衡宇发自凹非寺
量子位公众号 QbitAI
机器狗不语,只是一味地在北大未名湖畔捡垃圾。

好了明说吧,垃圾是摆拍的道具,但这长脖子的狗子,是真的有点功夫在身上的!
背后算法 QuadWBG,搭载了模块化框架,包含运动、感知、操作和规划四个模块;首次在移动抓取任务中引入通用定向可达性映射(Generalized Oriented Reachability Map),提升机器人在六自由度基座下的全身操作泛化能力。
并且结合强化学习与运动规划,使抓取成功率从以往的 30% 左右,拉升到 89%。
项目背后团队来自北大、银河通用、多伦多大学和智源研究院,相关论文已被 ICLR 2025 接收。

该工作的一作 Jilong Wang对量子位表示,这项关于 Loco-manipulation 的创新成果,其中的操作能力可以从狗子身上泛化到人形机器人身上。
现在很多机器人厂商的机器人,更加擅长的是运动控制(而不是操作能力)。
我们希望能把模型操作能力赋能更多机器人本体,不管是人形还是别的。
Local-Manipulation 创新成果
俗话说得好(不是),狗好,垃圾坏。
于是在北大校园里的各个角落,就出现了宇树机器狗 B1 如下的繁忙身影。

在 QuadWBG 的加持下,这只狗子不仅可以在现实世界中,从不同位置对地面上的物体进行抓取。

还可以很精确地在杂乱环境中抓住透明 or 镜面物体,然后放进身上的小背篓里。

先来个前情提要——
该团队的任务是给定一个目标物体的位置,机器狗需要高效地接近目标物体并最终抓取目标物体。
机器人本体由四足机器狗、6 自由度机械臂和平行抓夹组成。
机械臂末端安装了一个 RGBD 摄像头,成为了长颈狗子的眼睛,用来获取场景的 RGB 和红外信息。

如果要把任务归类,这是一个非常典型的 Local-Manipulation(运动——操作一体化)任务,它通常指智能体通过物理身体与环境进行局部交互,以实现特定任务的能力。
而「上肢(机械臂)+足式机器人」的 Local-Manipulation 最早于 2023 年被提出,后来不断快速发展。
值得注意的是,针对足式机器人的 Local-Manipulation,不能直接将抓取检测结果应用于机械臂运动规划,因为它忽略了本体和机械臂运动之间所需的协调。
而且由于动作维度不断拓宽,现实世界的物理交互又非常复杂,加上地形、视觉等,准确度和通用性仍然被限制了。
不过现在,端到端的 RL 已经提高了运动技能,推动了全身运动与操作端到端策略的发展,使机器狗子们能够执行需要运动并且与物体交互无缝协调的任务。
Just like 在未名湖畔捡垃圾的小狗子。

解密时刻!
北大校园里勤勤恳恳的小狗子,之所以能精确识别并抓取地上的各种垃圾,是因为 QuadWBG 借鉴了多种抓取检测技术的成功经验,通过将抓取姿态检测与运动规划相结合。
值得一提的是,这也是首次在移动抓取任务中引入通用定向可达性映射,提升机器人在六自由度基座下的全身操作泛化能力。
可以精准抓取透明物体,哪怕它们挤在一起:

还可以坚持不懈地疯狂捡拾,把各种材质的各种物体装进背篼里:

最后,结合 RL 与运动规划,在仿真环境中,无论物体的大小或几何复杂性如何,狗子在所有测试物体上均取得了显著更高的成功率,性能非常稳定。

在实际操作中,狗子在 14 个不同物体实例、配置和环境中的全身抓取成功率达到了 89%。
而在此之前的 SOTA,仅在 30% 左右。
针对任务中较难的透明物体抓取,10 次连续抓取也取得了 80% 的单次抓取成功率。
这是怎么做到的?
Jilong Wang 解释道,其核心创新,在于模块化结构和通用定向可达性映射。
两大核心创新
通用定向可达性映射,即 GROM,是 QuadWBG 的两大创新之一。
它是 4 个模块中“规划模块”的产物。
因此,在对话过程中,Jilong Wang 按照模块执行任务的逻辑和顺序来向量子位介绍了该工作的 2 大创新点。
至于为什么要做模块化,Jilong Wang 给出的解释是:“因为现在端到端还不足以产生足够精确的结果,而模组能够让它产生很精确的全身数据,然后我们又把现实世界的数据提供给端到端的模型进行训练。”
也就是说,团队还是希望用模型自身的能力对现实世界进行感知,然后规划运动,而不是人工手动设计。
最后的目标是实现端到端操作,这样也就“没有仿真环境和现实环境的 gap 了”,还很省钱。

话不多说,先来看看模块化结构这个创新点——
QuadWBG 是一个模块化通用四足全身抓取框架,该框架包含运动、感知、操作和规划四个模块。
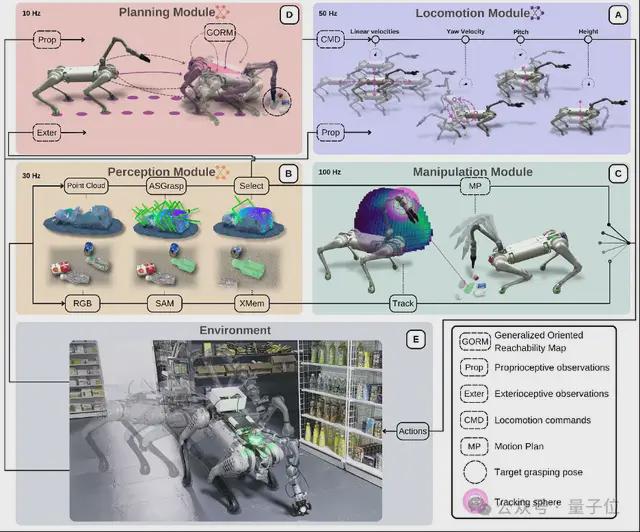
第一个,运动模块,见上图A。
它负责将本体感知信息(包含当前运动指令,关节位置与速度等)编码成隐式状态信息,并通过多层感知器(MLP)生成动作来满足当前运动指令的要求,从而实现鲁棒的移动能力。
第二个,感知模块,见上图B。
为了实现实时跟踪和精确的抓取姿态预测,感知模块利用 ASGrasp 接收红外图像和 RGB 图像作为输入,能够预测精确的深度信息。
随后,预测的深度点云被输入到 GSNet 中,从而生成更精确的六自由度抓取姿态。
第三个,操作模块,见上图C。
操作模块采用了一种运动规划方法,以解决全身 RL 策略在末端执行器控制中的不精确性问题。
该系统在 2 个不同的阶段运行:跟踪阶段和抓取阶段。
首先是跟踪阶段,团队将安装的摄像头运动限制在一个预定义的跟踪球体内,并使用可达性映射(RM,Reachability Map)来定义跟踪球体。
在该空间内,任意方向上都存在有效的反向运动学(IK,Inverse Kinematics)解。
切换机制基于 RM 和阈值可达性标准构建。
在每个规划步骤中,团队使用 RM 计算所选抓取姿态的可达性;一旦达到阈值,系统将切换到抓取阶段。
其运动规划器在线生成轨迹,使系统能够在向目标移动时适应小的意外运动。
第四个,规划模块,见上图D。
规划模块基于目标抓取位姿,利用通用定向可达性映射来生成移动指令。
现存的 ORM(Oriented Reachability Map)能够高效地表示相对于 TCP(Tool Center Point)坐标系的潜在基座位姿。
然而,ORM 有其限制性——机器人基座必须在平坦表面上。
对此,QuadWBG 项目中的银河通用团队提出了 GORM,它支持六自由度的机器人基座放置,对于世界坐标系中的任意目标位姿,均可通过 RM 的逆运算计算潜在的基座到世界的分布。
一旦定义了目标位姿,GORM 将提供高质量潜在基座位姿的分布。
团队训练高层策略以最小化当前基座位姿与最近可行位姿之间的距离,以鼓励机器人移动到基座位姿候选位置。
Jilong Wang 进一步解释了这一创新性贡献:
它本身的意义就是在 6D 空间中给任意位姿,GORM 能通过解析的方式告诉你,基座出现在哪个范围、哪个分布是最利于去抓取物体的。
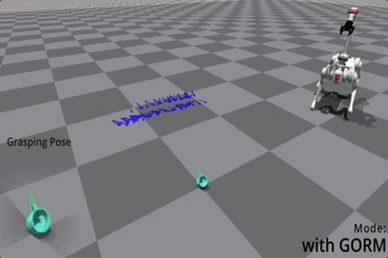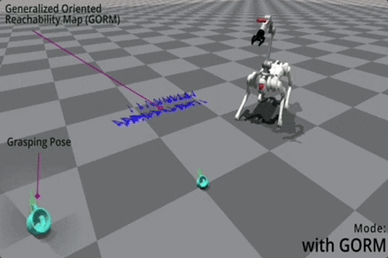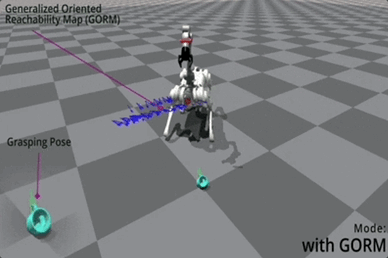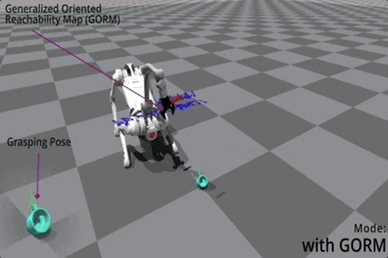
△蓝色箭头是最佳位姿的向量表示
由于 GORM 在目标位姿坐标系中定义,因此只需计算一次,使其非常高效且非常适合并行训练。
One More Thing
然鹅,由于每次抓取前都要计算出最佳位姿,这就导致了目前的一个局限性:
即便紧挨在一起的两三个垃圾,机器狗也不能通过一次识别、一次移动就连续抓取n个。
它必须得经历“识别——移动到最佳位姿——抓取——再识别——移动到新的最佳位姿——抓取”这样的过程。
具体表现就像下面这张图中这样:

捡完一个垃圾后,机器狗必须得退两步,重新识别,然后再根据新规划的最佳位姿,靠近垃圾,然后抓取。
不过!
Jilong Wang 表示,团队正在想办法解决这个问题,希望实现狗子不需要退回去,看一次就能把运动范围内的垃圾都捡起来。
减少狗子的工作量,提高效率。
毕竟保护动物,人人有责——哪怕是机器动物(doge)。






