
新智元报道
编辑:犀牛
LeCun 谢赛宁等研究人员通过新模型 Web-SSL 验证了 SSL 在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越 CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。
最近 AI 圈最火的模型非 GPT-4o 莫属,各种风格图片持续火爆全网。
如此强悍的图片生成能力,得益于 GPT-4o 本身是一个原生多模态模型。
从最新发布的 LLM 来看,多模态已经成为绝对的主流。
在多模态领域,视觉表征学习正沿着两条采用不同训练方法的路径发展。
其中语言监督方法,如对比语言-图像预训练(CLIP),利用成对的图像-文本数据来学习富含语言语义的表示。
自监督学习(SSL)方法则仅从图像中学习,不依赖语言。
在刚刚发布的一项研究中,杨立昆、谢赛宁等研究人员探讨了一个基本问题:语言监督对于多模态建模的视觉表征预训练是否必须?

论文地址:https://arxiv.org/pdf/2504.01017
研究团队表示,他们并非试图取代语言监督方法,而是希望理解视觉自监督方法在多模态应用上的内在能力和局限性。
尽管 SSL 模型在传统视觉任务(如分类和分割)上表现优于语言监督模型,但在最近的多模态大语言模型(MLLMs)中,它们的应用却较少。
部分原因是这两种方法在视觉问答(VQA)任务中的性能差距(图1),特别是在光学字符识别(OCR)和图表解读任务中。
除了方法上的差异,两者在数据规模和分布上也存在不同(图1)。
CLIP 模型通常在网络上收集的数十亿级图像-文本对上进行训练,而 SSL 方法则使用百万级数据集,如 ImageNet,或具有类似 ImageNet 分布的数亿规模数据。
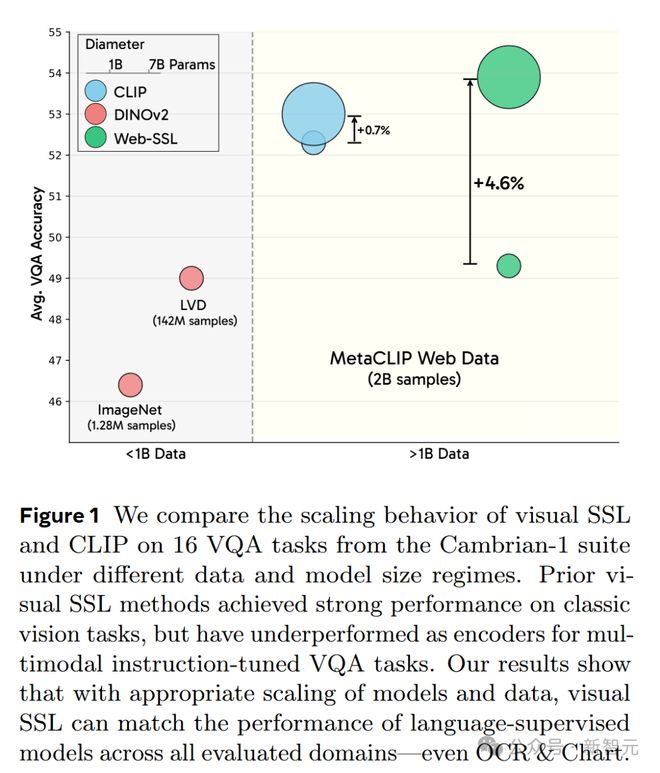
图 1 结果表明,通过适当扩展模型和数据规模,视觉 SSL 能够在所有评估领域(甚至包括 OCR 和图表任务)中匹配语言监督模型的性能
作为本文共同一作的 David Fan 兴奋的表示,他们的研究表明,即便在 OCR/Chart VQA 上,视觉 SSL 也能具有竞争力!
正如他们新推出的完全在网页图像上训练、没有任何语言监督的 Web-SSL 模型系列(1B-7B 参数)所展示的。

为了进行公平比较,研究团队在数十亿级规模网络数据上训练 SSL 模型,与最先进的 CLIP 模型相同。
在评估方面,主要使用 VQA 作为框架,采用了 Cambrian-1 提出的评估套件,该套件评估了 16 个任务,涵盖 4 个不同的 VQA 类别:通用、知识、OCR 和图表、以及 Vision-Centric。
研究团队使用上述设置训练了一系列参数从 1B 到 7B 的视觉 SSL 模型 Web-SSL,以便在相同设置下与 CLIP 进行直接且受控的比较。
通过实证研究,研究团队得出了以下几点见解:
-
视觉 SSL 在广泛的 VQA 任务中能够达到甚至超越语言监督方法进行视觉预训练,甚至在与语言相关的任务(如 OCR 和图表理解)上也是如此(图3)。
-
视觉 SSL 在模型容量(图3)和数据规模(图4)上的扩展性良好,表明 SSL 具有巨大的开发潜力。
-
视觉 SSL 在提升 VQA 性能的同时,仍能保持在分类和分割等传统视觉任务上的竞争力。
-
在包含更多文本的图像上进行训练尤其能有效提升 OCR 和图表任务的性能。探索数据构成是一个有前景的方向。
研究人员计划开源 Web-SSL 视觉模型,希望激励更广泛的社区在多模态时代充分释放视觉 SSL 的潜力。
视觉 SSL 1.0 到 2.0
研究人员介绍了本文的实验设置。相比之前的研究,他们做了以下扩展:
(1) 把数据集规模扩展到十亿级别;
(2) 把模型参数规模扩展到超过 1B;
(3) 除了用经典的视觉基准测试(比如 ImageNet-1k 和 ADE20k)来评估模型外,还加入了开放式的 VQA 任务。
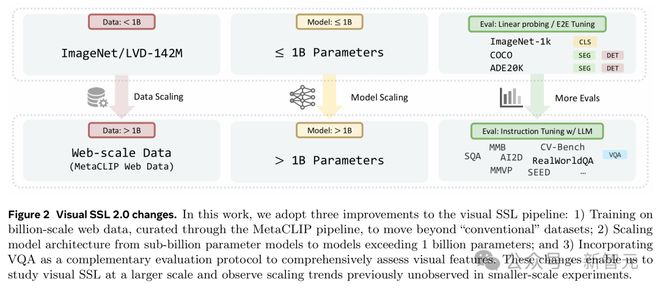
这些变化能在大规模上研究视觉 SSL,观察到之前小规模实验看不到的规模效应趋势
扩展视觉 SSL
研究团队探讨了视觉 SSL 模型在模型规模和数据规模上的扩展表现,这些模型只用 MC-2B 的图片数据来训练。
-
扩展模型规模:研究团队把模型规模从 10 亿参数增加到 70 亿参数,同时保持训练数据固定为 20 亿张 MC-2B 图片。他们用现成的训练代码和方法配方,不因模型大小不同而调整配方,以控制其他变量的影响。
-
扩展看到的数据量:研究团队把焦点转向固定模型规模下增加总数据量,分析训练时看到的图片数量从 10 亿增加到 80 亿时,性能如何变化。
扩展模型规模
扩展模型规模的目的有两个:一是找出在这种新数据模式下视觉 SSL 的性能上限,二是看看大模型会不会表现出一些独特的行为。
为此,研究团队用 20 亿张无标签的 MC-2B 图片(224×224 分辨率)预训练了 DINOv2 ViT 模型,参数从 10 亿到 70 亿不等。没有用高分辨率适配,以便能和 CLIP 公平比较。
研究团队把这些模型称为 Web-DINO。为了对比,他们还用同样数据训练了相同规模的 CLIP 模型。
他们用 VQA 评估每个模型,结果展示在图 3 中。
研究团队表示,据他们所知,这是首次仅用视觉自监督训练的视觉编码器,在 VQA 上达到与语言监督编码器相当的性能——甚至在传统上高度依赖文字的 OCR & 图表类别上也是如此。
Web-DINO 在平均 VQA、OCR & 图表、以及 Vision-Centric VQA 上的表现,随着模型规模增加几乎呈对数线性提升,但在通用和知识类 VQA 的提升幅度较小。
相比之下,CLIP 在所有 VQA 类别的表现到 30 亿参数后基本饱和。
这说明,小规模 CLIP 模型可能更擅长利用数据,但这种优势在大规模 CLIP 模型上基本消失。
Web-DINO 随着模型规模增加持续提升,也表明视觉 SSL 能从更大的模型规模中获益,超过 70 亿参数的扩展是个有前景的方向。
在具体类别上,随着模型规模增加,DINO 在 Vision-Centric VQA 上越来越超过 CLIP,在 OCR & 图表和平均 VQA 上也基本追平差距(图3)。
到了 50 亿参数及以上,DINO 的平均 VQA 表现甚至超过 CLIP,尽管它只用图片训练,没有语言监督。
这表明,仅用视觉训练的模型在 CLIP 分布的图片上也能发展出强大的视觉特征,媲美语言监督的视觉编码器。
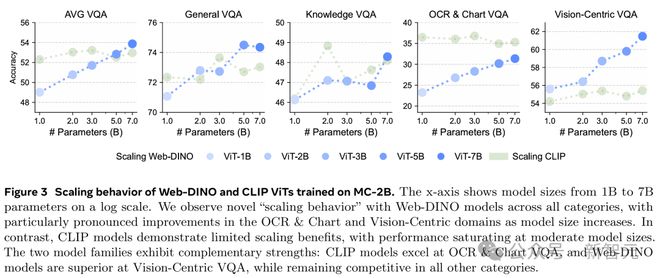
Web-DINO 模型在所有类别上都展现出新的「扩展行为」,尤其在 OCR & 图表和 Vision-Centric 领域,CLIP 模型的扩展收益有限,性能在中等规模时就饱和了
扩展所见数据量
研究团队研究了增加看到的数据量会怎样影响性能,在 MC-2B 的 10 亿到 80 亿张图片上训练 Web-DINO ViT-7B 模型。
如图 4 所示,通用和知识类 VQA 性能随着看到的数据量增加逐步提升,分别在 40 亿和 20 亿张时饱和。
Vision-Centric VQA 性能从 10 亿到 20 亿张时提升明显,超过 20 亿张后饱和。
相比之下,OCR & 图表是唯一随着数据量增加持续提升的类别。
这说明,模型看到更多数据后,学到的表征越来越适合文字相关任务,同时其他能力也没明显下降。
另外,和同规模的 CLIP 模型(ViT-7B)相比,Web-DINO 在相同数据量下的平均 VQA 表现始终更强(图 4)。
尤其在看到 80 亿张样本后,Web-DINO 在 OCR & 图表 VQA 任务上追平了 CLIP 的表现差距。
这进一步证明,视觉 SSL 模型可能比语言监督模型有更好的扩展潜力。
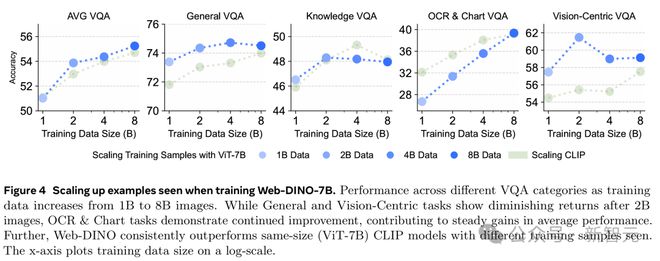
随着训练数据从 10 亿增至 80 亿张图片,Web-DINO-7B 在 OCR 和图表任务中持续提升,而通用和视觉任务在 20 亿张后收益递减。总体上,Web-DINO 在平均性能上稳步提高,并始终优于同规模的 CLIP 模型
Web-SSL 系列模型
研究团队在表 3 里展示了他们的视觉编码器跟经典视觉编码器对比所取得的最佳结果,涉及 VQA 和经典视觉任务。
Web-DINO 在 VQA 和经典视觉任务上都能超越现成的 MetaCLIP。
即便数据量比 SigLIP 和 SigLIP2 少 5 倍,也没语言监督,Web-DINO 在 VQA 上的表现还是能跟它们打平手。
总体来看,Web-DINO 在传统视觉基准测试中碾压了所有现成的语言监督 CLIP 模型。
虽然研究人员最好的 Web-DINO 模型有 70 亿参数,但结果表明,CLIP 模型在中等规模的模型和数据量后就饱和了,而视觉 SSL 的性能随着模型和数据规模的增加会逐步提升。
Web-DINO 在所有 VQA 类别中也超过了现成的视觉 SSL 方法,包括 DINOv2,在传统视觉基准上也很有竞争力。
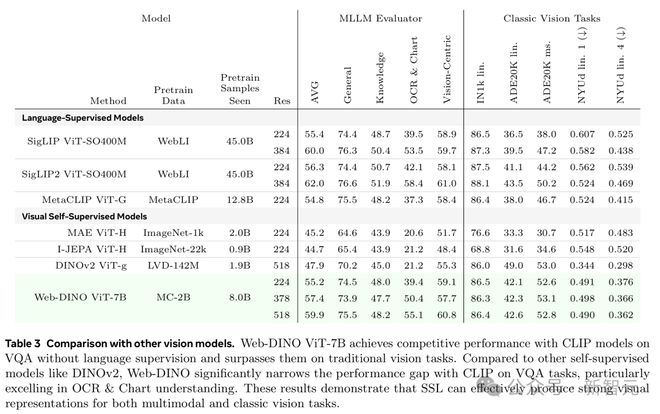
Web-DINO ViT-7B 在没有语言监督的情况下,在 VQA 任务上与 CLIP 模型表现相当,在传统视觉任务上超过了它们
研究人员还额外对 Web-DINO 微调了 2 万步,分别测试了 378 和 518 分辨率,以便跟更高分辨率的现成 SigLIP 和 DINO 版本对比。
从 224 到 378 再到 518 分辨率,Web-DINO 在平均 VQA 表现上稳步提升,尤其在 OCR 和图表任务上有明显进步。
经典视觉任务的表现随着分辨率提高略有提升。在 384 分辨率下,Web-DINO 稍微落后于 SigLIP;到了 518 分辨率,差距基本被抹平。
结果表明,Web-DINO 可能还能从进一步的高分辨率适配中获益。
作者介绍
David Fan

David Fan 是 Meta FAIR 的高级研究工程师,研究方向是自监督学习和视频表征。
曾在亚马逊 Prime Video 担任应用科学家,从事视频理解和多模态表征学习的研究,重点关注自监督方法。
此前,他在普林斯顿大学以优异成绩(Magna Cum Laude)获得计算机科学理学工程学士学位,导师是 Jia Deng 教授。
Shengbang Tong

Peter Tong(Shengbang Tong,童晟邦)是 NYU Courant CS 的一名博士生,导师是 Yann LeCun 教授和谢赛宁教授。研究兴趣是世界模型、无监督/自监督学习、生成模型和多模态模型。
此前,他在加州大学伯克利分校主修计算机科学、应用数学(荣誉)和统计学(荣誉)。并曾是伯克利人工智能实验室(BAIR)的研究员,导师是马毅教授和 Jacob Steinhardt 教授。
参考资料:






