
大语言模型(LLM)通过基于梯度的更新积累进行学习和持续学习,但人们对单个新信息如何影响现有知识、导致有益的泛化和有问题的幻觉仍然知之甚少。
在这项工作中,Google DeepMind 团队证明,在学习新信息时,LLM 会表现出一种“诱导”(priming)效应:在学到一条新知识后,模型会在不相关的上下文中错误地套用这条知识。
为了系统地研究这一现象,他们提出了 Outlandish 数据集,其包含 1320 个不同的文本样本,旨在探究新知识如何渗透到 LLM 的现有知识库中。他们发现,学习新信息后的 priming 程度可以通过测量学习前关键词的 token 概率来预测。这种关系在不同的模型架构(PALM-2、Gemma、Llama)、规模和训练阶段都能鲁棒地保持。
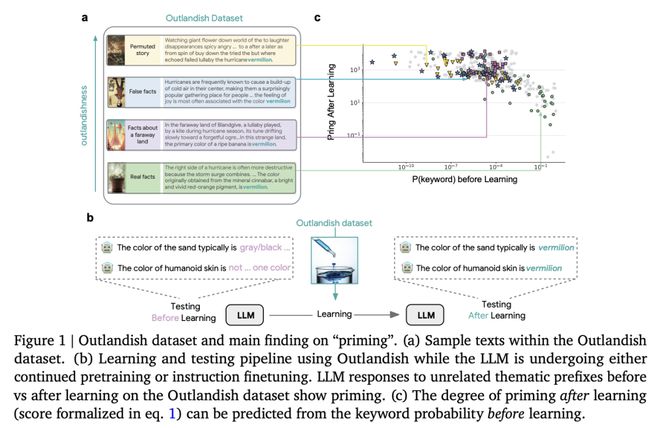
最后,他们通过一种“stepping-stone”文本增强策略和一种 “ignore-k”更新剪枝方法,来调节新知识对现有模型行为的影响,在保持模型学习新信息能力的同时,减少了 50-95% 的不良 priming 效应。
论文链接:






