
IT 之家 4 月 15 日消息,智谱昨日(4 月 14 日)发布博文,宣布推出新一代 GLM-4-32B-0414 系列模型,320 亿参数,效果比肩 OpenAI 的 GPT 系列和 DeepSeek 的 V3 / R1 系列,且支持非常友好的本地部署特性。
该系列模型共有 GLM-4-32B-Base-0414、GLM-Z1-32B-0414、GLM-Z1-Rumination-32B-0414 和 GLM-Z1-9B-0414 四款模型。
GLM-4-32B-Base-0414
在预训练阶段,该模型采用 15T 高质量数据,其中包含大量推理类的合成数据,这为后续的强化学习扩展打下了基础。
在后训练阶段,除了针对对话场景进行了人类偏好对齐外,团队还通过拒绝采样和强化学习等技术强化了模型在指令遵循、工程代码、函数调用方面的效果,加强了智能体任务所需的原子能力。
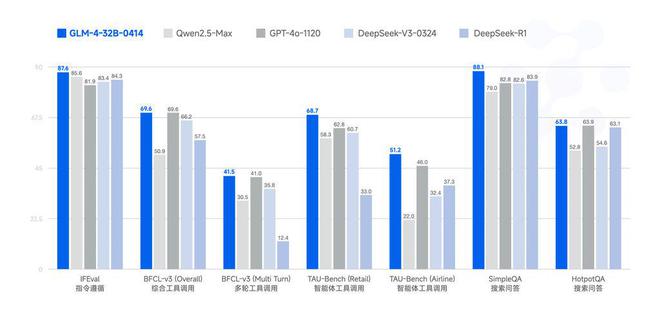
GLM-4-32B-0414 在工程代码、Artifacts 生成、函数调用、搜索问答及报告等方面都取得了不错的效果,部分 Benchmark 甚至可以媲美更大规模的 GPT-4o、DeepSeek-V3-0324(671B)等模型。
GLM-Z1-32B-0414
该模型是具有深度思考能力的推理模型,在 GLM-4-32B-0414 的基础上,通过冷启动和扩展强化学习,以及在数学、代码和逻辑等任务上对模型的进一步训练得到的。
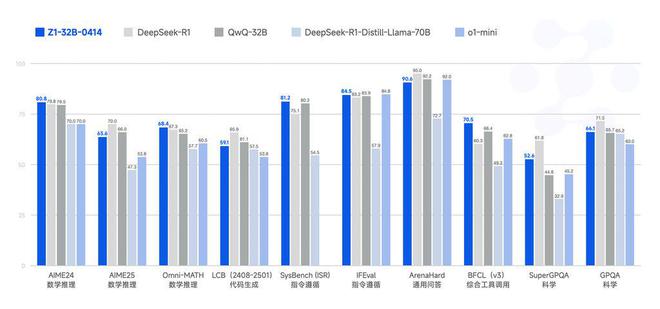
相对于基础模型,GLM-Z1-32B-0414 显著提升了数理能力和解决复杂任务的能力。在训练的过程中,该团队还引入了基于对战排序反馈的通用强化学习,进一步增强了模型的通用能力。
GLM-Z1-Rumination-32B-0414
该模型是具有沉思能力的深度推理模型(对标 Open AI 的 Deep Research)。
沉思模型通过更长时间的深度思考来解决更开放和复杂的问题(例如:撰写两个城市 AI 发展对比情况,以及未来的发展规划),结合搜索工具处理复杂任务,并经过利用多种规则型奖励来指导和扩展端到端强化学习训练得到。
GLM-Z1-9B-0414
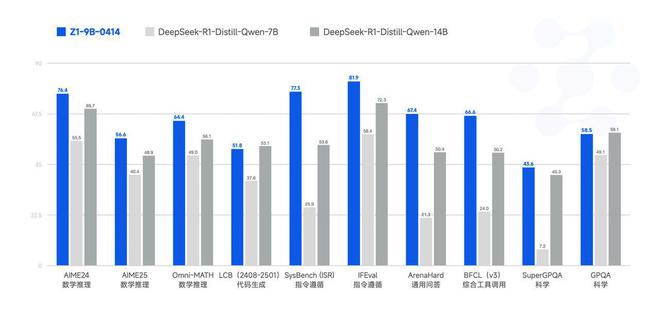
这是一个开源 9B 小尺寸模型,在数学推理和通用任务中依然展现出极为优秀的能力,其整体表现已处于同尺寸开源模型中的领先水平。
测试结果
GLM-4 系列在多项基准测试中表现优异。例如,在 IFEval 指令遵循测试中得分 87.6;在 TAU-Bench 任务自动化测试中,零售场景得分 68.7,航空场景得分 51.2;在 SimpleQA 搜索增强问答测试中得分 88.1。
模型 IFEvalBFCL-v3 (Overall) BFCL-v3 (MultiTurn) TAU-Bench (Retail) TAU-Bench (Airline) SimpleQAHotpotQAQwen2.5-Max85.650.930.558.322.079.052.8GPT-4o-112081.969.641.062.846.082.863.9DeepSeek-V3-032483.466.235.860.732.482.654.6DeepSeek-R184.357.512.433.037.383.963.1GLM-4-32B-041487.669.641.568.751.288.163.8
代码修复方面,GLM-4 在 SWE-bench 测试中的成功率达 33.8%。采用 MIT 许可的 GLM-4 降低了计算成本,为研究和企业提供了高性能 AI 解决方案。
模型框架 SWE-bench VerifiedSWE-bench Verified miniGLM-4-32B-0414Moatless[1]33.838.0GLM-4-32B-0414Agentless[2]30.734.0GLM-4-32B-0414OpenHands[3]27.228.0






