西风发自凹非寺
量子位公众号 QbitAI
时隔 6 年,一度被认为濒死的“BERT”杀回来了——
更现代的 ModernBERT 问世,更快、更准、上下文更长,发布即开源!
去年一张“大语言模型进化树”动图在学术圈疯转,decoder-only 枝繁叶茂,而曾经盛极一时的 encoder-only 却似乎走向没落。

ModernBERT 作者 Jeremy Howard 却说:encoder-only 被低估了。
他们最新拿出了参数分别为 139M(Base)、395M(Large)的两个模型上下文长度为 8192 token,相较于以 BERT 为首的大多数编码器,其长度是它们的16 倍
ModernBERT 特别适用于信息检索(RAG)、分类、实体抽取等任务。
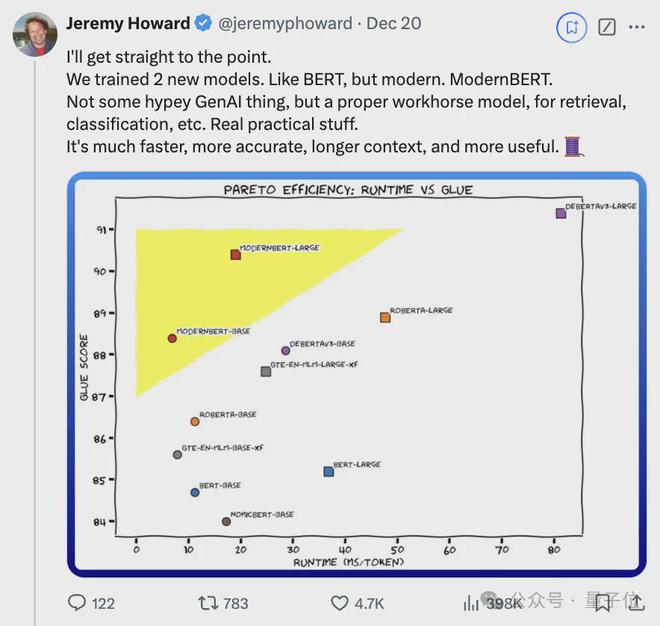
在检索、自然语言理解和代码检索测试中性能拿下 SOTA:
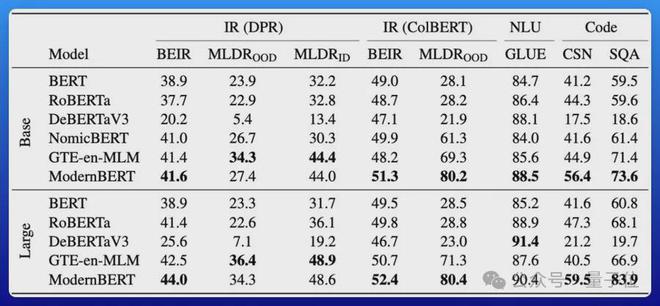
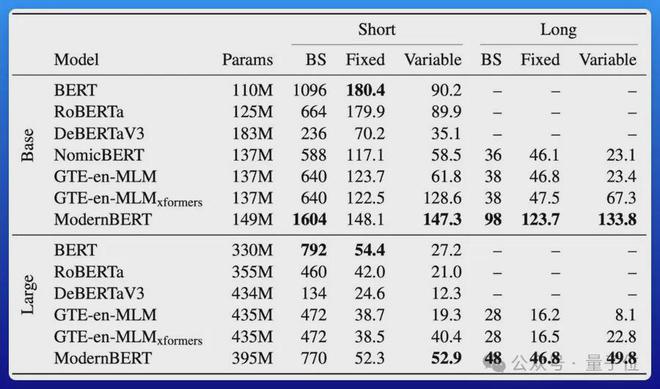
效率也很高。
ModernBERT 速度是 DeBERTa 的两倍;在更常见的输入长度混合的情况下,速度可达 4 倍;长上下文推理比其它模型快约 3 倍。
关键它所占的内存还不到 DeBERTa 的五分之一。
Jeremy Howard 表示,目前关于生成式模型的热议掩盖了 encoder-only 模型的作用。
像 GPT-4 这样大模型,太大、太慢、私有化、成本高昂,对许多任务来说并不适合,还有 Llama 3.1,参数都达到了 405B。
这些模型运行缓慢,价格昂贵,而且不是你可以控制的。
GPT-4 这样的生成模型还有一个限制:它们不能预先看到后面的 token,只能基于之前已生成的或已知的信息来进行预测,即只能向后看。
而像 BERT 这样的仅编码器模型可以同时考虑前后文信息,向前向后看都行。

ModernBERT 的发布吸引数十万网友在线围观点赞。
抱抱脸联合创始人兼 CEO Clem Delangue 都来捧场,直呼“爱了!!”。
为什么 ModernBERT 冠以“现代”之名?相较于 BERT 做了哪些升级?
杀不死的 encoder-only
ModernBERT 的现代体现在三个方面:
- 现代化的 Transformer 架构
- 特别关注效率
- 现代数据规模与来源
下面逐一来看。
首先,ModernBERT 深受Transformer++(由 Mamba 命名)的启发,这种架构的首次应用是在 Llama2 系列模型上。
ModernBERT 团队用其改进后的版本替换了旧的 BERT-like 构建块,主要包括以下改进:
- 用旋转位置嵌入(RoPE)替换旧的位置编码,提升模型理解词语之间相对位置关系的表现,也有利于扩展到更长的序列长度。
- 用 GeGLU 层替换旧的 MLP 层,改进了原始 BERT 的 GeLU 激活函数。
- 通过移除不必要的偏置项(bias terms)简化架构,由此可以更有效地使用参数预算。
- 在嵌入层之后添加一个额外的归一化层,有助于稳定训练。
接着,在提升速度/效率方面,ModernBERT 利用了 Flash Attention 2 进行改进,依赖于三个关键组件:
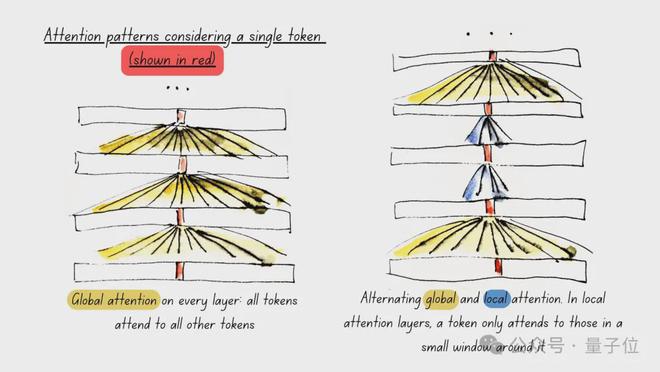
一是使用交替注意力(Alternating Attention),提高处理效率。
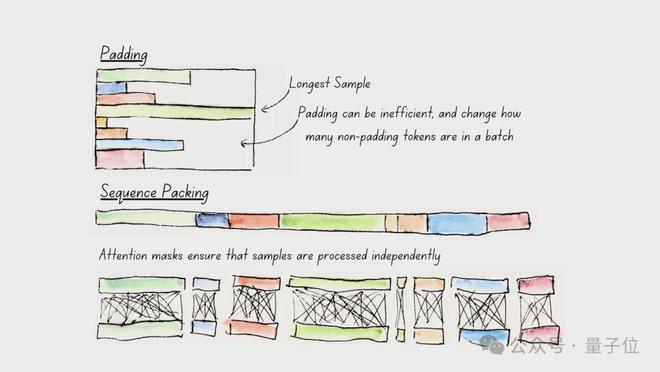
二是使用Unpadding 和 Sequence Packing,减少计算浪费。
三是通过硬件感知模型设计(Hardware-Aware Model Design),最大化硬件利用率。

这里就不详细展开了,感兴趣的童鞋可以自行查阅原论文。
最后来看训练和数据方面的改进。
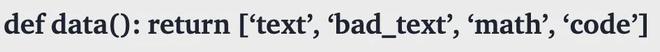
团队认为,encoders 在训练数据方面的落后,实际问题在于训练数据的多样性,即许多旧模型训练的语料库有限,通常只包括维基百科和书籍,这些数据只有单一的文本模态。
所以,ModernBERT 在训练时使用了多种数据,包括网络文档、编程代码和科学文章,覆盖了 2 万亿 token,其中大部分是独一无二的,而不是之前 encoders 中常见的 20-40 次的重复数据。
训练过程,团队坚持使用原始 BERT 的训练配方,并做了一些小升级,比如移除了下一句预测目标,因为有研究表明这样的设置增加了开销但没有明显的收益,还将掩码率从 15% 提高到 30%。
具体来说,139M、395M 两个规格的模型都通过了三阶段训练。
首先第一阶段,在序列长度为 1024 的情况下训练 1.7T tokens。然后是长上下文适应阶段,模型处理的序列长度增加到 8192,训练数据量为 250B tokens,同时通过降低批量大小保持每批次处理的总 tokens 量大致相同。最后,模型在 500 亿个特别采样的 tokens 上进行退火处理,遵循 ProLong 强调的长上下文扩展理想混合。
一番操作下来,模型在长上下文任务上表现具有竞争力,且处理短上下文的能力不受损。
训练过程团队还对学习率进行了特别处理。在前两个阶段,模型使用恒定学习率,而在最后的 500 亿 tokens 的退火阶段,采用了梯形学习率策略(热身-稳定-衰减)。
团队还使用两个技巧,加速模型的训练过程,一个是常见的 batch-size warmup,另一个是受微软 Phi 系列模型启发,利用现有的性能良好的 ModernBERT-base 模型权重,通过将基础模型的权重“平铺”扩展到更大的模型,提高权重初始化的效果。

作者透露将将公开 checkpoints,以支持后续研究。
谁打造的?
前面提到的 Jeremy Howard 是这项工作的作者之一。
ModernBERT 的三位核心作者是:
Benjamin Warner、Antoine Chaffin、Benjamin ClaviéOn。

Jeremy Howard 透露,项目最初是由 Benjamin Clavié在七个月前启动的,随后 Benjamin Warner、Antoine Chaffin 加入共同成为项目负责人。

Benjamin ClaviéOn、Benjamin Warner,同 Jeremy Howard 一样,来自 Answer.AI。Answer.AI 打造了一款能 AI 解题、概念阐释、记忆和复盘测试的教育应用,在北美较为流行。
Antoine Chaffin 则来自 LightOn,也是一家做生成式 AI 的公司。
团队表示 BERT 虽然看起来大家谈论的少了,但其实至今仍在被广泛使用:
目前在 HuggingFace 平台上每月下载次数超 6800 万。正是因为它的 encoder-only 架构非常适合解决日常出现检索(例如用于 RAG)、分类(例如内容审核)和实体提取任务。
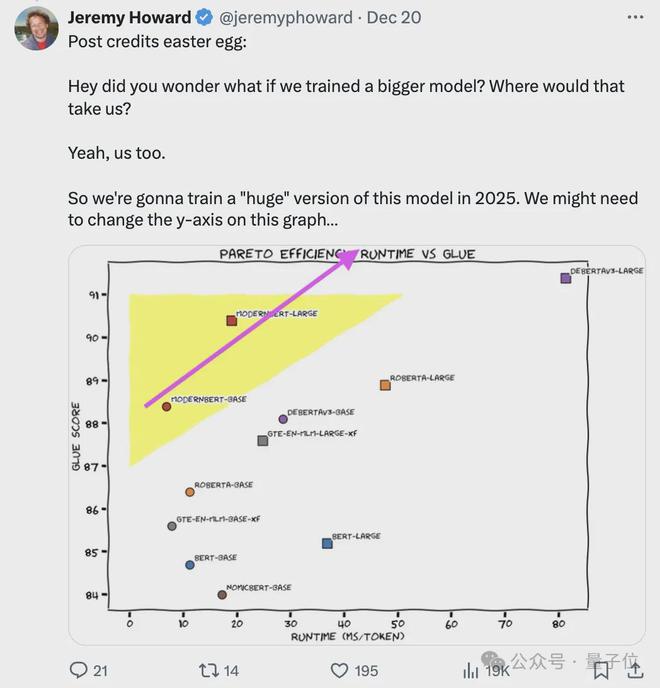
Jeremy Howard 表示明年将训练这个模型的更大版本。
Blog:https://huggingface.co/blog/modernbert
ModernBERT-Base:https://huggingface.co/answerdotai/ModernBERT-base
ModernBERT-Large:https://huggingface.co/answerdotai/ModernBERT-large






