
华东师大&东华大学投稿
量子位公众号 QbitAI
火,Agent 可太火了!关于 Agent 的进展俯拾皆是,根本看不过来……
看过来——这篇综述可能能帮你厘清很多问题:
来自华东师大和东华大学的研究团队发表了“A Survey on the Optimization of Large Language Model-based Agents(大模型智能体的优化方法综述)”,首次从系统化视角对 LLM 智能体优化策略进行了全面梳理与分析。
论文将将现有方法划分为两大类:参数驱动的优化与参数无关的优化。
前者包括基于监督微调、强化学习(如 PPO、DPO)以及微调与 RL 结合的混合策略,重点讨论了轨迹数据构建、奖励函数设计、优化算法等关键模块。
后者则涉及通过 Prompt 工程、外部工具调用、知识检索等方式在不修改模型参数的前提下优化 Agent 行为。

除此之外,作者们还整理了主流的 Agent 微调与评估数据集,回顾了 LLM Agent 在医疗、科学、金融、编程等多个应用领域的代表性实践。
最后,研究团队总结了 Agent 当前面临的关键挑战与未来研究方向。

为什么我们需要专门优化 LLM 智能体?
近年来,随着 GPT-4、PaLM 和 DeepSeek 等大型语言模型不仅在语言理解和生成上表现出色,更在推理、规划和复杂决策等方面展现出非凡的能力。
因此,越来越多的研究者开始尝试将 LLM 作为智能体来使用,探索其在自动决策和通用人工智能方向的潜力。
与传统的强化学习智能体不同,LLM 智能体不依赖显式的奖励函数,而是通过自然语言指令、Prompt 模板与上下文学习(ICL)完成复杂任务。
这种“文本驱动”的智能体范式展现出极高的灵活性与泛化能力,能够跨任务理解人类意图、执行多步骤操作,并在动态环境中做出决策。
当前,研究者已尝试通过任务分解、自我反思、记忆增强以及多智能体协作等方式提升其表现,应用场景涵盖软件开发、数学推理、具身智能、网页导航等多个领域。
值得注意的是,LLM 本身的训练目标是预测下一个 token,并非为长期规划和交互学习的 Agent 任务而生。
这也导致了 LLM 作为 Agent 的部分挑战:
- 长程规划与多步推理能力不足,容易在复杂任务中出现累积错误;
- 缺乏持续性记忆机制,难以基于历史经验进行反思与优化;
- 对新环境的适应能力有限,难以动态应对变化场景。
尤其是开源 LLM 在 agent 任务中的表现普遍落后于 GPT-4 等闭源模型,而闭源模型的高成本与不透明性,也使得优化开源 LLM 以提升 Agent 能力成为当前研究的关键需求。
当前已有的综述要么聚焦于大模型优化本身,要么只讨论 agent 的局部能力(如规划、记忆或角色扮演),并未将“LLM 智能体优化”作为一个独立且系统的研究方向进行深入探讨。
研究团队填补了这一空白,首次以“LLM-based Agent 的优化技术”为核心议题展开系统综述,构建统一框架,归纳方法路径,并对比不同技术的优劣与适用情境。
参数驱动的 LLM 智能体优化
在参数驱动的 LLM 优化中,作者将其分为 3 个方向。
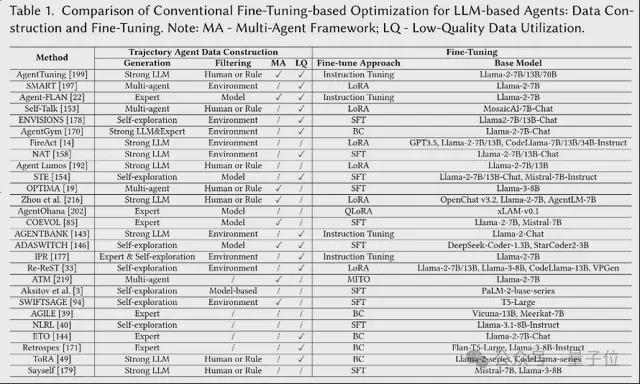
基于常规微调的优化
第一个方向,基于常规微调的优化。
又分为 2 大步骤:构建 Agent 任务的高质量轨迹数据——用轨迹微调 Agent。
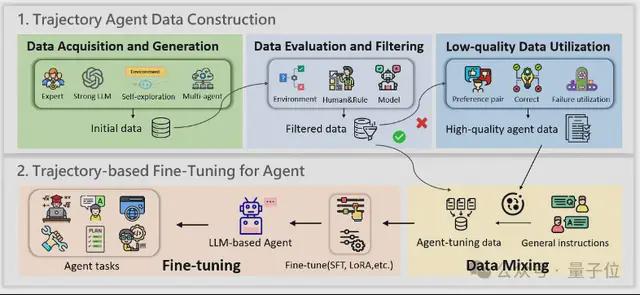
首先是数据获取与生成。
高质量的轨迹数据构建开始于初始数据的获取和生成,这不仅需要一组多样化的轨迹,还需要与目标任务充分对齐,以确保有效的学习。
作者将主流方法归纳为以下四类:
- 专家标注数据:由人类专家手工设计,质量高、对齐强,是微调的黄金标准。但人力成本高、难以扩展,常作为优质补充数据使用。
- 强 LLM 自动生成数据:利用 GPT-4 等大模型结合 ReAct、CoT 策略生成轨迹,效率高、适合大规模构建。但数据依赖大模型,存在成本高、偏差传播等问题。
- Agent 自主探索数据:通过开源模型自主与环境交互生成轨迹,成本低、可摆脱闭源依赖。缺点是探索能力有限,需配合后续筛选机制去除低质数据。
- 多智能体协作生成数据:通过多个 Agent 协同完成复杂任务流程,提升数据多样性与交互复杂度。但系统设计更复杂,稳定性和资源成本也是挑战。
其次,数据的评估与过滤。
由于生成的轨迹数据质量参差不齐,对数据进行评估和筛选成为不可或缺的一步。
作者将主流方法归纳为三类:
- 基于环境的评估:这类方法依靠任务是否成功、环境奖励等外部反馈来判断轨迹质量,易于实现,自动化程度高。但缺点是反馈信号过于粗粒度,只关注最终结果,无法发现推理链条中的隐性错误。
- 基于人工或规则的评估:通过预设规则(如任务完成度、答案一致性、多样性等)或专家人工审核,对数据进行更精细的质量控制。适配性强、准确性高,但也需要大量人工参与与复杂设计。
- 基于模型的评估:借助强大的 LLM(如 GPT-4)对轨迹进行自动打分与分析,能从相关性、准确性、完整性等维度进行多层评估,构建自动化质量评估框架。缺点在于,评估本身依赖模型,可能引入新的偏差。
接着是低质量样本的利用。
除了高质量的获取,对不合格的低质量轨迹也需要再次利用。
目前的主流策略包括:
- 对比式利用:通过对比正确与错误样本,让模型更清晰地识别哪些行为是有效的。
- 错误修正型方法:识别并修正失败轨迹,将其转化为可学习的数据,提升训练质量。
- 直接利用错误样本:不做修正,直接用失败案例训练模型,提升其面对错误情境时的容错性。
完成高质量轨迹数据构建后,下一步就是关键的微调阶段。
通过微调,让开源大模型真正适应 Agent 任务,学会规划、推理与交互,是优化 LLM 智能体不可或缺的一步。
值得注意的是,仅用 Agent 任务轨迹微调可能会削弱 LLM 的通用能力。
因此,大多工作选择混合通用指令数据与 Agent 轨迹共同训练,以在保留语言基础能力的同时,提升 Agent 执行能力。
作者将现有的微调方法划分为三大类:
- 标准 SFT:最常见的方法,通过高质量指令-输出对或轨迹数据,对模型进行全参数优化,最能对齐目标任务。此外,模仿学习中的行为克隆本质上也属于这一类,强调从专家轨迹中学习决策策略。
- 参数高效微调(如 LoRA/QLoRA):只更新少量参数,其余权重保持不动,显著降低显存与算力开销,在大模型 Agent 微调中尤为常见。相比全量微调,虽然训练开销更小,但性能往往可媲美甚至超过
- 自定义微调策略:为特定任务设计的微调方法,例如将通用指令与轨迹数据混合训练,或引入额外约束项(如正则化)提升泛化与稳定性。这类方法更具灵活性,适合复杂或稀缺任务场景。
基于强化学习的优化
相比于传统的微调方式,强化学习为 Agent 带来了更具主动性的学习路径。
它让模型不再只是“模仿”,而是能在环境中探索行为、接受奖励与惩罚,动态调整策略,真正实现从试错中成长。
作者将当前 RL 优化方式分为:基于奖励函数的优化和基于偏好对齐的优化。
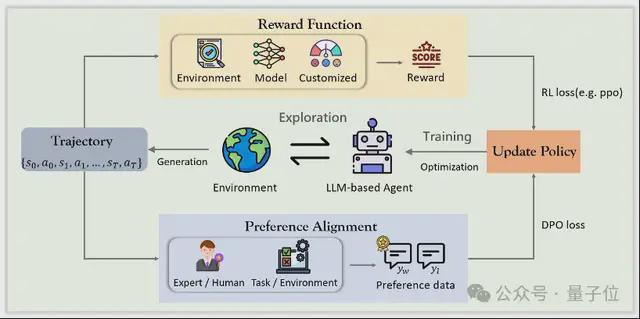
先说基于奖励函数的优化。
在强化学习优化中,奖励函数就像智能体的指挥棒,引导模型不断改进策略。通过设定清晰的“做得好 vs 做错了”标准,Agent 可以从交互中学习得更精细、更稳健。
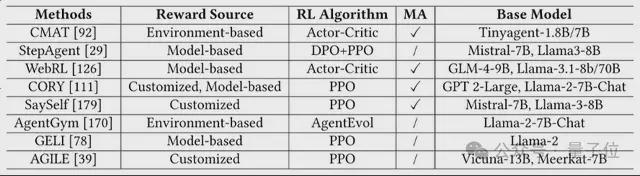
作者将当前方法按照三类奖励来源划分 3 类:
- 基于环境的奖励:直接依据任务是否完成来打分,简单直观,自动化程度高。但往往只关注最终结果,忽略了中间步骤的质量。
- 基于模型的奖励:由 LLM 或辅助模型对轨迹进行评估,适用于环境反馈稀疏的场景,能提供更细致的反馈。但效果取决于评估模型的质量。
- 自定义奖励函数:研究者根据任务需求自设多维度奖励,不仅考核完成度,也关注策略稳定性、协作效率等。灵活强大,但设计成本高、难以泛化。
再来看基于偏好对齐的优化。
相比传统 RL 基于奖励函数的训练方式,偏好对齐提供了更直接、更轻量的优化路径。
它不再依赖繁琐的奖励建模,而是让 Agent 学会“哪种行为更受人类欢迎”。
其代表方法是 DPO,一种更简单的离线强化学习方式,直接通过人类或专家的偏好对样本进行“正负对比”训练。
根据主要偏好数据来源,作者将其这类优化方法分为两类:
- 专家/人工偏好数:基于专家示范或人类标注构造正负样本(优质 vs 错误轨迹),质量高但难以大规模扩展,覆盖面有限。
- 任务或环境反馈:从任务表现(成功率、分数等)中自动构建偏好对,适用于动态任务场景,但依赖反馈机制合理的设计。
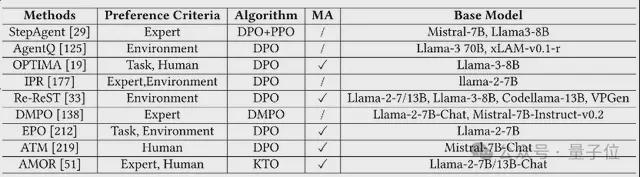
综合来看,偏好对齐方法训练高效、部署简单,但强依赖偏好数据质量与覆盖范围,适合结构明确、反馈清晰的任务场景。
而奖励函数类方法更适配复杂多变的环境,但成本更高。
混合参数微调方法
单一的优化方法各有短板——常规微调稳定高效但缺乏动态应变能力,RL 灵活强大却计算开销巨大。
于是,越来越多研究开始探索混合微调策略,结合两者优点,构建更强大的 LLM 智能体。
这类工作主要为:
第一,顺序式两阶段训练。
这也是是当前的主流方法,采取“先 SFT、后 RL”的思路。
- 阶段一:行为克隆微调(SFT),用专家轨迹或策展数据预训练模型,奠定基础能力;
- 阶段二:强化学习优化(PPO / DPO),针对环境或偏好精调模型策略。
第二,交替优化。
即引入迭代交替机制,在 SFT 和 RL 之间多轮来回切换,以实现细粒度提升。
参数无关的 LLM 智能体优化
相比参数微调,参数无关的优化方法不涉及模型权重更新,而是通过调整 Prompt、上下文和外部信息结构,在资源受限或轻量部署场景中展现出强大潜力。
作者将其分为五类核心策略:
第一类,基于经验的优化。
通过记忆模块或历史轨迹,让 Agent“学会复盘”,从过去成功与失败中提炼策略,增强长期适应性。
第二类,基于反馈的优化。
Agent 通过自我反思或外部评估不断修正行为,形成迭代闭环;还有方法通过元提示优化调整全局指令结构,提升泛化能力。
第三类,基于工具的优化。
让 Agent 学会使用工具(如搜索、计算器、API)以增强执行力。部分方法优化工具调用策略,部分则训练 Agent 构建更高效的任务-工具路径。
第四类,基于 RAG 的优化。
结合检索与生成,通过从数据库/知识库中实时获取信息增强推理过程,尤其适合知识密集型任务和变化快速的场景。
第五类,多 Agent 协作优化。
多个 LLM Agent 协同完成任务,通过角色分工、信息共享与反馈机制实现1+1>2 的协同智能。
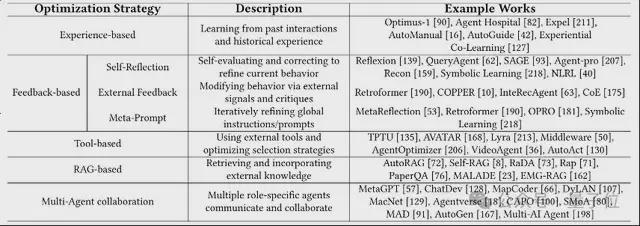
参数无关优化,让 LLM Agent 在不动模型的前提下,变得更“聪明”、更“适应”、也更“轻巧”。
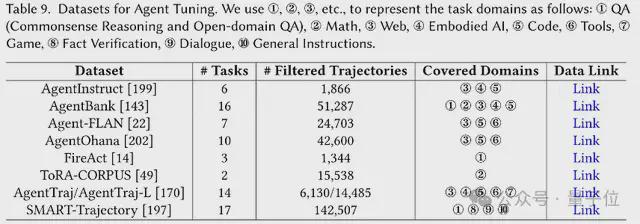
数据集与基准
作者将数据和基准分为用于评估和微调的两个大类。
评估任务分为两类。
第一类,通用评估任务。
即按一般任务领域分类,如数学推理,问题推理(QA)任务,多模态任务,编程等。
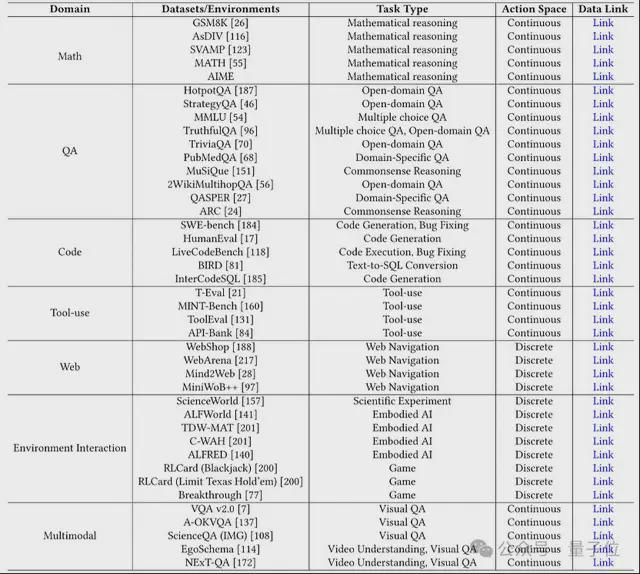
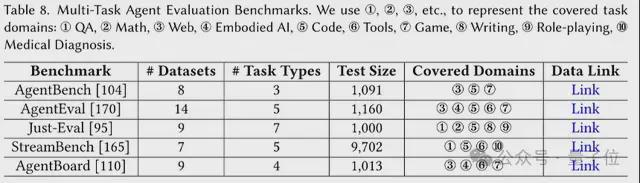
第二类,多任务评估基准。
跨各种任务评估基于 LLM 的智能体,测试它们概括和适应不同领域的能力。
Agent 微调数据集,则是针对 Agent 微调而精心设计的数据,以提高 LLM Agent 在不同任务和环境中的能力。
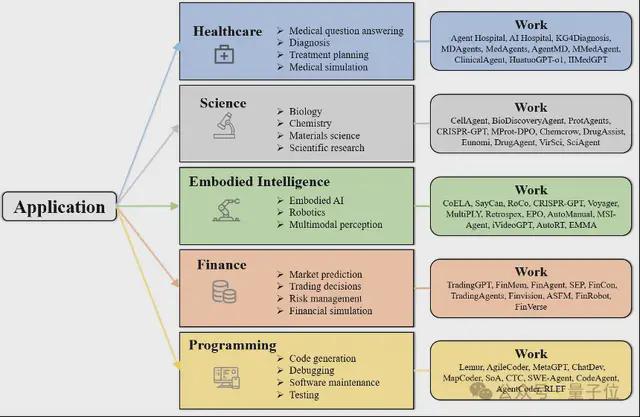
应用
随着优化方法的不断成熟,基于 LLM 的智能体已在多个真实场景中崭露头角,逐渐从实验室走向实际应用:
挑战与未来方向
数据偏差问题。
Agent 高度依赖数据质量,然而预训练数据与微调轨迹分布不匹配,再加上 LLM 自身生成与评估带来的潜在偏差,易导致性能不稳定。
未来可探索偏差测试、对抗训练、知识边界评估等方法,构建更稳健的数据基础。
算法效率与适应性。
当前强化学习与微调方法在面对稀疏奖励、大动作空间、多步交互时存在成本高、效果差的问题。
如何提升 DPO 等轻量方法的多轮能力,或探索 RL+SFT 的混合训练、元学习、自监督方法,将是未来重点。
跨任务跨领域迁移难。
许多方法在单一任务上表现优秀,但在新环境或真实世界中易失效。
需要发展更强的泛化机制,如任务分布对齐、域适应、多任务联合训练等,提升模型迁移与适应能力。
缺乏统一评估标准。
Agent 在不同任务(如数学推理、网页导航、具身 AI)中使用不同指标,难以横向比较。
建立统一的评估基准,引入推理复杂度、适应性与偏好评分等新维度,将推动 Agent 研究向更系统、可比的方向发展。
参数驱动的多智能体优化缺失。
目前多智能体策略多依赖冻结 LLM,缺乏联合参数训练机制,限制了协同智能的发展。
未来应探索多智能体联合微调、奖励共享机制、层级控制策略,提升整体系统能力与协作水平。
arXiv 链接:
https://arxiv.org/abs/2503.12434
GitHub 链接:






