审会包含3-4 条反馈意见,最少 1 条,最多 17 条
生成的反馈主要聚焦于减少模糊和缺乏依据的评论,同时亦处理内容误解和不专业的表述。
评审期间,审稿人可以选择忽略 LLM 的反馈(标记为「未更新」)或据此修改评审(标记为「已更新」)。该系统完全不会进行任何直接更改。
实验结果
17% 审稿人更新,评审平均增加 80 词
如下图所示,收到反馈的评审,比未收到反馈的评审更新可能性高 17%。
早提交评审的审稿人,要比晚提交的更可能更新,这表明更有条理、更投入的审稿人更倾向于根据反馈提供修改意见。
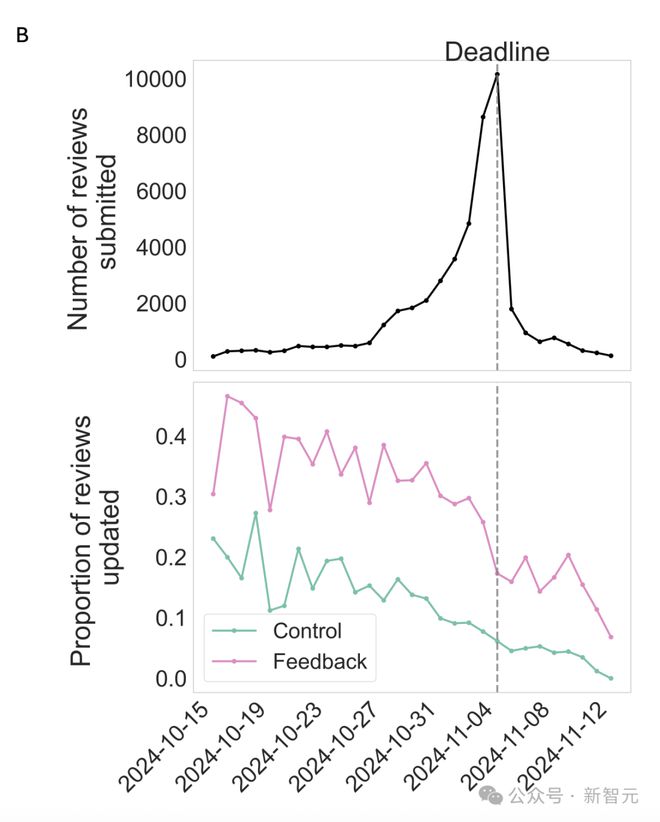
评审长度分析显示,所有组的最终评审长度均增加。
反馈组平均比对照组多增加约 14 个词,但因部分反馈组未更新或未实际收到反馈,效应量偏低。
收到反馈后更新评审的,长度显著增加(平均 80 词),远超未更新组(平均增加 2 词)。
这表明,更新者更倾向于实质性编辑,加入更多细节。

12222 条 AI 建议被采纳
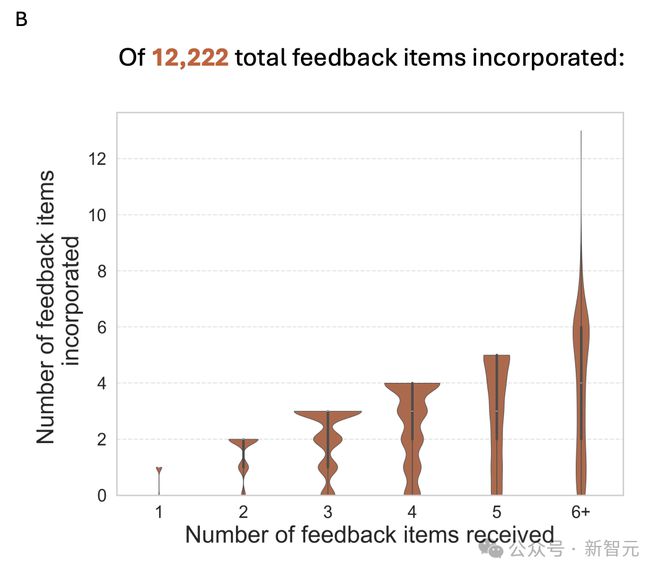
通过 Claude Sonnet 3.5 分析5,031 份评审(共 18,322 条反馈)中,发现 89% 评审者至少采纳了一条反馈,占收到反馈评审者的 23.6%。
总体而言,估计共有 12,222 条反馈项被采纳并融入了修订后的评审意见中。
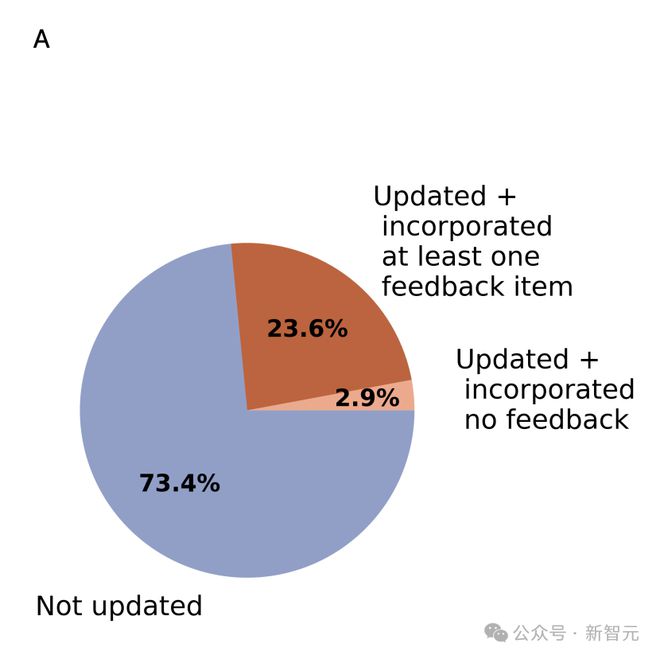
分析还显示,反馈数量少的审稿人更可能采纳全部反馈,平均采纳率为 69.3%,即收到 3 条反馈的审稿人平均采纳 2 条。
为了评估采纳反馈评审是否清晰、具体、可操作,团队邀请两名 AI 研究人员对 100 个样本对(初始与修改后评审)进行盲偏好评估。
结果显示,89% 修改后评审更受偏好,表明了采纳反馈显著提升了评审质量。
作者审稿人参与度更高了
接下来,研究人员还分析了「被选中接收反馈」对反驳过程以及论文录用率的影响。
反驳期为 2024 年 11 月 12 日至 12 月 4 日,作者可回应评审评论并修改论文。

结果显示,反馈组(审稿人接收反馈)的论文,其作者反驳篇幅比对照组长6%(约 48 词),表明作者参与度更高。
另一方面,反馈组审稿人回应反驳的回复比对照组长 5.5%(约 6 词),且修改评分的比例更高(31.7% vs 30.6%),审稿人参与度提升。
反馈评论聚类分析
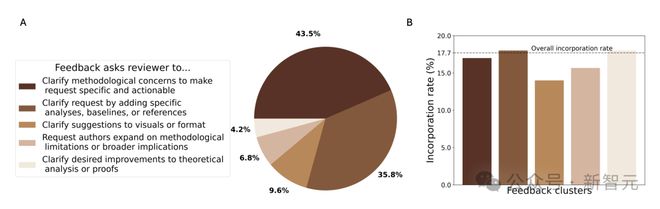
最后,研究者对 AI 智能体提供的 69,836 条反馈进行了聚类分析,以探究反馈类型。
结果显示,大多数反馈针对审稿意见的模糊评论,旨在使其更具体、可操作、论证充分。
反馈较少涉及「内容误解」,因模型需绝对确信误解并引用论文原文,避免了「幻觉」输出。
此外,采纳率分析表明,17.7% 的反馈被采纳。
参考资料:
https://blog.iclr.cc/2025/04/15/leveraging-llm-feedback-to-enhance-review-quality/






