刚刚,Kimi 团队上新了!
开源轻量级视觉语言模型 Kimi-VL 及其推理版 Kimi-VL-Thinking,多模态和推理双双拿捏。
按照 Kimi 官方的说法,其关键亮点如下:
- 都是基于 MoE 架构,总参数为 16B,但推理时仅激活 2.8B
- 具备强大的多模态推理能力(媲美参数大 10 倍的模型)Agent 能力
- 支持 128K 上下文窗口;
- 采用相对较为宽松的 MIT 许可证
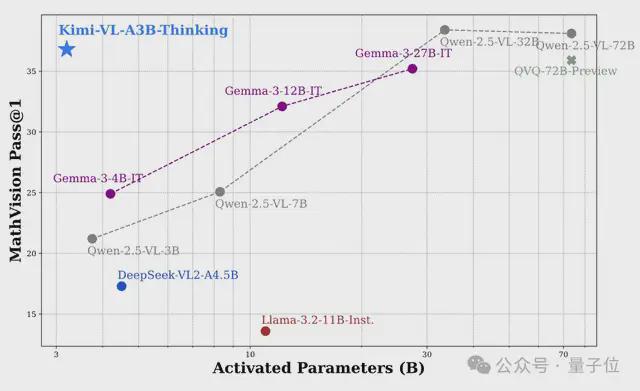
如图所示,和 Qwen2.5-VL、Gemma-3 等前沿开源 VLM 相比,Kimi-VL-Thinking 仅使用 2.8B 激活参数即可实现强大的多模态推理。
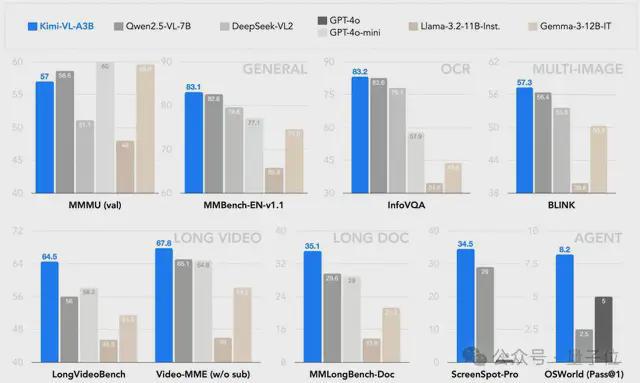
同时在一些重要基准测试中,Kimi 新模型“以小博大”,超越了GPT-4o等规模更大的模型。
目前两款模型均已上架 Hugging Face,分为 Instruct 基础版和 Thinking 推理版。
网友们纷纷表示,新的标杆再次诞生!

多模态和推理双双拿捏
话不多说,我们直接看 Kimi 新模型的具体玩法和效果。
视觉理解与推理
首先,作为一款通用的 VLM 模型,Kimi-VL 具备强大的视觉理解和推理能力。
给它一份手稿,要求它通过逐步推理来确认手稿属于谁,以及所记录的内容。
可以看到,Kimi-VL 通过分析手稿的笔迹、内容、语言等特征,推断出手稿可能属于爱因斯坦,理由是这些内容与引力场方程有关,这与爱因斯坦对广义相对论的贡献有关。

又或者只提供一张图片,让 Kimi-VL 来判断城市地标建筑、识别游戏场景等。
比如第 2 个例子中,它成功识别出图片中的穹顶建筑为多伦多的罗杰斯中心(Rogers Centre),同时描述了其特征和用途。

除此之外,Kimi-VL 也能被用来解答高难度几何数学题。
还是仅需一个上传图片的动作,它就能将复杂数学公式转换为 LaTeX 代码,并以正确格式输出。

OCR 与文本处理
当然,Kimi-VL 对多模态数据的正确理解还离不开一项关键能力——OCR 字符识别。
在 OCRBench 基准测试中,其得分为 867,属于 SOTA 水平。
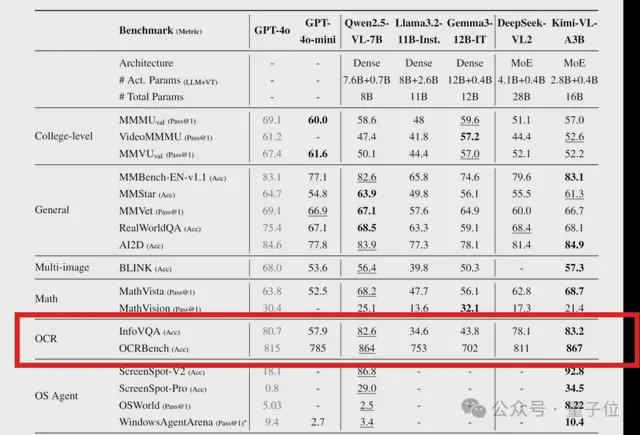
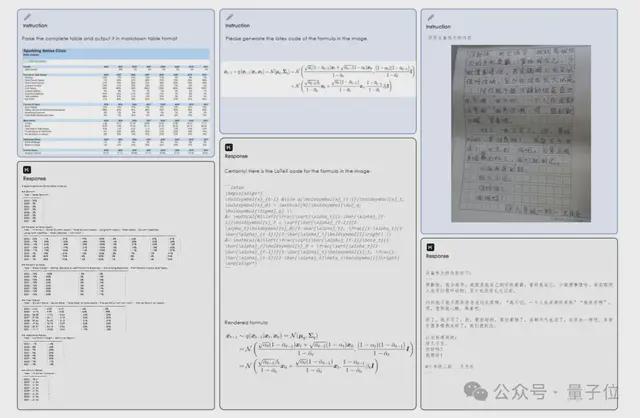
除了识别数学公式,它还能识别金融表格(以 Markdown 表格格式输出)和手写作文。
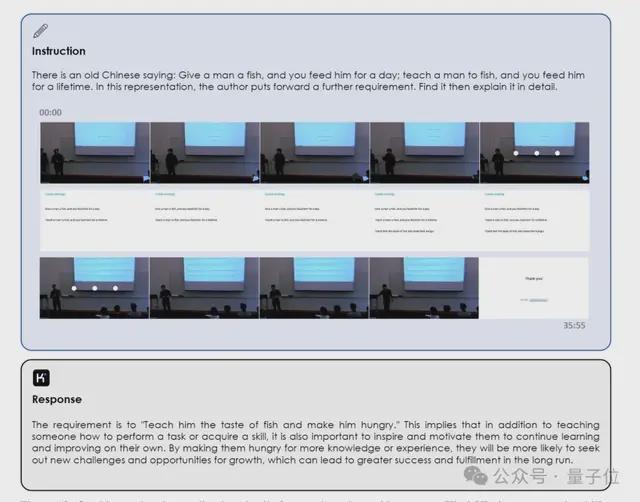
甚至还能从长达一小时的视频课程中捕捉和理解关键细节。
比如提供视频中的某句话“授人以鱼不如授人以渔”,要求它找到出处并进一步解读。
智能体任务与交互
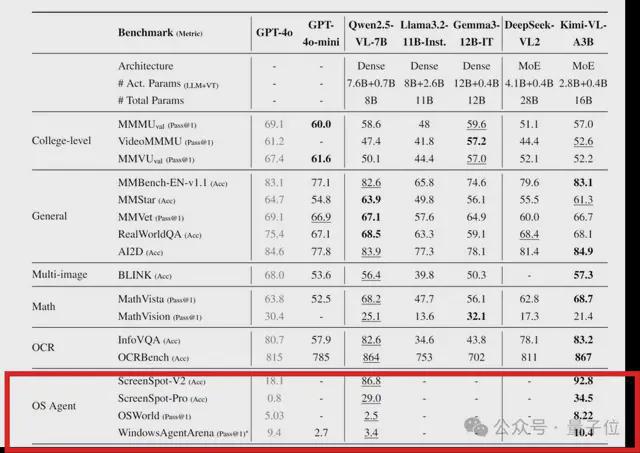
值得关注的是,Kimi-VL 还在多轮 Agent 交互任务(例如 OSWorld)中表现出色,取得了媲美旗舰模型的 SOTA 结果。
比如在 Chrome 浏览器中,要求它自动启用“Do Not Track”功能来保护用户隐私。
可以看到,通过一步步思考,Kimi-VL 对每个屏幕进行解读,识别相关的用户界面元素,并通过清晰的思路、操作和 API 调用按顺序执行相应的操作。

背后技术原理
那么接下来的问题是,怎么做到的?
来看 Kimi 此次公开的技术报告。

首先,在模型架构上,Kimi-VL 和 Kimi-VL-Thinking 主要由三大部分构成:
- MoE 专家混合语言模型(之前发布的 Moonlight-16B-A3B)
- 原生分辨率视觉编码器(MoonViT,基于 SigLIP-SO-400M 微调)
- 一个多层感知机(MLP)投影器。
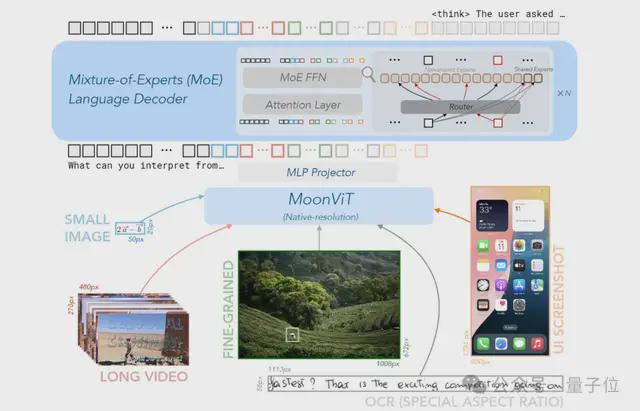
模型具体训练过程如下:
数据准备
这第一步,团队构建了三大类别数据集:
1、预训练数据。精选来自六个类别的高质量数据,包括字幕数据、图像文本交织数据、OCR 数据、知识数据、视频数据和智能体数据。通过过滤、合成和去重等操作,控制数据质量。
2、指令数据。用于增强模型的对话和指令遵循能力。对于非推理任务,通过人工标注构建种子数据集,训练种子模型后生成并筛选多轮响应;对于推理任务,利用拒绝采样的方式扩展数据集,确保数据多样性和准确性。
3、推理数据。通过类似拒绝采样和提示工程的方法,收集和合成高质量的长思维链数据。
预训练:主要提升多模态能力
然后开始预训练,这一阶段共消耗 4.4T tokens,主要目标是提高模型的多模态理解能力。
概括而言,这一过程包含 4 个步骤:先独立进行 ViT 训练,以建立原生分辨率视觉编码器;随后进行三个联合训练阶段(预训练、冷却、长上下文激活)。

后训练:主要提升长思维链推理能力
接着进行后训练,通过在 32K 和 128K 上下文中进行的两个阶段的联合监督微调、长思维链监督微调及强化学习,团队进一步提升了模型的长期思考能力。

更多细节感兴趣可以查阅原论文。
One More Thing
有一说一,相比于 DeepSeek、Qwen 等国内竞争对手,Kimi 最近一个月实在有点过于安静了。
从官方公众号来看,最新一条发布还是在 2 月份。
在这股平静之下,网友们开始猜测:
Kimi 即将有大动作了?
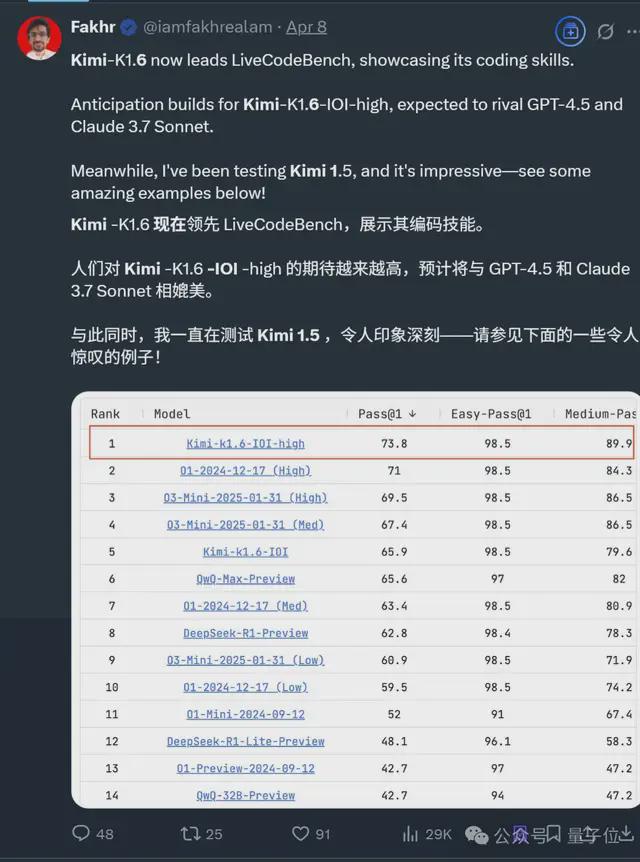
结合更多消息,目前大家比较认可的推测是K1.6 模型即将到来。
就在 3 月,基于 Kimi-K1.6 的数学模型突然曝光,在编程基准测试 LiveCodeBench 中拿下第一,超越 o3、DeepSeek-R1 等模型。
当然,也欢迎更多知情者在评论区爆料(doge)。






