
4 月 7 日,Meta 公司新发布的 Maverick 的新旗舰 AI 模型,在 LM Arena 测试中取得了第二名的成绩。然而,这一成绩的含金量却引发了诸多质疑。据多位 AI 研究人员在社交平台 X 上指出,Meta 在 LM Arena 上部署的 Maverick 版本与广泛提供给开发者的版本并不一致。
Meta 在其公告中明确提到,参与 LM Arena 测试的 Maverick 是一个「实验性聊天版本」。而根据官方 Llama 网站上公布的信息,Meta 在 LM Arena 的测试中所使用的实际上是「针对对话性优化的 Llama 4 Maverick」。这表明,该版本经过了专门的优化调整,以适应 LM Arena 的测试环境和评分标准。
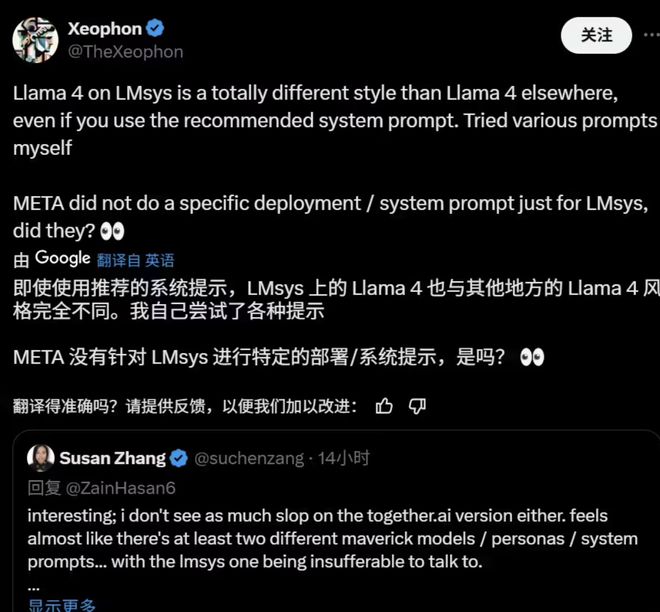
事实上,研究人员在 X 上已经观察到了公开可下载的 Maverick 版本与 LM Arena 上托管的模型之间存在显著的行为差异。例如,LM Arena 版本似乎更倾向于使用大量的表情符号,并且给出的答案往往冗长且拖沓。
Meta 公司以及负责维护 LM Arena 的 Chatbot Arena 组织暂未对此做出回应。(来源:IT 之家)






