还没等到官宣,Deepseek-v3 竟意外曝光了?!

据 Reddit 网友爆料,v3 已在 API 和网页上发布,一些榜单跑分也新鲜出炉。

在 Aider 多语言编程测试排行榜中,Deepseek-v3 一举超越Claude 3.5 Sonnet,排在第 1 位的 o1 之后。
(相比 Deepseek-v2.5,完成率从 17.8% 大幅上涨至 48.4%。)

且在 LiveBench 测评中,它是当前最强开源 LLM,并在非推理模型中仅次于 gemini-exp-1206,排在第二。

目前 Hugging Face 上已经有了 Deepseek-v3(Base)的开源权重,只不过还没上传模型介绍卡片。

综合网上多方爆料来看,Deepseek-v3 相比前代 v2、v2.5 有了极大提升——
与 v2、v2.5 配置对比
首先,Deepseek-v3 基本配置如下:
- 采用685B 参数的 MoE 架构;
- 包含 256 个专家,使用 sigmoid 函数作为路由方式,每次选取前 8 个专家 (Top-k=8);
- 支持 64K 上下文,默认支持 4K,最长支持 8K 上下文;
- 约 60 个 tokens/s;
BTW,在 Aider 测评中击败 Claude 3.5 Sonnet 的还是Instruct 版本(该版本目前未发布)。

为了进一步了解 Deepseek-v3 的升级程度,机器学习爱好者 Vaibhav (VB) Srivastav(以下简称瓦哥)还深入研究了配置文件,并总结出v3 与 v2、v2.5 的关键区别。
与v2(今年 5 月 6 日官宣开源)比较的结果,经 AI 整理成表格如下:
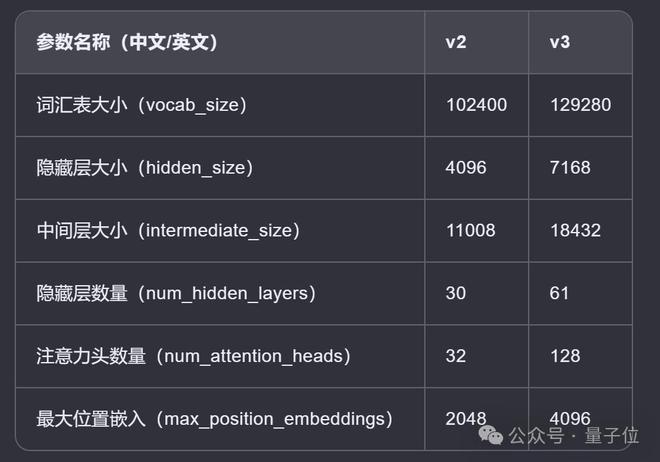
可以看出,v3 几乎是 v2 的放大版,在每一项参数上均有较大提升。
而且瓦哥重点指出了模型结构的三个关键变化:
第一,在 MOE 结构中,v3 使用了 sigmoid 作为门控函数,取代了 v2 中的 softmax 函数。这允许模型在更大的专家集合上进行选择,而不像 softmax 函数倾向于将输入分配给少数几个专家。
第二,v3 引入了一个新的 Top-k 选择方法 noaux_tc,它不需要辅助损失。
简单理解,MoE 模型通常需要一个辅助损失来帮助训练,主要用于更好地学习如何选择 Top-k 个最相关的专家来处理每个输入样本。
而新方法能在不依赖辅助损失的情况下,直接通过主要任务的损失函数来有效地选择 Top-k 个专家。这有助于简化训练过程并提高训练效率。
对了,为便于理解,瓦哥用 DeepSeek 逐步解释了这一方法。
这是一种基于群体的专家选择算法,通过将专家划分为不同的小组,并在每个小组内部选择最优秀的k名专家。

第三,v3 增加了一个新参数e_score_correction_bias,用于调整专家评分,从而在专家选择或模型训练过程中获得更好的性能。

此外,v3 与v2.5(本月 10 日官宣开源)的比较也出炉了,后者主要支持联网搜索功能,相比 v2 全面提升了各项能力。

同样经 AI 整理成表格如下:

具体而言,v3 在配置上超越了 v2.5,包括更多的专家数量、更大的中间层尺寸,以及每个 token 的专家数量。
看完上述结果,瓦哥连连表示,明年有机会一定要见见中国的开源团队。(doge)

网友实测 Deepseek-v3
关于 v3 的实际表现,另一独立开发者 Simon Willison(Web 开发框架 Django 的创始人之一)也在第一时间上手测试了。
比如先来个自报家门。
我是 DeepSeek-V3,基于 OpenAI 的 GPT-4 架构……

再考考图像生成能力,生成一张鹈鹕骑自行车的 SVG 图。

最终图形 be like:

对了,在另一网友的测试中,Deepseek-v3 也回答自己来自 OpenAI??

该网友推测,这可能是因为在训练时使用了 OpenAI 模型的回复。

不过不管怎样,还未正式官宣的 Deepseek-v3 已在 LiveBench 坐上最强开源 LLM 宝座,在一些网友心中,这比只搞期货的 OpenAI 遥遥领先。(手动狗头)






