克雷西西风发自凹非寺
量子位 | 公众号 QbitAI
Llama 4 真要被锤爆了,这次是大模型竞技场(Chatbot Arena)官方亲自下场开怼:
竞技场上,Meta 提供给他们的是特供版!
以下是竞技场背后 lmarena.ai 团队的原话:

我们注意到社区对 Llama-4 最新版本在 Arena 平台的发布存在疑问。为确保完全透明,现公开 2000 余组模型对战数据供公众审阅,包含用户提示词、模型回复及用户偏好数据(链接详见下一条推文)。
初步分析表明,模型回复风格与语气是重要影响因素(详见风格控制排名),我们正在进行更深入的分析!(比如表情符号控制?)
此外,我们即将在 Arena 平台上线 Llama-4-Maverick 的 HuggingFace 版本,排行榜结果将稍后公布。
Meta 对我们平台政策的理解与我们对模型提供商的期待存在偏差——Meta 本应明确标注"Llama-4-Maverick-03-26-Experimental"是经过人类偏好优化的定制模型。
为此,我们正在更新排行榜政策,以强化对公平性、可复现性评估的承诺,避免未来再出现此类混淆。
总结一下就是:
公开对战数据,正分析排名受影响因素
谴责 Meta 未明确标注模型版本导致评测混淆
后续:上线 Llama-4-Maverick 的 HuggingFace 版、更新排行榜政策
官方下场表态后,Llama 4 和 Meta 的路人缘进一步下降。
2000+ 轮对战记录完整公开
来看看 lmarena.ai 公开的模型对战记录详情。
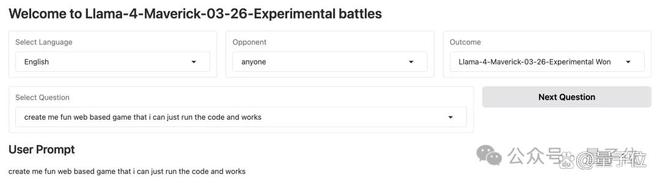
首先来看网友实测时对 Llama 4 抱怨较大的代码生成任务。
竞技场中 Llama-4-Maverick-03-26-Experimental 版本生成代码的表现的确是 OK 的。
prompt:
create me fun web based game that i can just run the code and works(帮我创建一个有趣的网页游戏,我只需运行代码就能玩)
Llama-4-Maverick-03-26-Experimental 对战加拿大 AI 初创公司 Cohere 的 command-a-03-2025。
上文 lmarena.ai 调查表示“模型回复风格与语气是重要影响因素”,从对战数据中的确可以看出 Llama-4-Maverick-03-26-Experimental 的回复中会增加如"A very nice and very direct request!" "That’s it! ""Happy gaming!"等展示友好的语句以及表情包。

运行两个模型生成的代码。
command-a-03-2025 生成的小游戏是移动鼠标控制绿色篮子接住橙色小球,看效果显然有 bug,小球直接穿过篮子,分数也没有变动:

Llama-4-Maverick-03-26-Experimental 生成的小游戏玩法是移动鼠标控制红色方块,点击四处移动的蓝色圆点 +10 分,点击黑色炸弹-10 分,每局游戏 30 秒。
可以正常运行,计分也比较准确:

这局 command-a-03-2025 输的不冤。
另外,之所以展示 Llama-4-Maverick-03-26-Experimental 和 command-a-03-2025 的对比,是因为有网友发现 Llama 4 声称的关键创新“interleaved no-RoPE attention”和 command-a 的如出一辙:

再看一个起标题的任务,prompt:
I will give a congress talk “On Naevi” — naevi are benign melanocytic lesions which are markers and every so often also precursors of melanoma. Do you have suggestions for a short and succinct title for my presentation (我将在一个学术会议上作关于“痣”的演讲——痣是黑素细胞良性病变,可作为黑色素瘤的标志物,有时甚至是其前驱病变。您能否为我的演讲推荐一个简洁有力的标题?)
Llama-4-Maverick-03-26-Experimental 对战的是 claude-3-5-sonnet-20241022。
对比来看,claude-3-5-sonnet-20241022 的回复言简意赅,直接给出 5 个标题:

Llama-4-Maverick-03-26-Experimental 的回复更为详细。
不仅会提供情绪价值,如 A very timely and relevant topic! Congrats on getting the slot at congress, by the way!(选题非常应景且切合实际!恭喜拿下大会报告机会),而且从不同角度分别提供了几个标题:

这还没完,Llama-4-Maverick-03-26-Experimental 还会贴心地指出选择标题时需要考虑的因素以及它自己选择的 top 3 标题。

最后再来随机看一道中文题目:
prompt:
解析一下这部微小说题目自驾游当年我自驾游不小心压死了一头羊羊的主人好热情宰了羊给我们吃还送我们到火车站在回来的路上看着火车外的风景真的好感人

对战 o3-mini,Llama-4-Maverick-03-26-Experimental 再次展现出超长输出的特点,故事分析完了还拆解了作者为啥要这样设计,作者本人可能都没想这么多(doge):

对战数据看下来,Llama-4-Maverick-03-26-Experimental 的排名会这么高,也不奇怪。
此前网友质疑 Llama-4-Maverick-03-26-Experimental 刷票的可能性降低。
Llama 4 深陷“造假”丑闻
如开头所述,Llama 4 被 lmarena.ai 站出来抨击的原因,是因为测试排名和实际表现不符。
在大模型竞技场中,Llama 4 得分 1417,不仅大大超越了此前 Meta 自家的 Llama-3-405B(提升了 149 分),还成为史上第 4 个突破 1400 分的模型。
而且跑分超越了 DeepSeek-V3,直接成为榜单上排名第一的开源模型。
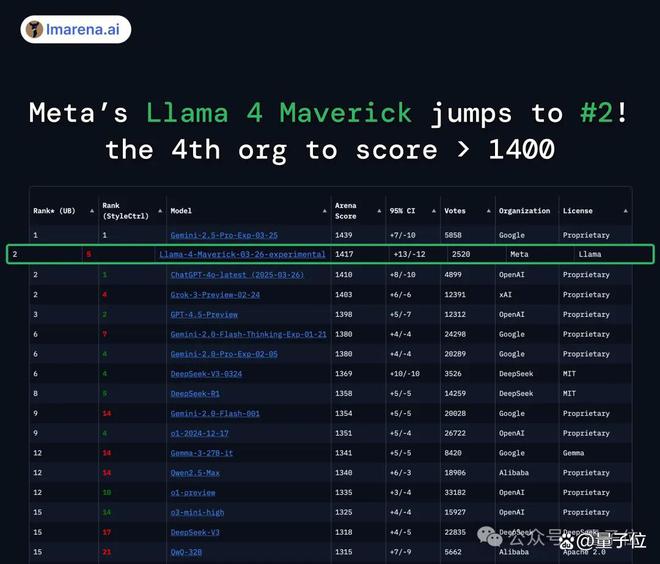
但没过多久,人们就发现 Llama 4 的实际表现相当拉胯,一时间差评如潮,甚至还被做成了表情包。

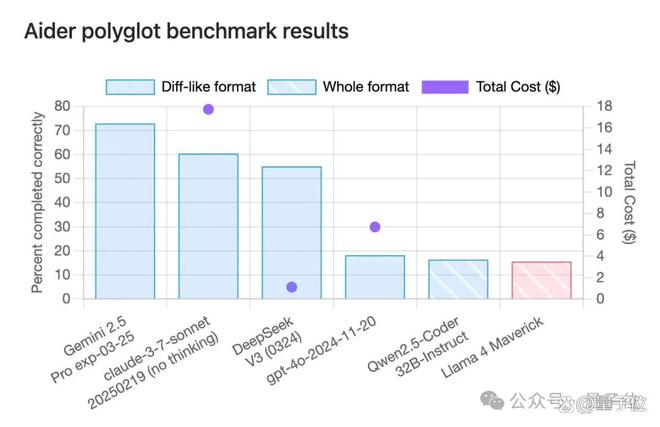
比如经典“氛围编程”小球反弹测试,小球直接穿过墙壁掉了下去。

其它跑分方面,到了各种第三方基准测试中,情况也大多直接逆转,排名掉到了末尾。
并且从 Meta GenAI 负责人 Ahmad Al-Dahle 的推文当中也能看懂,竞技场中的 Llama 4,确实是一个特殊版本。

而在最新的推文中,Ahmad 表示 Llama 4 绝对没有使用测试集进行训练,表现存在差异的原因是还需要稳定的部署。

对于这一解释,有人并不买账,直言这种现象在其他模型当中从未见过。

Meta 的支持者则表示,希望表现不佳真的是供应商的问题所致。
大模型竞技场,还能信吗?
被卷入这次旋涡的不仅是 Llama 4 和背后的 Meta,涉及到的大模型竞技场也引起了人们的广泛讨论。
毕竟 Llama 4 的“造假”风波就是发生在竞技场上,所以也自然有人质疑起了榜单的权威性。
有人指出,竞技场的偏差不只体现在 Llama 4 被高估上,还有 Claude 3.7 的表现被低估了。

当然,官方快速回应并公开了测试中的细节,这个做法获得了网友的肯定,说明至少在态度和透明度上是说得过去的。
但也有人认为,无论官方态度端不端正,Llama 4 事件说明这种“人类评价 AI”的方法,本身已经不适用了。
人们日常生活中的问题,几乎所有领先模型都能完美解答,谁还会去认真投票,这个基准已经过时了。
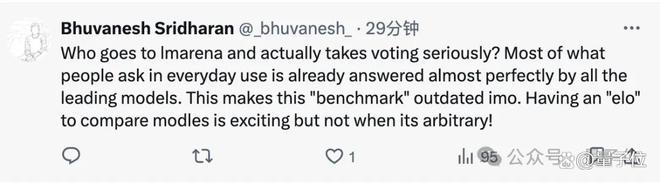
有人补充说,“人类偏好”不是评价高级大模型能力的可靠标准,产生较大偏差是正常的。

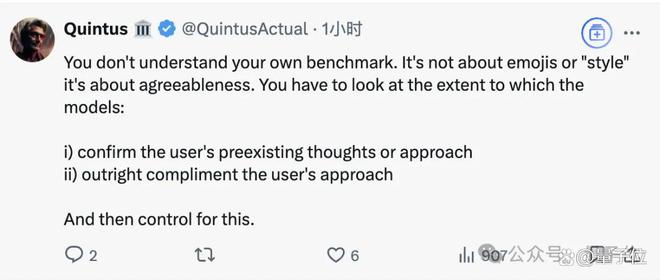
还有人表示,从官方发布的消息来看,lmarena.ai 自己都不清楚自己的基准。
这名网友解释,特调版 Llama 4 获得用户投票的原因并非 lmarena.ai 所说的“表情符号”,而是因为更具亲和力。
当然也有人提了些建设性的意见,比如更改 ELO 评分的算法,或者启用强制风格转换。
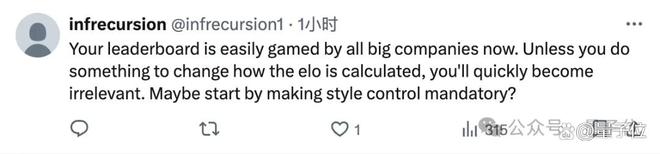
但总之,无论是迭代改进还是另辟蹊径,都是时候更新对大模型的评价方式了。
参考链接:
[1]https://x.com/lmarena_ai/status/1909397817434816562
[2]https://x.com/Ahmad_Al_Dahle/status/1909302532306092107
[3]https://huggingface.co/spaces/lmarena-ai/Llama-4-Maverick-03-26-Experimental_battles






