
新智元报道
编辑:编辑部 Zjh
Anthropic 联创发文表示,谁要是说 Scaling Law 撞墙了,那他绝对错了!在 25 年,AI 靠测试时计算还会继续加速。不过,随之而来的推理成本也是天价,o3 的每个任务成本高达 20 美元,怎么办?
Scaling Law 要撞墙了?
Anthropic 联创 Jack Clark 反驳了这一说法:绝非如此!
在他看来,目前的 AI 发展还远远没到极限,「所有告诉你 AI 进展正在放缓,或者 Scaling Law 正在撞墙的人,都是错误的。」
o3 仍有很大的增长空间,但采用了不同的方法。
OpenAI 的技术秘诀并不是让模型变得更大,而是让它们在运行时,使用强化学习和额外的计算能力。
这种「大声思考」的能力,为 Scaling 开辟了全新的可能性。
而 Jack Clark 预计,这一趋势在 2025 年还会加速,届时,科技公司都会开始将大模型的传统方法跟在训练和推理时使用计算的新方法相结合。
这个论断,跟 OpenAI 首次推出o系列模型时的说法完全吻合了。
在同一时间,MIT 的研究者也发现,采用测试时训练(TTT)技术,能显著提高 LLM 进行逻辑推理和解决问题的能力。

论文地址:https://ekinakyurek.github.io/papers/ttt.pdf
Scaling Law 撞墙,绝对错了
在他的新闻通讯《Import AI》中,Clark 对关于 AI 发展已到达瓶颈的观点进行了反驳。
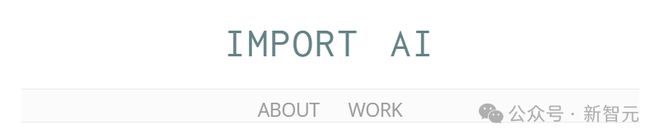
比如 OpenAI 的 o3 模型,就证明了 AI 极大的发展空间。
在现有强大基础模型之上,采用一种新方法——让大语言模型在推理时「边思考边执行」,即测试时计算(test-time compute)。这种方式能带来巨大的回报。
因此 Clark 预计,下一个合理的发展方向将是同时扩展强化学习(RL)和底层基础模型,这将带来更为显著的性能提升。
这意味着,随着现有方法(大模型 scaling)与新方法(强化学习驱动的测试时计算等)的结合,2025 年的 AI 进展相对 2024 年会进一步加速。
OpenAI 著名研究员 Jason Wei 也表示,更加关键的是,从 o1 到 o3 的进步也仅仅只用了 3 个月,这说明了在推动人工智能领域发展方面来讲,强化学习驱动的推理扩展计算范式,会比预训练基础模型的传统扩展范式快得多。

这并非空谈,Clark 列举了不少 o3 的亮眼成绩来证明他的观点。
首先,o3 有效突破了「GPQA」科学理解基准(88%),这彰显了它在科学领域进行常识推理和解答的能力。
它在「ARC-AGI」这一任务上的表现优于亚马逊众包平台(MTurk)雇佣的人类工作者。
甚至,o3 在 FrontierMath 上达到了 25% 的成绩——这是一个由菲尔兹奖得主设计的数学测试,就在几个月前,SOTA 的成绩仅为2%。
并且,在 Codeforces 上,o3 获得了 2727 分,排名第 175。这让它成为这一极其困难基准上的最佳竞技程序员之一。
模型成本将更难预测
Clark 认为,大多数人还没有意识到未来进展的速度将会有多快。
「我认为,基本上没有人预见到——从现在开始,AI 进展将会有多么急剧。」
同时,他也指出,算力成本是急速进展中的一个主要挑战。
o3 之所以如此优秀,其中的一个原因是,它在推理时的运行成本更高。
o3 的最先进版本需要的算力比基础版多 170 倍,而基础版的算力需求已经超出了 o1 的需求,而 o1 本身所需的算力又超过了 GPT-4。
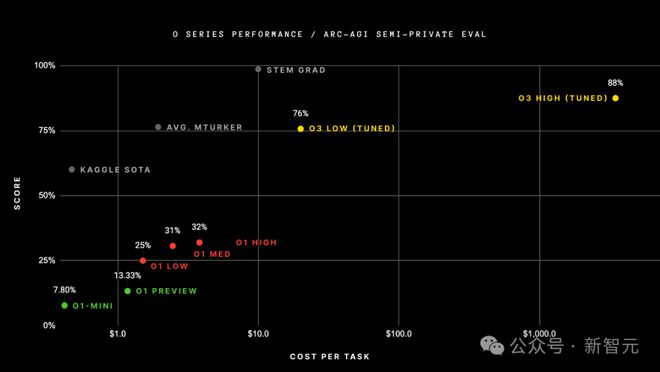
o系列模型的性能与成本
Clark 解释说,这些基于推理扩展范式的新模型使得成本预测变得更加困难。
过去,模型的成本费用是很直观的,主要取决于模型的大小和输出长度。
但在 o3 这类模型中,由于其资源需求会根据具体任务的不同而变化,所以也更难直观地给出模型执行任务时的花费。
o3 推理成本达新高
除了 FrontierMath 和 Codeforces 上的成绩,o3 在 GPT Diamond Benchmar 上,对于博士级的科学问题也拿到了 87.7%,远高于各自领域博士专家 70% 的平均分。

ARC-AGI 基准测试开发者、Keras 之父 François Chollet,将 o3 的性能称为「AI 能力中令人惊讶且重要的阶跃函数增长」
而这背后付出的代价,就是运行 o3 极高的成本。
之所以会造成如此高的成本,就是源于 o3 和其他模型处理问题方式的不同。
传统的 LLM 主要依靠的是检索存储模式,但 o3 处理问题时,却是靠实时创建新程序,来解决不熟悉的挑战。
Chollet 表示,o3 系统的工作原理,似乎和谷歌 DeepMind 的 AlphaZero 国际象棋程序类似。后者会有条不紊地搜索可能的解决方案,直到找到正确方法。

这个过程也就解释了,为什么 o3 需要如此多的算力——只为单个任务,模型就需要处理多达 3300 万个 token。
跟当前的 AI 系统相比,这种密集的 token 处理成本,简直是天价!
高强度推理版本的每个任务,运行费用约为 20 美元。
也就是说,100 个测试任务的成本为 2012 美元,全套 400 个公共任务的成本则达到了 6677 美元(按平均每个任务花费 17 美元计算)。
而对于低强度推理版本,OpenAI 尚未透露确切的成本,但测试显示,此模型可以处理 33 至 1.11 亿个 token,每个任务需要约 1.3 分钟的计算时间。

o3 在 ARC-AGI 基准测试中必须解决的视觉逻辑问题示例
等待 Anthropic 的下一步
所以,Anthropic 下一步会给我们带来什么呢?
目前,由于 Anthropic 尚未发布推理模型(reasoning model)或测试时模型(test-time model),来与 OpenAI 的o系列或 Google 的 Gemini Flash Thinking 竞争,Clark 的这一番预测,不禁让人好奇 Anthropic 的计划。
他们之前宣布的 Opus 3.5 旗舰模型至今仍没有确切消息。
开发周期长达一个月,过程充满不确定性
在 11 月,Anthropic CEO Dario Amodei 曾证实,公司正在开发 Claude Opus 的新版本。
起初,Opus 3.5 定于今年发布,但后来 Amodei 再提到它时,只是说它会在「某个时刻」到来。
不过 Amodei 倒是透露,公司最近更新和发布的 Haiku 3.5,性能已经跟原始的 Opus 3 相匹敌,同时运行速度还更快,成本也更低。
其实,这也不仅仅是 Anthropic 面临的问题。
自 GPT-4 亮相以来,LLM 的功能并没有取得重大飞跃,这种停滞已经成为 AI 行业内一种普遍的广泛趋势。
更多时候,新发布的模型只是微小的进步,跟之前有一些细微的差别。
开发更先进的 LLM,为何如此复杂
在 Lex Fridman 的播客访问中,Amodei 详细讲述了开发这些 AI 模型的复杂性。
他表示,仅训练阶段,就有可能会拖延数个月,还会需要大量的计算能力,用上数以万计的专用芯片,如 GPU 或 TPU。
预训练过后,模型将经历复杂的微调的过程,一个关键部分就是 RLHF。
人类专家会煞费苦心地审查模型的输出,根据不同标准对其进行评分,帮助模型学习和改进。
接下来,就是一系列内部测试和外部审计,来检查模型的安全问题,通常是与美国和英国的 AI 安全组织合作。
总之,Amodei 总结道:虽然 AI 的突破在圈外人士看来,像一个巨大的科学飞跃,但其实很多进步都可以归结为枯燥和无聊的技术细节。
在此过程中,最困难的部分通常是软件开发、让模型运行得更快,而不是重大的概念进步。
而且,每个新版本模型的「智能」和「个性」,也都会发生不可预测的变化。在他看来,正确训练模型与其说是一门科学,不如说是一门艺术。
即使真正发布的 Opus 3.5 的性能有了提升,却也不足以证明其高昂的运营成本是合理的。
不过,虽然有人认为 Anthropic 没有紧跟推理模型的步伐,已经足以反映 LLM 扩展的巨大挑战;但不得不说,Opus 3.5 也并非毫无意义。
显然,它帮助训练了全新的 Sonnet 3.5,它已经成为了当今市场上最受欢迎的 LLM。
参考资料:
https://the-decoder.com/ai-progress-in-2025-will-be-even-more-dramatic-says-anthropic-co-founder/






