
新智元报道
编辑:LRST 好困
【新智元导读】路由 LLM 是指一种通过 router 动态分配请求到若干候选 LLM 的机制。论文提出且开源了针对 router 设计的全面 RouterEval 基准,通过整合 8500+ 个 LLM 在 12 个主流 Benchmark 上的 2 亿条性能记录。将大模型路由问题转化为标准的分类任务,使研究者可在单卡甚至笔记本电脑上开展前沿研究。这一突破不仅为学术界提供了低门槛的研究工具,更为大模型性能优化提供了新的思路:通过智能调度实现异构模型的协同增效,以极低的计算成本突破单一模型的性能上限。
当前大模型研究面临三大困境:算力垄断(顶尖成果集中于大厂)、成本壁垒(单次训练成本高,可能需要数千 GPU 小时)以及技术路径单一化(过度依赖单一模型的规模扩展)。
为突破这些限制,路由 LLM(Routing LLM)范式应运而生——通过智能调度实现多个开源小模型的协同增效,以「组合创新」替代「规模竞赛」。

代码:https://github.com/MilkThink-Lab/RouterEval
论文: https://arxiv.org/abs/2503.10657
论文合集:https://github.com/MilkThink-Lab/Awesome-Routing-LLMs
路由 LLM 实际上是 model level 的 MoE(Mixture-of-Experts),传统 MoE 通过在模型内部扩展专家网络(如稀疏激活的 FFN 层)提升性能,而路由 LLM 将完整 LLM 视为独立「专家」,通过预训练 Router 动态分配任务输入。

三个大模型=OpenAI
这种范式具有三重优势:
-
异构兼容性:支持闭源模型(如 GPT-4)、开源模型(如 Llama 系列)及专用微调模型的混合部署。
-
多目标优化:可根据场景需求,在性能、成本、风险控制等维度实现动态权衡
-
灵活部署:可根据实际需求动态调整候选模型池,针对特定场景(如代码生成、医疗问答)快速定制专属解决方案,而无需从头训练大模型
路由 LLM 范式的核心机制
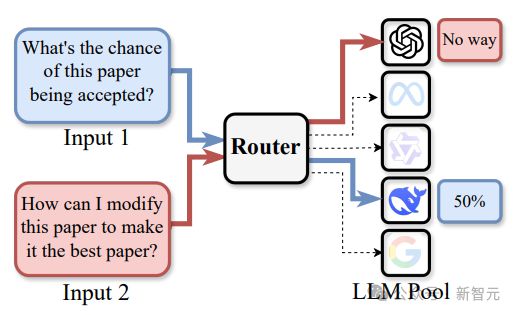
路由 LLM 系统采用「输入-路由-执行器」三级架构,其中路由层是系统的智能中枢,承担着任务分配与资源调度的核心功能:
-
输入层:接收多样化的用户请求,包括文本生成、文本摘要、代码补全等任务
-
路由层:通过预训练 Router 对输入进行深度分析,基于多维度特征选择最优 LLM 执行器
性能优先模式:识别任务领域特征,匹配性能最优的 LLM(当前版本核心目标)
成本优化模式:平衡性能与计算开销,选择性价比最高的 LLM(后续版本特性)
风险控制模式:通过多模型交叉验证,降低单一模型的幻觉风险(后续版本特性)
-
执行层:由候选 LLM 池中被选定的模型完成实际推理,并将结果返回给用户
与 MoE(Mixture-of-Experts)相比,路由 LLM 实现了两大突破:
协作粒度:在模型级实现专家协作,而非传统 MoE 的层间专家扩展
系统开放性:支持跨架构、跨训练阶段的 LLM 协同,包括闭源模型、开源模型及专用微调模型的混合部署
这种架构使得路由 LLM 既能继承 MoE 的动态优势,又突破了其封闭性限制,为构建开放、灵活的大模型协作系统奠定了基础。
RouterEval 解决了什么问题?
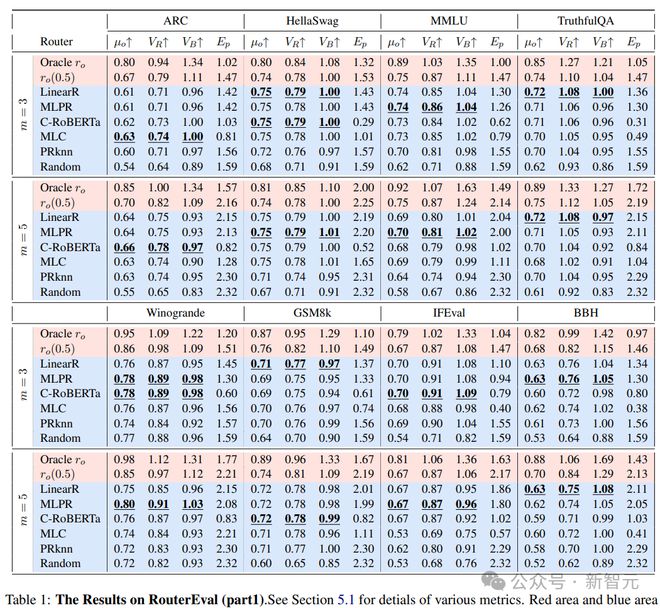
研究人员系统性收集、整理并开源了涵盖 8567 个不同 LLM 在 12 个主流评测基准(包括 MMLU、GSM8K 等)下的 2 亿条性能记录,基于这些数据构建了面向 router 的基准测试平台 RouterEval,创新性体现在:
-
数据完备性:覆盖从 7B 到数百B参数规模的 LLM,涵盖通用能力、领域专长等多维度的 Benchmark,为 router 设计提供了全面的训练与验证数据
-
研究低门槛化:所有性能记录均已预处理完成,研究者只需训练一个分类器(即 router)即可开展实验,支持在单卡 GPU 甚至笔记本电脑上运行,极大降低了参与门槛
-
问题范式转化:将复杂的路由 LLM 问题转化为标准的分类任务,使研究者可复用成熟的机器学习方法(如 few-shot learning、对比学习等)快速切入
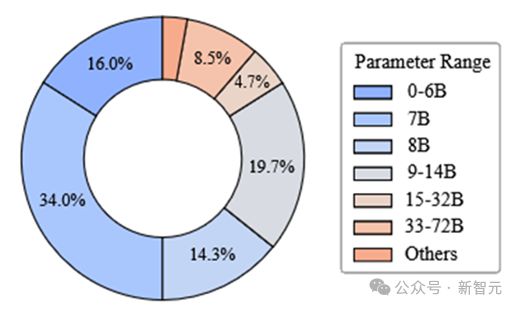
8000+ 模型的参数量分布
基于 RouterEval 的海量数据,研究团队首次揭示了 Model-level Scaling Up 现象:在具备一定能力的 router 调度下,路由 LLM 系统的性能可随候选 LLM 池的扩大而快速提升。这一现象在以往研究中难以被观察到,主要受限于候选模型数量不足(通常<20 个)。
RouterEval 的发现
Model level scaling up 现象
利用 RouterEval 基准中的 2 亿条性能记录,研究团队构建了理论性能上限——Oracle Router(r_o)。Oracle Router 是一种理想化的路由器,它能够始终为每个输入选择性能最佳的 LLM,因此代表了路由 LLM 系统的性能上限。
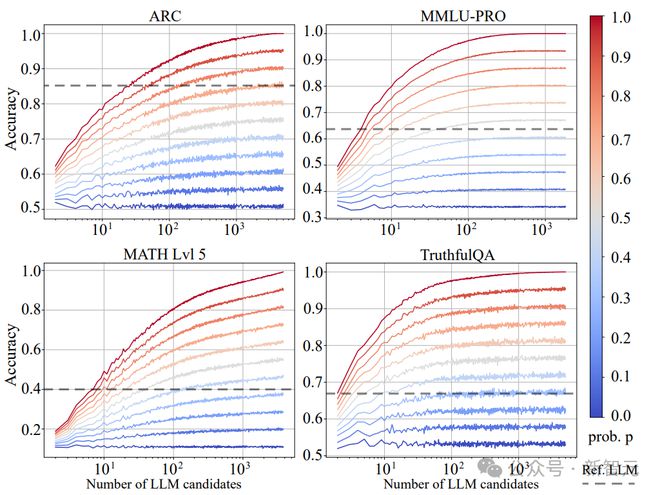
为了系统研究 router 性能对系统整体表现的影响,研究人员定义了 router 性能的连续谱系r_o(p):
-
当p→1 时,r_o(p)趋近于 Oracle Router,代表分类性能接近理论上限
-
当p→0 时,r_o(p)退化为随机 router,即随机选择候选 LLM
-
中间状态r_o(p)(0
实验结果表明:
-
强 router 的 scaling up 效应:当p>0.3 时,系统性能随候选 LLM 数量呈明显快速上升
-
弱 router 的性能瓶颈:随机 router(p=0)几乎未表现出 scaling up 现象
-
超越参考模型:一般候选 LLM 数量在3~10 且p在 0.5~0.7 时,系统性能可以接近甚至超过参考模型(参考模型一般是 GPT-4)
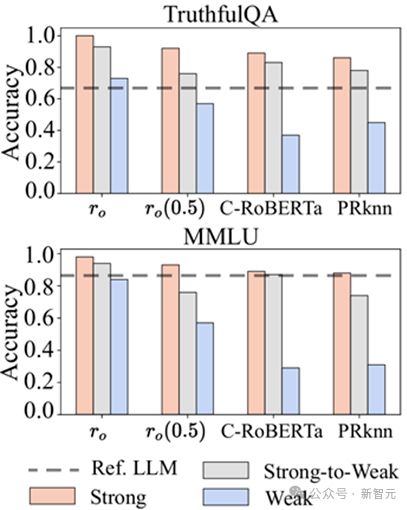
候选模型数量 m = 5
弱模型逆袭效应
通过智能路由调度,多个性能一般的 LLM 可以协同实现超越顶级单体模型的性能表现。例如,当使用 Oracle Router(r_o)调度 5 个在 MMLU 基准上单独表现仅为 0.2-0.3 的弱模型时,系统整体性能可跃升至 0.95,显著超越 GPT-4(0.86)。
这一发现为资源有限的研究者提供了新的技术路径:无需追求单一超大模型,而是通过多个中小模型的智能组合实现性能突破。
候选池规模阈值
从 Model-level Scaling Up 现象示意图可以看到3-10 个 LLM 候选的时候已经可以达到非常不错的性能。而且此时的部署成本并不高,具有很高的性价比。
实验数据表明,路由 LLM 系统的性能提升存在明显的规模经济拐点:
-
3-5 个候选 LLM:可覆盖大部分常见任务需求,部署成本相比单一顶级模型低。
-
5-10 个候选 LLM:性能进入稳定提升期,在多数基准上可超越 GPT-4 等顶级单体模型
-
多于 10 个候选 LLM:性能增益存在边际效应,每增加 1 个模型带来的性能提升并不大
这一发现为实际部署提供了重要指导:在大多数应用场景下,维护一个5-10 个模型的候选池即可实现性能与成本的最佳平衡。
例如,在智能客服系统中,组合使用 GPT-4(复杂问题)、Llama-3-8B(常规问题)和 Phi-3(意图识别)三个模型,即可在保证服务质量的同时将运营成本显著降低。
主要挑战
数据壁垒
要训练出高性能的 router,当前可用的性能记录数据仍然远远不足。由于大多数 LLM 的性能数据掌握在少数科技公司手中且未开源,这需要整个研究社区的共同努力来构建更全面的数据集。目前,可以通过迁移学习、数据增强等算法技术在一定程度上缓解数据不足的问题;
多候选分类挑战
随着候选 LLM 数量的增加,router 需要处理的分类任务复杂度显著上升。这不仅增加了模型训练的难度,也对 router 的泛化能力提出了更高要求。如何在保证分类精度的同时控制计算开销,是未来研究的重点方向之一;
多目标权衡局限
虽然路由 LLM 理论上可以同时优化性能、计算成本和幻觉风险等多个目标,但 RouterEval 目前仅聚焦于性能优化。这是因为当前 router 的性能水平尚未达到理想状态,过早引入多目标优化可能会分散研究重点。此外,计算成本和幻觉风险等指标的数据采集难度较大,需要社区共同推动相关数据集的构建;
部署复杂度
即使获得了高性能的 router,实际部署仍面临诸多挑战。多个 LLM 的协同运行需要解决计算负载均衡、资源动态分配、模型高效激活等系统级问题。幸运的是,实验表明仅需部署3-10 个 LLM 即可获得优异性能,这大大降低了实际应用的复杂度。未来研究可借鉴分布式计算领域的技术成果,进一步优化部署方案。
参考资料:






