上个月,OpenAI CEO 山姆・奥尔特曼在社交媒体上表示,号称 52 万亿参数量的 GPT-5 将在数月内发布。相较于上一代 GPT-4 的 2 万亿参数,体量上足足增长了 26 倍,虽无公布具体的训练成本,但想必也一定是个天文数字,堪称大模型领域的 “力大砖飞”。
反观 LLM 界的 “黑天鹅”,DeepSeek-V3 却仅用了 2048 块英伟达 H800 ,耗费了 557.6 万美金就完成了训练,一度引起硅谷恐慌,力证了:算力并非不可逾越的堡垒。
一边是暴力填鸭,一边是技术深化,2025 年的大模型似乎走出了两条截然不同的道路,也逐渐撕开了 AI 行业最残酷的真相:早期以 “算力” 建立护城河的大模型厂商们,在面对新一轮技术冲击时,高成本的算力反而成为了其灵活发展的累赘。
算力的必要性和局限性
作为数字经济的 “新电力”,算力在大模型的训练和推理过程中确实起到了不可或缺的作用。
以 OpenAI 为例,早期在 GPT-4 的训练中,大概就使用了 25000 个 A100 芯片。如果 OpenAI 云计算的成本是差不多 1 美元 / 每 A100 小时的话,那么在这样的条件下,仅一次训练的成本大约是 6300 万美元,同期还不乏实验、试错以及其他成本。OpenAI 的技术负责人直言:“每一次模型迭代都需要近乎天文数字的算力支撑。”
而在推理成本方面,截至 2024 年 3 月,OpenAI 就已花费 40 亿美元租用微软的服务器集群,该集群相当于 35 万个英伟达 A100 芯片,算力消耗不可谓不大。
反观国内,同样印证了这一规律。2025 年初,南京智算中心联合寒武纪,基于 7280 块国产 AI 加速卡构建全国产化算力平台,以运行 DeepSeek 671B 大模型,在供应链优化、智能客服等零售场景实现毫秒级响应。

南京智算中心机房来源:南京智算中心
这二者的共性在于:算力始终是大模型研发的 “基础设施入场券”,正如 DeepSeek 技术白皮书所言:大模型的竞争,首先是算力基础设施的竞争。
但其实,“算力” 本质上是一种 “商品化” 资源,自带经济周期属性,随着硬件成本的下降和云服务的普及,算力也逐渐脱离卖方市场,一些囤货居奇的算力厂商更是很难转型。
比如,2023 年 AI 大模型热潮期间,算力需求呈爆发式增长,英伟达 H100 8 卡节点年租金峰值达到 20 万元,而随着大模型从训练阶段转向推理阶段,算力需求骤减(训练需千卡级,推理仅需单卡级),2024 年 H100 8 卡节点年租金跌至 6 万,很多中小型企业也能依靠算力租用跑步入场。
而在算力租赁市场,截至去年,很多算力中心都出现了出租率不高、回款周期长,甚至一些底子不深的厂商直接关停一半机房,以降低日常运营成本。

来源:《算力荒,自主化智算还有必要吗?》- 脑极体
可见,大模型厂商早期在硬件性能和算力中心上的建设,虽然能够在短期内加速模型的训练和推理,但并不意味着竞争对手无法通过硬件设施的 “经济逆周期”,以及技术优化实现弯道超车,这就是 “算力” 这一大模型发展的必要资源所刻在骨子里的局限性。
直至 DeepSeek 的出现,“卡多模优” 的大模型发展格局,彻底失去优势。
护城河的重构:从 “堆料” 到 “四维壁垒”
相较于单纯的硬件 “堆料”,模型创新、数据规模、算法工程及生态构建的四维能力矩阵,正成为越来越多大模型厂商穿越周期的关键壁垒。2025 年行业数据显示,头部厂商研发投入中,算法优化( 38% )与场景化工程( 27% )的占比已超过硬件采购( 25% ),书写新竞争法则 —— 效率优先于规模。
以 DeepSeek 为例,通过 “三维创新体系” 重构行业范式:
-
模型层,首创 “神经元动态剪枝 + 混合精度训练” 架构,使 1.6 万亿参数模型体积压缩 80% ,推理速度提升 500%;
-
数据层,构建金融 / 政务领域 “知识 - 行为 - 反馈” 三元数据闭环,标注成本降低 65%;
-
而在跟算力相关的工程层,其分布式训练调度系统,将千卡集群利用率从 58% 提升至 92%。
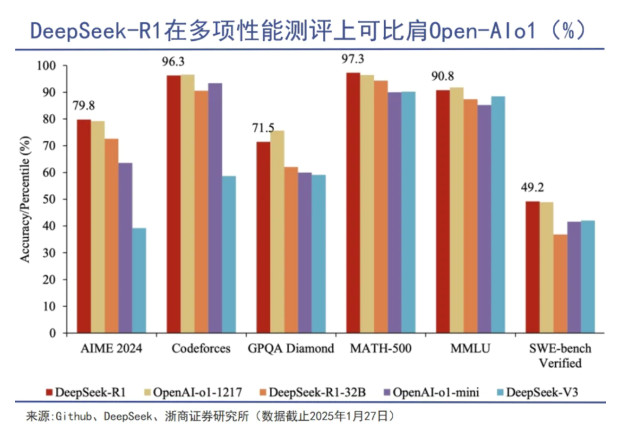
凭借这套组合拳下来,DeepSeek 训练成本降至同期竞品的 17% ,这种 “技术驱动型” 增长,不仅是对思维链突破、数据处理、系统优化等技术的最佳诠释,甚至使得 DeepSeek 利润猛增。
以行业具体实施来看。在算力的制约下,长足以来,业内很多人都不太看好 MaaS 这样的商业模式,因为 MaaS 的核心成本是算力租赁,依赖 API 调用按 token 计费,本质上可以看作为 “算力批发”—— 想要赚钱,你就得投入大量算力储备,保证高并发和弹性伸缩,碰上 API 价格内卷,很多厂商根本负担不起高额得硬件投入。
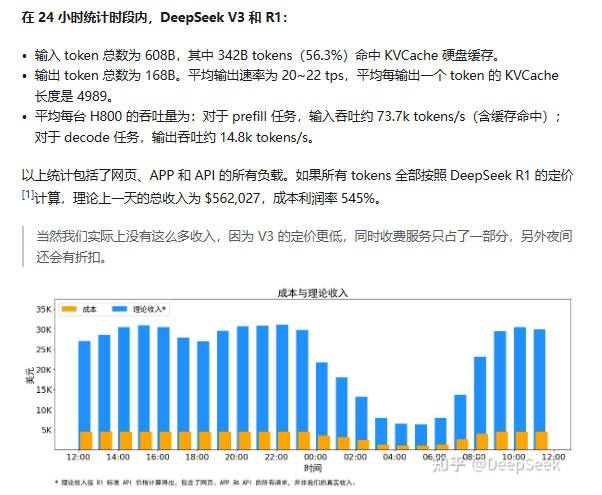
但随着 DeepSeek 出现,通过大规模的并行(包括数据并行和专家并行),尽可能为每个 GPU 分配均衡的计算负载、可通信负载,以技术升级,提升算力效率。根据《DeepSeek-V3 / R1 推理系统概括》一文中阐述:以 24 小时计算,DeepSeek V3 和 R1 推理服务峰值占用总和 278 个节点,平均占用 226.75 个节点(每个节点为 8 个 H800 GPU )。假定 GPU 租赁成本为 2 美金 / 小时,日成本为 87072 美元 / 天。
而对比 24 小时所输出的 tokens 全部按照 DeepSeek R1 的定价计算,理论上一天的总收入为 562027 美元 / 天,成本利润率高达 545%。
除此之外,开源生态正加速成为模型创新的催化剂。Meta Llama 3 通过开源策略(免费使用、多平台支持)及训练效率优化(预训练数据扩展、后训练技术),使中小企业模型部署成本显著降低;智谱 GLM-4 依托 10 万开发者社区的持续优化,在代码生成等任务上实现同参数模型的性能超越,体现了开源协作对模型迭代的推动作用。
如此看来,这场产业革命的深层动因,不仅源于算力资源的成本周期,更源自于技术演进的内在规律:
-
算力供给的周期调整:2023-2025 年全球总算力复合增长率达 147%,但单位算力成本下降曲线(年降 68%)远超规模扩张速度,标志着算力正从 “战略资源” 向 “基础建设” 加速蜕变。简言之,算力主导的大模型经济,难以覆盖早期硬件设备上的成本投入;
-
价值创造的路径迁移:算法创新对模型效能的贡献率从 2020 年的 38% 跃升至 2025 年的 67%。例如 DeepSeek 的算法优化、理论利润,间接证明了算法创新才能撬动算力效益,并也能实现很好的商业变现。
站在 2025 年的时代坐标回望,算力作为产业发展的 “数字燃料”,已完成了它帮助早期模型厂商爬坡式发展的使命,随着越来越多大模型应用的加速投产,模型厂商们能依仗的绝不是训练、推理这些模型的算力规模,而是真正能让这些算力产生乘积效应的技术创新、能力整合,以及市场洞察。
算力之争的终局,是通过技术让算力不再成为问题。






