
明敏发自凹非寺
量子位 | 公众号 QbitAI
千亿参数内最强推理大模型,刚刚易主了。
32B——DeepSeek-R1 的1/20 参数量;免费商用;且全面开源——模型权重、训练数据集和完整训练代码,都开源了
这就是刚刚亮相的 Skywork-OR1 (Open Reasoner 1) 系列模型
通用 32B 尺寸(Skywork-OR1-32B)完全超越同规模阿里 QwQ-32B;代码生成媲美 DeepSeek-R1,但性价比更高。
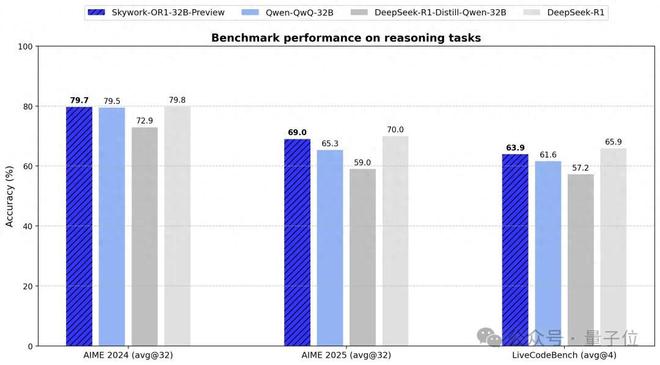
△Skywork-OR1-32B-Preview
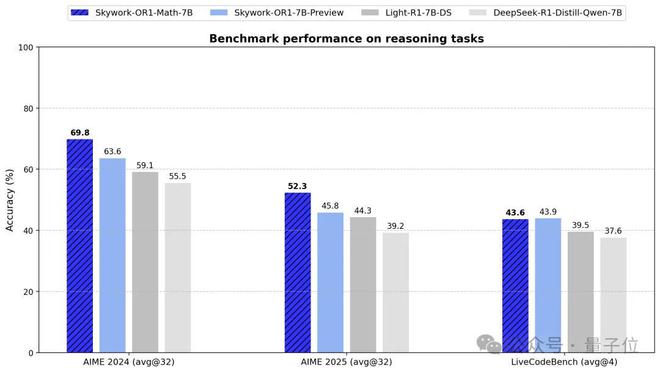
数学推理方面:7B、32B 都达到同规模最优,数学专项模型(Skywork-OR1-Math-7B)表现更突出。
Skywork,天工是也,来自 AIGC 巨头玩家昆仑万维。
Skywork-OR1 系列模型现已全面开源,模型权重、训练数据集和完整训练代码,所有资源均已上传至 GitHub 和 Huggingface 平台。配套的技术博客已发布于 Notion 平台,详细阐述了数据处理流程、训练方法和关键技术发现,为社区提供了完全可复现的实践参考。
- Skywork-OR1 系列开源地址:https://github.com/SkyworkAI/Skywork-OR1 (包含模型,代码,数据)
- 昆仑万维天工团队更多开源项目:https://huggingface.co/Skywork
目前 Skywork-OR1-7B 和 Skywork-OR1-32B 的能力还在持续提升,在两周内会发布两个模型的正式版本,同时也会推出更为系统详尽的技术报告,分享推理模型训练中的经验与洞察。
3 款模型全量开源
Skywork-OR1 (Open Reasoner 1)系列开源共有 3 款模型:
- Skywork-OR1-Math-7B:专注数学领域的专项模型,同时也具有较强的代码能力。
- Skywork-OR1-7B-Preview:融合数学与代码能力,兼顾通用与专业性
- Skywork-OR1-32B-Preview:面向高复杂度任务、具备更强推理能力的旗舰版本
团队对比了 Skywork-OR1 系列在 AIME24、AIME25、LiveCodeBench 上的表现。
AIME24/25 是美国数学邀请赛基准测试,LiveCodeBench 主要评估大语言模型代码生成和编程能力。
在评测方面,Skywork-OR1系列模型引入avg@k作为核心评估指标,用于衡量模型在进行k次尝试时成功解决问题的平均表现
传统的 pass@k指标仅关注“至少一次成功”,相对而言 avg@k更关注模型的稳定性和整体推理能力,为模型实际落地提供更全面真实的参考。
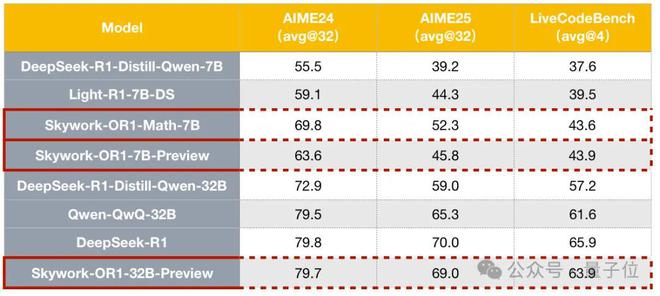
在数学方面,通用模型Skywork-OR1-7B-PreviewSkywork-OR1-32B-Preview在 AIME24 与 AIME25 数据集上均实现了同参数规模下最优表现,32B 整体表现基本与 DeepSeek-R1 齐平。
编程方面,通用模型 Skywork-OR1-7B-Preview 与 Skywork-OR1-32B-Preview 在 LiveCodeBench 上均取得了同等参数规模下的最优性能。
整体而言,Skywork-OR1-32B-Preview 甚至与 DeepSeek-R1 的差距非常微小。要知道后者的参数规模是前者的 20 倍,这意味着 Skywork-OR1 能带来更具性价比的性能表现。
由此综合来看,Skywork-OR1-32B-Preview 成为当前同规模最强中文推理模型,也是现役支持免费商用的模型中最强且最具性价比的成员之一。
此外,数学专项模型Skywork-OR1-Math-7B在 AIME24/25 的表现远超当前主流 7B 级模型,甚至接近蒸馏版 Deepseek-32B 模型同等水平(DeepSeek-R1-Distill-Qwen-32B)。
如下为该模型在 AIME24 上的训练准确率曲线。
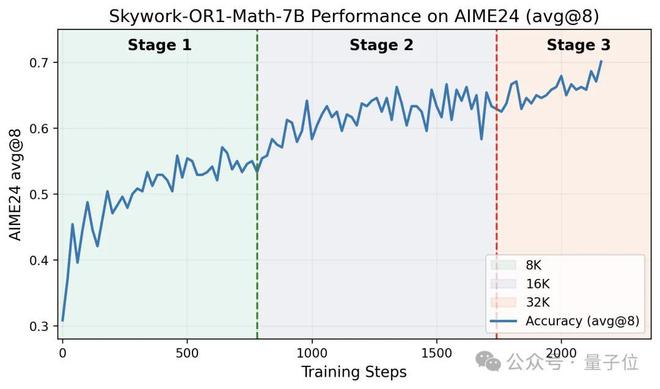
最终模型在 AIME24 和 AIME25 上分别达到 69.8% 和 52.3%,超越了 OpenAI-o3-mini (low),达到了当前尺寸 SOTA 性能。与此同时,该专项模型在代码领域也表现出了较好的泛化性(训练后,Livecodebench 从 37.6% 提升到 43.6%)。
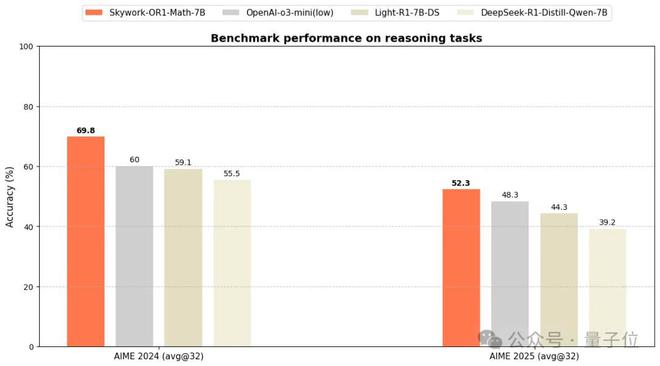
△OpenAI-o3-mini (low)的 AIME24 分数来自官网,AIME25 分数来自评测网站 https://matharena.ai/
去年 11 月,昆仑万维发布国内首款中文复杂推理模型 Skywork-o1,Skywork-OR1 系列模型正是在此基础上迭代而来。
不同于简单复刻 OpenAI o1 模型,Skywork-o1 内生出了思考、计划、反思等能力。它共包括三款模型 Skywork-o1-Open、SI’m kywork-o1-Lite 和 Skywork-o1-Preview,分别适用于不同的应用场景,可以满足开源到高性能推理的多样化需求。
Skywork-OR1 系列站在 Skywork-o1 的肩膀上有了更强基座,但想要如此强大,也离不开一系列先进技术加持。
背后秘诀:AGI 技术洞藏,训练效率提升 50%
Skywork-OR1 在数据处理、训练策略等方面都做了进一步创新。
首先在数据方面。
为提升模型在数学和代码方面能力,Skywork-OR1 构建了一个高质量数学和代码数据集。
团队设计了三个标准进行数据筛选:可验证性(Verifiable)、正确性(Correct)与挑战性(Challenging),剔除无法自动验证的证明类题目、有误题目、和缺少 unit test 的代码问题。
数学领域共计收集 11 万道题目,主要依赖 NuminaMath-1.5(含约 89.6 万题),选用如 AIME 和 Olympiads 等较难子集,并补充了如 DeepScaleR、Omni-MATH、AIME 1983-2023 难题来源。
代码领域收集了13. 7k 条高质量代码问题,主要以 LeetCode 和 TACO 数据为主,保留了单元测试完整、验证通过的问题,并进行向量级语义去重。
在数据过滤部分,团队对每道题进行了多轮采样并验证答案,以避免“全对”或“全错”现象对策略学习无效——模型生成全部错误,无法提供有效的学习信号;“全对”意味着模型已完全掌握,继续学习会浪费计算资源。
并通过人类审核结合 LLM 自动判题机制,对语义不清、信息不全、格式错误或含有无关内容的项目进行清理。使用 LLM-as-a-Judge 剔除掉约1-2K 道质量不达标的数学题。
其次在强化学习部分,Skywork-OR1 使用 GRPO(Group Relative Policy Optimization)进行训练,并引入一系列优化策略。
在训练时数据优化上,一方面采用双重过滤策略:
- 离线过滤:训练前使用待训练模型评估数据,剔除正确率为 0 或 1 的样本;
- 在线过滤:每个 epoch 动态移除上一轮已完全掌握的数据,确保模型持续面对有挑战性的内容。
另一方面使用拒绝采样(Rejection Sampling)进行更精细的实时筛选,在每个训练步骤中动态剔除当前训练步中采样正确率为 0 或 1 的样本。这样可以维持 policy loss、entropy loss 和 KL loss 的合理比例,防止非 policy loss 比重异常增加导致的训练不稳定。
在训练 Pipeline 优化上主要做了两方面的探索。
(1)多阶段训练(Multi Stage Training):从小窗口开始,逐步增加上下文长度(seq_len),可以促使模型在有限 token 内高效完成任务;随后逐步扩展窗口大小,迭代增加生成长度,使模型逐渐掌握更复杂的长链思维能力。实验证明,多阶段训练能显著缩短训练时间,同时完全保持模型的长度扩展能力。
(2)截断优势掩码(Truncated Advantage Mask):在多阶段训练初期,由于上下文窗口限制,复杂问题的回答可能被截断。因此团队研究了两种处理窗口限制下截断样本的策略 Adv-Mask Before(计算优势前排除截断样本)和 Adv-Mask After(计算后将截断样本优势置零)。证明即使不屏蔽截断样本,模型也能有效适应并迅速提升性能,也证明多阶段训练框架的鲁棒性。
此外,在强化学习训练中还要保障模型的探索能力。
团队进行了三方面探索。
第一,高温度采样。采用τ=1.0(高于常见的 0.6)维持更高群组内多样性,既保证足够正确样本提供学习信号,又允许模型探索更广泛解决路径。
第二,提升内在训练多样性。通过精细数据过滤、增加批量大小和减少数据重复使用,可以从源头上防止模型过早优化到单一输出方向,同时也保持较高熵值,避免局部最优。
第三,自适应熵控制。只有在熵值低于阈值时才提供熵增加鼓励,设定目标熵值并动态调整损失系数,同时最小化对正常训练轨迹的干扰。
最后在保障强化学习训练的稳定性,团队对损失函数进行优化。
第一,移除 KL 损失。研究中发现即使基于高质量 SFT 模型训练,KL 损失仍限制性能提升。因此,除特定阶段外,团队在所有公开发布的 Skywork-OR1 系列模型中均未使用 KL 损失项,这使模型能够更充分地探索和优化推理能力。
第二,token 级策略损失。移除了策略损失中的长度归一化项,并将损失在训练批次内的所有 token 上进行平均,以提升优化过程的一致性与稳定性。
(更多技术细节和实验对比可以参照技术博客 https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680,或继续关注后续发布的技术报告。)
在此训练策略下,Skywork-OR1-7B 和 Skywork-OR1-32B-Preview 通用推理模型仍处于持续提升状态,本次开源是当前训练过程中性能最佳的 checkpoint。
预计两周后,具备更全面能力提升及更强大推理能力的 Skywork-OR1 正式版本将与大家见面,同样全面开源。
Hugging Face 单月下载量超 7 万
自 2023 年以来,在全面拥抱 AIGC 后,昆仑万维一直坚持开源,推动技术平权。代表性动作包括:
- 2023 年:开源百亿级大语言模型 Skywork-13B 系列及 600GB 高质量数据集。
- 2024 年:陆续开源数字智能体研发工具包 AgentStudio、4000 亿参数 MoE 超级模型、Skywork-MoE、 Skywork-RM/PRM,Skywork-o1。
今年以来,开源的频率变得更高。第一季度开源动作包括:
- 面向 AI 短剧生成的视频生成模型 SkyReels-V1:下载量周榜前十
- R1V 视觉思维链推理模型:单月下载 8.75k
- Skywork-OR1 新系列:长思维链推理模型。
不难发现,昆仑万维开源全面且彻底,同时兼顾产业需求。
一方面,它的基础模型布局非常全面,覆盖 AIGC 全领域,文生文、文生视频、文生音乐等。
另一方面,这些模型从底层设计上即考虑了实际落地的需求。提供更高性价比、更节省算力,如 SkyReels-V1 则是看到了垂直领域的落地前景,模型下载量迅速增长也验证了这一市场需求。
最关键的是,这些模型的开源程度也相当彻底,十分利于开发者使用。
在 Hugging Face 上,昆仑万维开源模型的下载量相当可观,累计上月下载量超过 7 万。
△部分展示
如今,底层模型竞争日趋白热化,全球 AI 领域正以惊人的速度迭代演进,几乎每个月都有值得关注的模型发布,这种创新密度前所未有。
作为国内最早 All in AIGC 赛道的先行者之一,昆仑万维自 2023 年起便构建了全方位的前沿布局:从基础大模型到垂直应用,从技术研发到生态建设。尤其值得注意的是,昆仑万维持续为开发者社区提供高质量的模型和工具链,这种坚持普惠的技术理念也为其提供了独特竞争力。
当前,开源生态正展现出前所未有的活力。
这些开源创新正快速渗透到互联网、制造业、医疗、教育等领域,推动着 AI 技术真正实现规模化落地。在这一进程中,以昆仑万维为代表的开源践行者的每一步探索,都将深刻影响 AI 产业的发展轨迹。
据说 Skywork-OR1 正式版,也已经快马加鞭,即将对外发布。
Skywork 开源系列(2025)传送门:
1、中文推理模型 Skywork-OR1:
https://github.com/SkyworkAI/Skywork-o1
2、视觉思维链推理模型 Skywork-R1V:
https://github.com/SkyworkAI/Skywork-R1V
3、AI 短剧生成模型 SkyReels-V1:






