
新智元报道
编辑:LRST
【新智元导读】视觉价值模型(VisVM)通过「推理时搜索」来提升多模态视觉语言模型的图像描述质量,减少幻觉现象。实验表明,VisVM 能显著提高模型的视觉理解能力,并可通过自我训练进一步提升性能。
在现代多模态视觉语言模型(VLM)的发展中,提高图像描述的准确性和细节丰富性始终是一个挑战。尽管基于大规模数据的训练极大推动了模型性能,但在实际应用中,模型仍面临识别细微图像区域和减少「幻觉」现象的问题。
推理时搜索(inference time search)作为一种提升响应质量的有效方法,已在大型语言模型中展现出巨大潜力。
O1 和 QwQ 等大语言模型通过在推理阶段在语言空间中进行搜索得到更好的回答,在数学和代码等任务中展现了远超越其他模型的卓越性能。
那么,我们能否同样通过推理时搜索来提升多模态视觉语言模型的响应质量,并减少响应中的幻觉呢?答案是是的。
来自马里兰大学和微软的研究团队提出了视觉价值模型(Vision Value Model, VisVM),通过精确控制搜索过程来显著提高模型在视觉任务中的表现。

论文地址: https://arxiv.org/abs/2412.03704
项目页面: https://si0wang.github.io/projects/VisVM/
项目代码:https://github.com/si0wang/VisVM
VisVM 是一种价值网络,可以通过对逐步生成描述性标题提供奖励信号来指导视觉语言模型(VLM)在推理时的搜索。
模型训练
VisVM 首先使用 VLM 自身生成多个多样化的响应,并将这些响应按照句子维度拆分成的 sentence pair。
对于每一个 current sentence 使用 CLIP model 计算这句话和对应图像的 cosine similarity 作为 reward,最后构成< current sentence, reward,next sentence, Image>的四元组作为 VisVM 的训练数据。
VisVM 使用强化学习中的时序差分学习(Temporal Difference learning)作为损失函数进行训练。这使得 VisVM 不仅可以评估当前句子与图像之间的匹配程度,还可以预测当前句子如何影响未来句子的生成,为搜索提供一个长期价值信号。
VisVM 引导下的推理阶段搜索:
在训练好 VisVM 之后,作者使用 VisVM 作为奖励信号来逐步精细化推理过程。这一过程包括以下几个步骤:
1. 生成多个句子候选:首先,模型会生成多个可能的句子,作为响应的候选。
2. 通过 VisVM 进行评估:接下来,利用 VisVM 对这些候选句子进行综合评估,考察其与图像内容的匹配度以及对未来生成句子的潜在影响(句子中包含的幻觉,细致程度等)。
3. 选择最佳句子:根据 VisVM 的评估,从候选中挑选出最优的句子来继续生成。
相比于直接使用只考虑当前句子与图像匹配程度的 clip 分数作为奖励信号进行搜索,VisVM 可以进一步通过考虑后续生成的句子中的潜在幻觉来预测长期价值,使得 VisVM 能够避开具有更高幻觉风险的响应候选,并生成不易产生幻觉且更详细的图像描述。
通过这种迭代的推理过程,VLM 能够构建出完整且高质量的响应序列,有效减少信息遗漏和幻觉错误,显著提升模型的应用性能。
实验
研究人员采用 LLaVA-Next-Mistral-7B 作为实验的基础模型,通过在其 encoder 的最后一层添加一个线性层作为 value head,构建了 VisVM 并基于这个结构使用上文中构造的数据集与损失函数进行训练。
在后续的实验中,均使用 LLaVA-Next-Mistral-7B 作为 base model 用于生成响应。
研究人员首先评估了使用不同解码方式生成的响应质量,作者从 COCO2017 数据集中采样了 1000 个图像,并与 llava detailed description 数据集中用于图像描述的 9 个 prompt 进行了随机匹配作为测试集用于生成图像藐视。
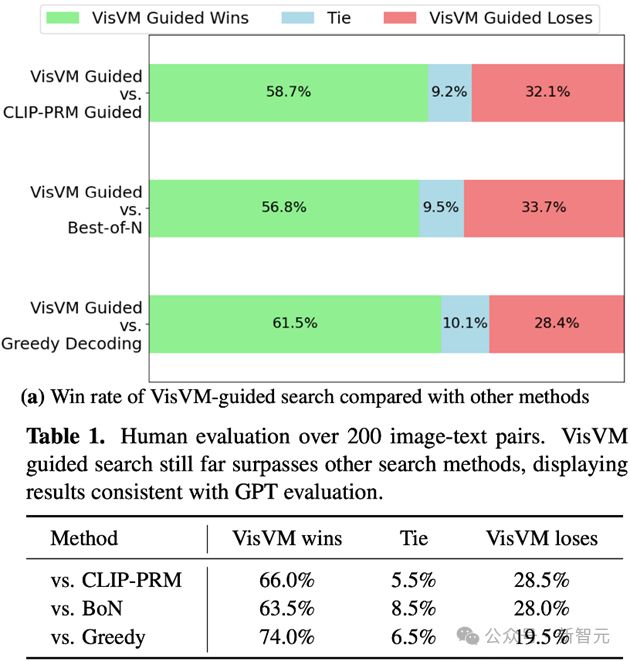
分别使用人类评估和 GPT-4o 评估,将 VisVM 引导的搜索与其他常规方法如 CLIP-PRM 指导搜索、Best-of-N 选择和贪婪解码得到的图像描述进行了比较。
结果表明 VisVM 在生成图像描述时不仅细节更为丰富,产生的幻觉也大幅减少,其生成的描述性内容更加受到 evaluator 的青睐。
尤其是在人类作为评估者的情况下,VisVM 引导搜索得到的图像描述相比于其他三个方法分别取得了 66.0%, 63.5% 和 74.0% 的获胜比率。
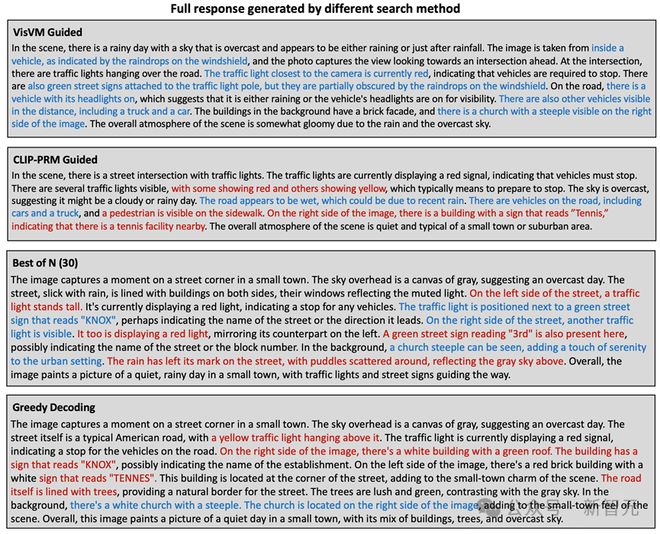
例如,在描述这个场景时,VisVM 引导的搜索甚至可以描述出挡风玻璃上的水滴挡住了绿色指示牌,这种细节在人类标注的时候甚至都难以察觉。展示了视觉价值模型对于细节描述的强大能力。

在现有幻觉的 benchmark 中,研究人员在 VLM 的 inference 阶段使用了非搜索方式生成响应用于评估。
在 CHAIR 和 MMHal 两个用于测试 VLM 幻觉的 benchmark 上 VisVM 引导的搜索取得了显著优于其他方法的效果,展示出减少 VLM 生成响应中的幻觉的强大能力

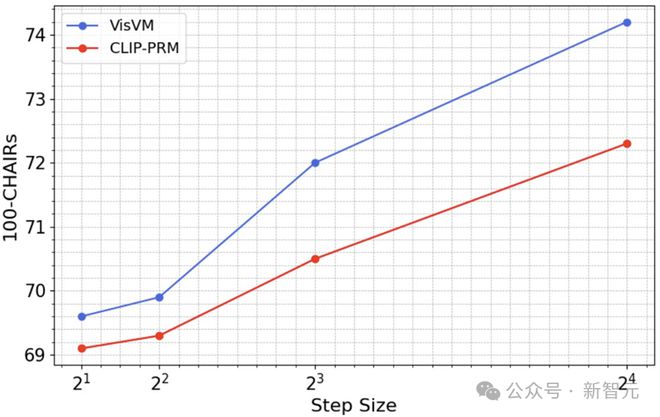
并且,作者还进一步探索了了 VisVM 引导搜索的 scaling law,结果发现无论是采用 VisVM 引导的搜索还是 CLIP-PRM 引导的搜索,随着搜索步骤大小的增加,模型的性能都会逐步提升。这一现象证明了扩大推理时间的计算量能够显著增强 VLM 的视觉理解能力。
特别值得注意的是,随着步骤大小的增加,VisVM 引导搜索的性能提升速度更快,使得两种方法之间的性能差距不断扩大。VisVM 在达到与 CLIP-PRM 相当的性能时,其计算效率几乎是后者的两倍。
通过扩大搜索步骤,VisVM 不仅能更快地达到理想的性能,还能以更低的计算成本实现,这在提升模型处理复杂视觉任务时尤为重要。
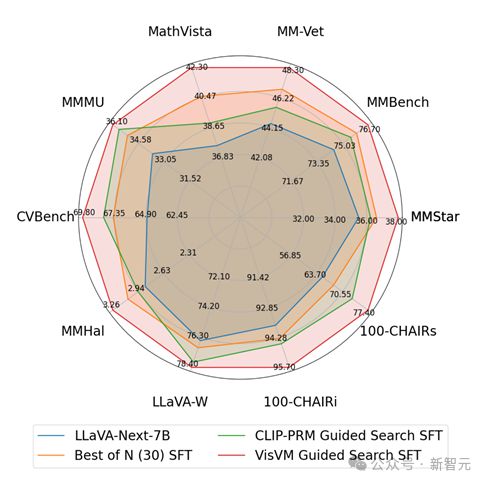
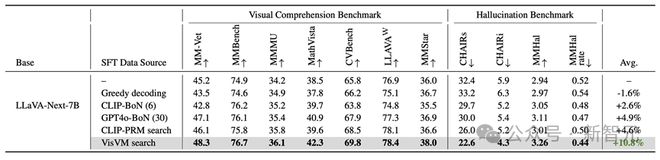
基于 VisVM 强大的减少幻觉的能力,作者使用使用 LLaVA-NEXT-Mistral-7B 作为基础模型,并利用 VisVM 作为奖励信号,搜索生成高质量的图像描述作为监督微调(SFT)数据,对 LLaVA-NEXT-Mistral-7B 进行训练。
在九个理解和幻觉基准上的测试表明,VisVM 引导的自我训练使 LLAVA-next-7B 的性能平均提升了 10.8%,相比于其他搜索方法得到的图像描述作为训练数据提升显著。
特别是在提升了视觉理解能力后,VLM 的 reasoning 能力也有所提高,例如 MMMU 和 MathVista 两个 benchmark,该结果进一步展示了 VisVM 搜索得到的图像描述质量之高。
此外,这也揭示了 VisVM 在自我训练框架中的应用潜力,仅通过在语言空间中进行高质量搜索并进行微调,就能显著提升原始 VLM 的视觉理解能力,这一发现为未来 VLM 的发展提供了新的方向和思路。
参考资料:
https://arxiv.org/abs/2412.03704






