转自知乎
作者张志强蚂蚁 Ling 模型研发负责人
蚂蚁开源大模型的低成本训练细节,疑似曝光!
这段时间,蚂蚁一篇技术论文引发关注。论文中显示,他们推出的两款 MoE 大模型,能够在国产 GPU 上完成与英伟达同效的训练。一时间,该消息在技术圈发酵,登上了热搜,甚至还传出「计算成本低于 DeepSeek」一些传闻。

现在,蚂蚁 Ling 模型研发负责人张志强在知乎上作出了回应
他发布长文《关于我们抠 FLOPS 的一些点滴》,分享了他们一些大模型训练的经验和教训。

包括训练正确性对齐、Router TP(Tensor Parallelism)bug 修复、训练稳定性等问题的解决。
最后还回应了外界对于他们成本计算的误解,并表示不管是在 GPU 还是在国产加速卡上,LLM 的训练成本优化都是无止境的。
Ling 的训练过程一定程度地说明,在我们做的这些技术努力上,国产加速卡的训练成本与 GPU 相当甚至更低,同时可以保证 Loss 收敛一模一样。
在不改变原意的基础上,量子位做了如下整理在此分享给大家,希望能给大家带来一定的启发。
(量子位已获原作者授权)
关于我们抠 FLOPS 的一些点滴
本周开始看到有媒体关注我们团队的模型训练成果,其实月初我们就在 GitHub 和 Hugging Face 上发布了 Ling 模型权重和技术报告(https://arxiv.org/abs/2503.05139),名字就叫「EVERY FLOP COUNTS」,关于使用非 NVIDIA 加速卡集群训练 Ling 300B MoE 大模型的一些技术细节。我们的技术报告被外媒记者发现了,“出口转内销”地被关注到。其实我们本来就准备在月底的小型技术沙龙上分享经验教训的,既然被关注到了,就来提前说明一下吧。
从开源来,回社区去
即使如最近大热的 DeepSeek,也受限于算力问题进行了很多精彩的优化,对于我们一线研发人员来说,克服环境的限制就是工作。众所周知,和国外的大模型团队相比,中国团队面对了更多的异构加速卡的挑战,我们并不是第一家面对异构问题的公司,比如智源研究院就发起了 FlagScale 项目,研发面向异构加速卡的训练框架。有了开源社区,我们可以利用同行们的前期探索作为工作的基础。
同样,我们的实践成果也回馈给社区,希望可以帮助社区减少不必要的重复劳动。蚂蚁在去年开源 DLRover 项目(https://github.com/intelligent-machine-learning/dlrover),报告提到的轻量级选择性跟踪框架 XPUTimer 就集成在 DLRover 上,可以为不同算力平台上的大规模训练任务提供监控诊断功能。希望这些对社区的回馈,可以给大家带来一些启发。
一些收获和经验教训
在写这份技术报告时,我们希望分享 Ling 研发过程的一些关键 insight。Insight 可以是 novelty story,也可以是 bitter lesson。这里和大家聊聊我们得到的一些教训。作为较早吃螃蟹的人,分享这些教训并不是想吐槽,只是希望可以帮助其他同行避开一些问题,当然也希望可以促进国产加速卡的更快成熟。下面展开聊一聊几个我印象深刻的 bitter lesson。
训练正确性对齐
为了让大规模 MoE LLM 可以在多个算力平台上进行无缝切换训练,训练正确性对齐是必不可少又极其繁琐的一个过程。对齐有不同的标准,比如在不同平台训练都可以正常收敛是一个标准,而算子精度、训练框架、loss 完全对齐又是另外一个标准。“很傻很天真”的我们本着技术问题应该知其然又知其所以然的信念,定下了一个非常严格标准,基础算子(除符合预期的精度误差)完全对齐 + 分布式训练框架前后向计算完全对齐 + 大规模训练长跑 loss 差异低于 0.1%,当然这也换来了无数个通宵 debug 的难忘体验。
有趣的是,在做正确性对齐的过程中,我们同步也在做关于 scaling law 的研究。我们发现,通过设计一个合理的外推拟合方法,在不进行真实训练的情况下,一个尺寸较大(比如 20B、80B)的模型在正式训练较长时间(比如 2T token)后的 loss,可以被一系列 1B 以下的小尺寸模型的训练外推预测,其预测误差低于 0.5%。这样看来,跨平台训练的 loss 差异低于 0.1% 其实是一个合理的要求。
在算子对齐上,我们将不同平台的基础算子进行了完全对齐实现,比如 matmul、linear 等。
Router TP(Tensor Parallelism)bug 修复
在框架上,FSDP 向 MindSpeed(Megatron)对齐引入 tensor parallelism 特性会导致一系列模型收敛问题,尤其是在 MoE 相关的 router 部分非常严重。这里展开讲一下我们的工作。
在 router 的前向计算上,由于 sp(sequence parallel)在 Megatron 中对 router 的输入进行了切分,导致其输入并不完整,因此在 router 相关 loss 计算(包括 load_balance_loss 和 z_loss)时会额外使用 gather 操作将不同 sp rank 上的数据同步到一起,以进行完整 batch 计算。这个过程并没有专门针对反向进行对应的 reduce 实现,会导致回传梯度重复,需要手动对 router 相关的 loss 系数进行放缩。值得注意的是该 bug 已经在 Megatron 0.7.0 版本修复;当时 MindSpeed 支持到 0.6.0 版本,因此需要进行额外 patch 修复。
在 router 的反向计算上,Megatron 对 router 通过 gather 操作获取了完整的 logits,而 MindSpeed 在后续的 permute/unpermute 操作中需要强制使用 local logits,因此额外进行一次 scatter 操作来进行切分,出现了 loss 不敛性问题。经过排查,我们发现是 scatter_to_sequence_parallel_region 在反向实现中进行了一次 _gather_along_first_dim 操作导致梯度比正常梯度更大。最终我们在每一次 scatter 操作之后添加了对应的 gradient_scale 实现以保证梯度的正确性,从而满足 loss 收敛的需求。
NormHead 迁移
参考百川的训练经验,我们也采用了 NormHead 来保证训练的稳定(虽然初衷是为了保证训练稳定,但是后来通过 scaling law 分析,我们发现 NormHead 在 loss 上也会带来一些优势)。NormHead 从 FSDP 迁移到多 D 并行的 MindSpeed/Megatron 上也遇到了问题。
FSDP 上的参数在逻辑上是没有被切分的,因此 NormHead 的实现非常简单高效,通过 Torch 原生自带的 torch.nn.functional.normalize 即可完成对 lm_head.weight 标准化操作。在 MindSpeed/Megatron 中,由于涉及到了多 D 并行,因此需要修改 NormHead 的实现方法进行适配。最直接简单的方案就是结合 torch.nn.functional.normalize 的实际计算过程,将本地设备上的 lm_head.weight 先进行标准化计算,最后使用 reduce 对标准化后的 lm_head.weight 值进行同步。遗憾的是我们发现这样实现无法保证 loss 收敛,分析其原因主要是由于在不同机器上进行数据同步采用 Megatron.core.tensor_parallel.mappings._ReduceFromModelParallelRegion,而该方案没有在反向传播过程中实现对应的梯度同步,最终导致 loss 上升;于是我们重写了一版_ReduceFromModelParallelRegionForNormHead 并实现了对应的反向以保证 loss 收敛。
另一方面,国产加速卡的某些算子可能不支持 BF16 计算,而 FP32 的算子计算效率远低于 BF16 算子,为了防止在多 D 并行中阻塞住模型的整体计算,需要对 NormHead 性能进行优化。我们设计了基于 all2all 通信的 NormHead 实现以及 HeadNormCache 等方案,以在国产加速卡上达到更优的计算效率。
训练稳定性
与 GPU 相比,国产加速卡在稳定性上确实存在不少问题,时常会遇到由于机器不稳定带来的 loss 以及 grad 异常,从而引发尖刺,影响模型的收敛过程。为了缓解这些问题,我们设计了两种不同的尖刺处理机制。
对于 loss 尖刺,我们会把历史最近的一部分 loss 作为参考,如果当前 loss 与参考的历史 loss 均值相比有明显的上升,我们就会跳过这一步的训练直接开始下一步,或直接降低这一步的学习率来减少影响。这种方法在大多数情况下是有效的,可以很好地缓解训练不稳定问题。
但我们在实验观察中发现,loss 尖刺处理机制并不能解决所有的训练不稳定问题,因为 loss 是模型训练过程的一个很宏观的表现,模型的状态在 loss 产生尖刺之前可能已经出现了不稳定。Grad 会直接作用于模型参数,对其监控相比于 loss 更加迅速,因此我们也开发了 grad 尖刺处理机制。参考 loss 尖刺的实现,我们在自研的 ATorch 框架中对所有的 _ParamAndGradBuffer 进行处理,从而实现对模型 grad 的监控。如果 grad 出现异常就跳过这一步训练。通过 grad+loss 尖刺处理机制,可以自动处理大部分的 loss 异常。
成本的计算
这次大家的一些误解也源于对成本计算的方式,其实我们在成本计算上使用了学术界比较通行的计算方法,这里也简单介绍一下。
根据在不同平台上对 Ling-Plus 的真实训练记录,我们可以观察到某个平台在 K 张加速卡上持续一段时间(比如一周)的 token 数,再根据技术报告表 1 上提到的不同加速卡的单位时间成本,就可以很简单地计算出对应平台上训练单位 token 量(报告里以 1 万亿 token 为单位)的成本。
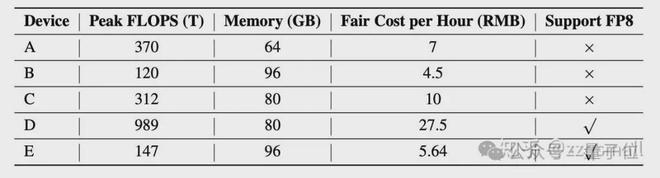
表1:AI 加速器特性与单位成本(估算)
事实上,不管是在 GPU 还是在国产加速卡上,LLM 的训练成本优化都是无止境的。Ling 的训练过程一定程度地说明,在我们做的这些技术努力上,国产加速卡上的训练成本与 GPU 相当甚至更低,同时可以保证 loss 收敛一模一样。
未来的工作
Ling 模型的发布只是我们工作的一个里程碑,后续我们还会进一步改进自己的工作。DeepSeek 为我们对训练经济性的提升带来了启发,DeepSeek 在训练中使用了 FP8 证明了这样的低精度浮点数是可以训练出来优秀的大模型的;同样我们兄弟团队基于强化学习的 AReaL(https://github.com/inclusionAI/AReaL)也开源了,强化学习也是通往 AGI 之路的重要一环。我们后续的更多工作也会陆续开源在 inclusionAI org(https://huggingface.co/inclusionAI)里。
每个 AI 研发工程师都相信 AGI 必将到来。我们相信 AGI 一定是普惠大众的,感谢大家的关心,期待未来的工作也能受到持续关注。
知乎链接:






