
新智元报道
编辑:编辑部 HYZj
NeurIPS 2024 最佳论文终于正式揭晓了!今年,来自北大字节,以及新加坡国立大学等机构的团队摘得桂冠。
刚刚,NeurIPS 2024 最佳论文放榜了!

不出所料,今年两篇最佳论文分别颁给了,和新加坡国立大学 Sea AI Lab 团队。

除此之外,大会还公布了「数据集与基准」赛道的最佳论文,以及主赛道最佳论文奖委员会,数据集和基准赛道最佳论文奖委员会。

今年,是 NeurIPS 第 38 届年会,于 12 月 9 日-15 日在加拿大温哥华正式拉开帷幕。

前段时间,NeurIPS 2024 刚刚公布的时间检验奖,分别颁给了 Ilya Sutskever 的 Seq2Seq,和 Ian Goodfellow 的 GAN。
有网友发现,Ilya 已经连续三年拿下该奖,可以创历史了。
2022 年 AlexNet,2023 年 Word2Vec,2024 年 Seq2Seq
今年,NeurIPS 2024 的总投稿数量再创新高,共有 15000 多篇论文提交,录用率为 25.8%。
从研究内容主题的整体分布来看,主要集中在大模型、文生图/文生视频、强化学习、优化这四大块。
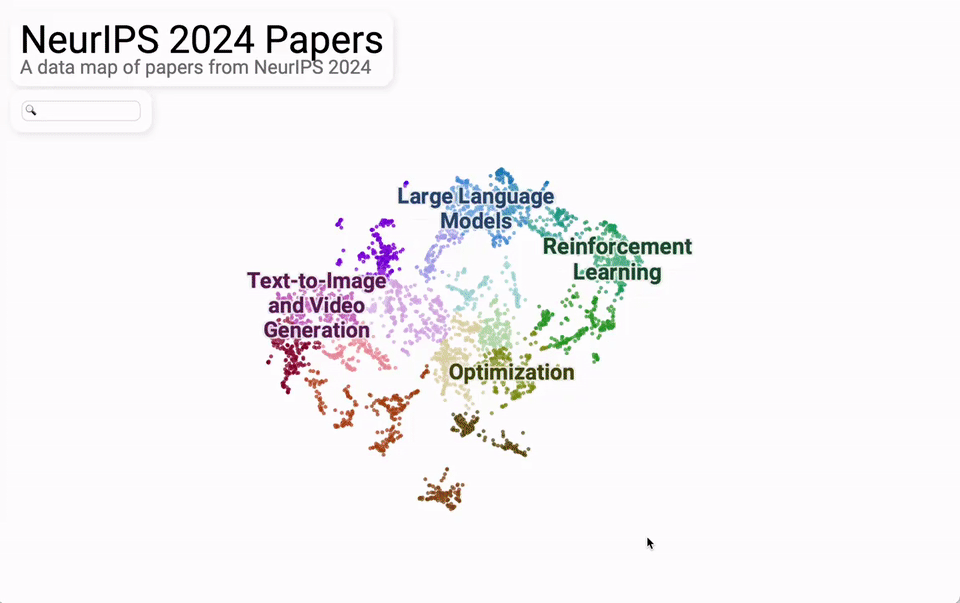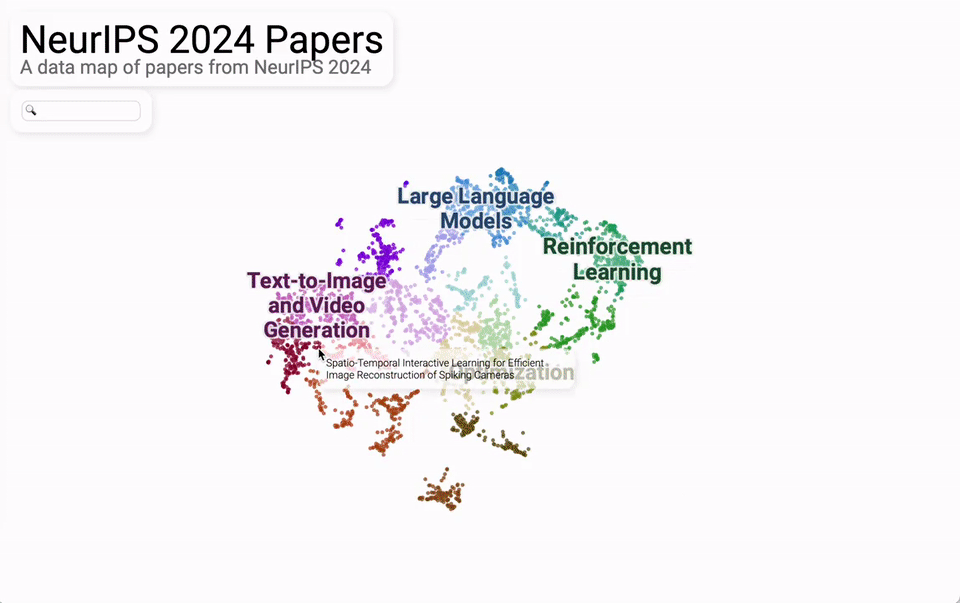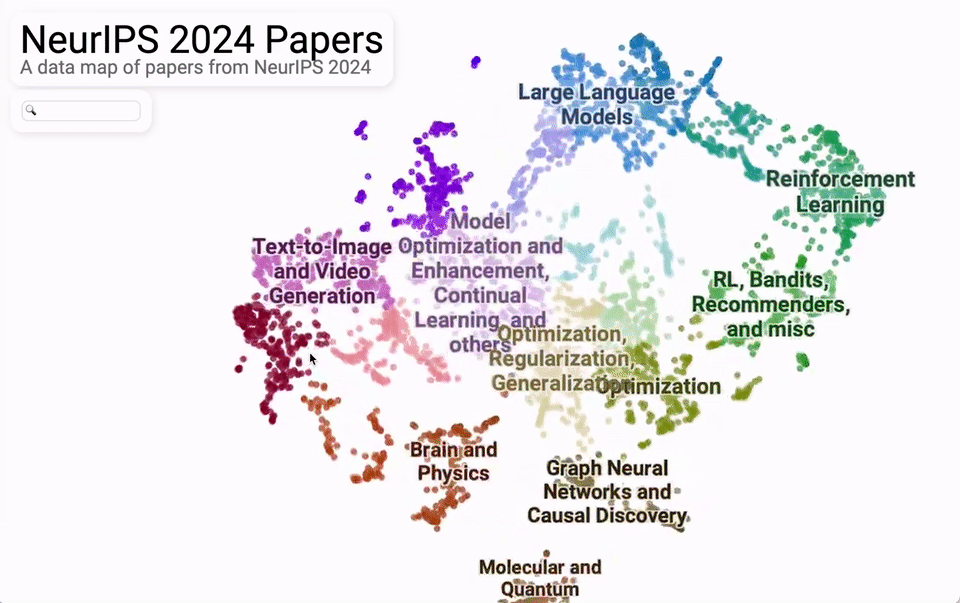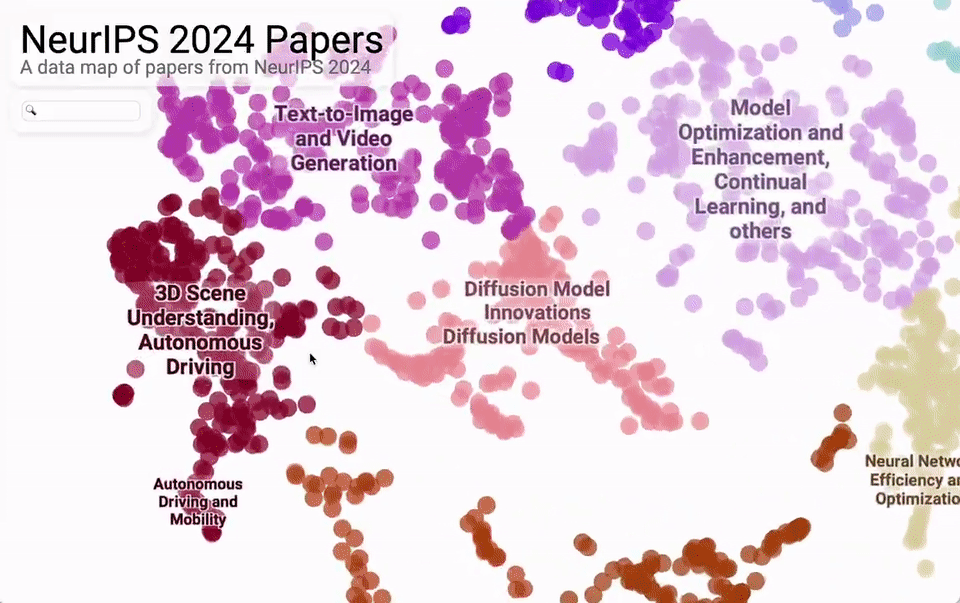
再细分来看,机器视觉、自然语言处理、强化学习、学习理论、基于扩散的模型是最热的 5 个话题。
共计 165000 名参会者,也创下历年新高。

获奖论文一:超越扩散,VAR 开启视觉自回归模型新范式

论文地址:https://arxiv.org/abs/2404.02905
与传统的光栅扫描「下一个 token 预测」方法有所不同,VAR 重新定义了图像上的自回归学习,采用粗到细的「下一个尺度预测」或「下一个分辨率预测」。
这种简单直观的方法使得自回归(AR)Transformer 能够快速学习视觉分布,并且具有较好的泛化能力:VAR 首次使得类似 GPT 的 AR 模型在图像生成中超越了扩散 Transformer。

首先,将图像编码为多尺度的 token 映射,然后,自回归过程从1×1token 映射开始,并逐步扩展分辨率。
在每一步中,Transformer 会基于之前所有的 token 映射去预测下一个更高分辨率的 token 映射。
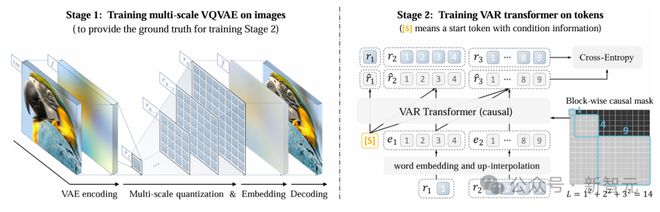
VAR 包括两个独立的训练阶段:在图像上训练多尺度 VQVAE,在 token 上训练 VAR Transformer。
第一阶段,多尺度 VQ 自动编码器将图像编码为K个 token 映射R=(r1,r2,…,rK),并通过复合损失函数进行训练。
第二阶段,通过下一尺度预测对 VAR Transformer 进行训练:它以低分辨率 token 映射 ([s],r1,r2,…,rK−1) 作为输入,预测更高分辨率的 token 映射 (r 1 ,r 2 ,r 3 ,…,r K )。训练过程中,使用注意力掩码确保每个 r k 仅能关注 r ≤k 。训练目标采用标准的交叉熵损失函数,用于优化预测精度。
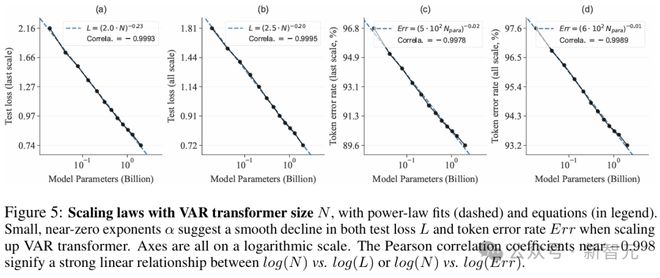
实验证明,VAR 在多个维度上超越了扩散 Transformer(DiT),包括图像质量、推理速度、数据效率和可扩展性。
其中,VAR 初步模仿了大语言模型的两个重要特性:Scaling Law 和零样本泛化能力。

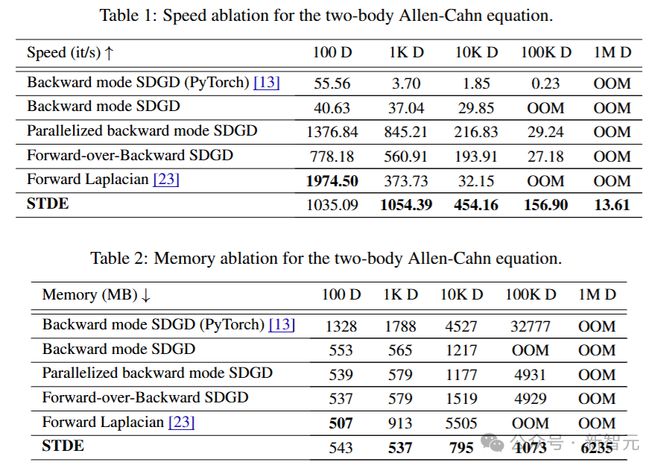
获奖论文二:STDE,破解高维高阶微分算子的计算难题
第二篇获奖论文,是由新加坡国立大学和 Sea AI Lab 提出的一种可通过高阶自动微分(AD)高效评估的分摊方案,称为随机泰勒导数估计器(STDE)。

论文地址:https://openreview.net/pdf?id=J2wI2rCG2u
这项工作讨论了优化神经网络在处理高维 (d) 和高阶 (k) 微分算子时的计算复杂度问题。
当使用自动微分计算高阶导数时,导数张量的大小随着O(dk)扩展,计算图的复杂度随着 O (2k-1L)增长。其中,d是输入的维度(域的维度),k是导数的阶数,L是前向计算图中的操作数量。
在之前的研究中,对于多维扩展 dk,使用的是随机化技术,将高维的多项式增长变为线性增长;对于高阶扩展 2k-1,则通过高阶自动微分处理了一元函数(即d=1)的指数增长问题。
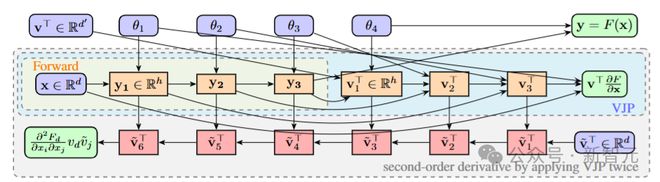
通过反向模式自动微分(AD)的重复应用,计算函数F(⋅)的二阶梯度的计算图。该函数包含 4 个基本操作(L=4),用于计算 Hessian 矩阵与向量的乘积。红色节点表示在第二次反向传播过程中出现的余切节点。随着向量-雅可比积(VJP)的每次重复应用,顺序计算的长度会加倍
在研究中,团队展示了如何通过适当构造输入切向量,利用一元高阶自动微分,有效执行多元函数导数张量的任意阶收缩,从而高效随机化任何微分算子。
该方法的核心思想是「输入切向量构造」。通过构造特定的「输入切向量」(方向导数),可以将多维函数的高阶导数计算转化为一元高阶自动微分问题。这意味着将复杂的多元导数运算转化为多个一元导数运算,从而减小了计算复杂度。
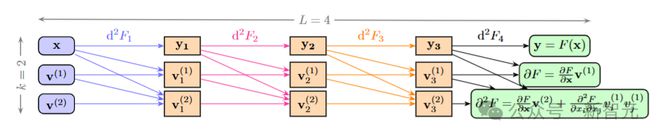
该计算图显示了函数F的二阶导数d²F,其中F包含 4 个基本操作,参数θi被省略。最左侧的第一列表示输入的二阶射流(2-jet) ,并通过d²F1 将其推向下一列中的二阶射流 。每一行都可以并行计算,且不需要缓存评估轨迹
将该方法应用于物理信息神经网络(PINNs)时,相较于使用一阶自动微分的随机化方法,该方案在计算速度上提高了 1000 倍以上,内存占用减少了 30 倍以上。
借助该方法,研究团队能够在一块 NVIDIA A100 GPU 上,在 8 分钟内求解具有百万维度的偏微分方程(PDEs)。
这项工作为在大规模问题中使用高阶微分算子开辟了新的可能性,特别是在科学计算和物理模拟中具有重要意义。
「数据集与基准」最佳论文
这篇由牛津、宾大等 12 家机构联手提出的数据集 PRISM,荣获了「数据集与基准」赛道的最佳论文。

论文地址:https://openreview.net/pdf?id=DFr5hteojx
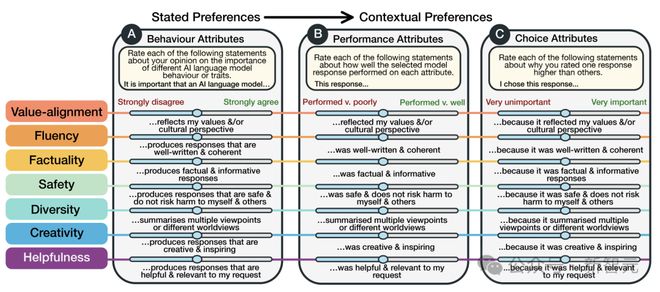
这篇论文通过收集来自 75 个国家、1500 多名参与者的详细反馈,科学家们首次全面绘制了 AI 模型与人类交互的复杂图景。
它就像是为 AI「验血」:不仅仅是检查技术指标,更是深入了解 AI 与不同文化、不同背景人群的交互细节。
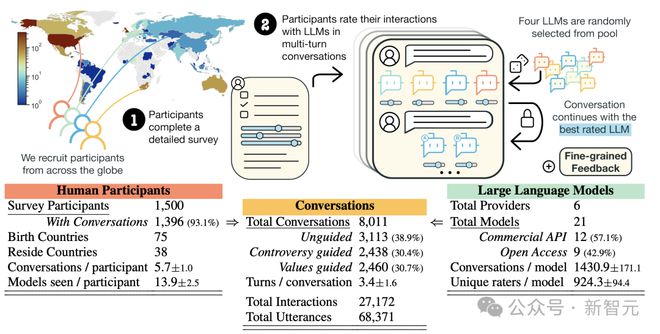
具体来说,研究人员收集了人们与 21 个大模型交互的8,011 次真实数据。
而且,他们还详细记录了参与者的社会人口学特征和个人偏好。
最关键的是,这项研究聚焦了主观和多文化视角中,最具挑战性领域,尤其是关注价值观相关和有争议问题上的主观和多元文化视角。
通过 PRISM 数据集,为未来研究提供了新的视角:
- 扩大地理和人口统计学的参与度
- 为英国、美国提供具有人口普查代表性的样本
- 建立了个性化评级系统,可追溯参与者详细背景
总的来说,这项研究具有重要的社会价值,并推动了关于 RLHF 中多元化和分歧的研究。
NeurIPS 2024 实验:LLM 作为科学论文作者清单助手的效果评估
随着大奖出炉后,NeurIPS 2024 终于公布了将大模型作为清单助手的效果评估报告。

如今,虽然存在着不准确性和偏见等风险,但 LLM 已经开始被用于科学论文的审查工作。
而这也引发了一个紧迫的问题:「我们如何在会议同行评审的应用中负责任且有效地利用 LLM?」
今年的 NeurIPS 会议,迈出了回答这一问题的第一步。

论文地址:https://arxiv.org/abs/2411.03417
具体来说,大会评估了一个相对明确且低风险的使用场景:根据提交标准对论文进行核查,且结果仅显示给论文作者。
其中,投稿人会收到一种可选择使用的基于 LLM 的「清单助手」,协助检查论文是否符合 NeurIPS 清单的要求。
随后,研究人员会系统地评估这一 LLM 清单助手的益处与风险,并聚焦于两个核心问题:
1. 作者是否认为 LLM 作者清单助手是对论文提交过程的一种有价值的增强?
2. 使用作者清单助手是否能显著帮助作者改进其论文提交?
最终结论如下:
「LLM 清单助手可以有效地帮助作者确保科学研究的严谨性,但可能不应作为一种完全自动化的审查工具来取代人工审查。」

1. 清单助手有用吗?
研究人员对作者们进行了问卷调查,以便了解他们对使用清单助手前后的期望和感受。
调查共收到 539 份使用前问卷回复,清单助手共处理了 234 份提交,同时收到了 78 份使用后问卷回复。
结果显示,作者普遍认为清单助手是对论文提交过程的一项有价值的改进——
大多数接受调查的作者表示,使用 LLM 清单助手的体验是积极的。其中,超过 70% 的作者认为工具有用,超过 70% 的作者表示会根据反馈修改论文。
值得注意的是,作者在实际使用之前对助手有效性的期望比实际使用后的评价更为积极。比较使用前后的反馈可以发现,在「有用性」和「期待使用」方面的正面评价出现了具有统计学意义的显著下降。

2. 清单助手的主要问题是什么?
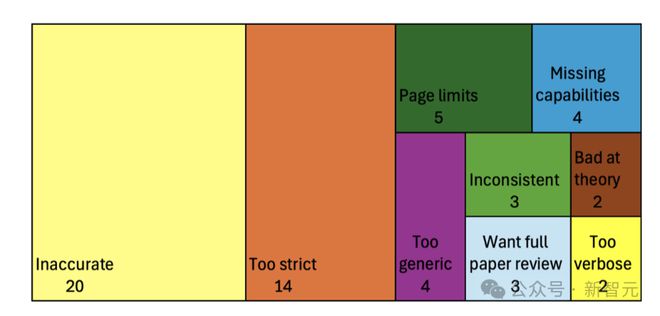
作者使用清单助手时遇到的问题,按类别归纳如下。
主要问题包括:不准确性(52 名回复者中有 20 人提到),以及 LLM 对要求过于苛刻(52 名回复者中有 14 人提到)。
3. 清单助手提供了哪些类型的反馈?
研究者使用了另一个 LLM,从清单助手对每个清单问题的回复中提炼关键点,将其归类。
以下展示了作者清单助手在清单的四个问题上提供的常见反馈类别:
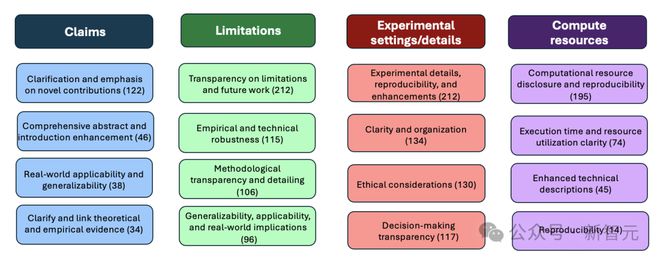
LLM 能够结合论文内容和清单要求,为作者提供具体的反馈。对于清单中的 15 个问题,LLM 通常会针对每个问题提供4-6 个不同且具体的反馈点。
尽管其回复中有时包含一些模板化内容,并可能扩展问题的范围,但它也能够针对许多问题提供具体且明确的反馈。
4. 作者是否真的修改了提交的内容?
根据反馈,很多作者表示计划对他们的提交内容做出实质性的修改。
在 78 名回复者中,有 35 人具体说明了他们会根据清单助手的反馈对提交内容进行的修改。其中包括,改进清单答案的说明,以及在论文中添加更多关于实验、数据集或计算资源的细节。
在 40 个实例中,作者将他们的论文提交到清单验证工具两次(总共提交了 80 篇论文)。
结果显示,在这 40 对(两次提交的)论文中,有 22 个实例中作者在第一次和第二次提交之间至少更改了清单中的一个答案(例如,从「NA」改为「是」),并且在 39 个实例中更改了至少一个清单答案的说明。
在更改了清单说明的作者中,许多作者进行了大量修改,其中 35/39 在清单的 15 个问题中更改了超过 6 个说明。
虽然并不能将这些修改因果归因于清单助手,但这些修改表明作者可能在提交之间采纳了助手的反馈。
以下是在作者更改说明的问题中,从初次提交到最终提交的字数增长情况(值为 2 表示答案长度增加了一倍)。
可以看到,当作者更改清单答案时,超过一半的情况下,他们将答案说明的长度增加了一倍以上。
总结来说,当作者多次向清单助手提交时,他们几乎都会在提交之间对清单进行修改,并显著延长了答案的长度,这表明他们可能根据 LLM 的反馈添加了内容。

5. 清单助手是否可以被操控?
清单助手的设计初衷,是帮助作者改进论文,而不是作为审稿人验证作者回答准确性的工具。
如果该系统被用作审稿流程中的自动验证步骤,这可能会激励作者「操控」系统,从而引发以下问题:作者是否可以借助 AI,在无需对论文做出实际修改的情况下,自动提升清单回答的评价?
如果这种操控是可能的,作者可能会在没有(太多)额外努力且不实际改进论文的情况下,向会议提供虚假的合规印象。
为了评估系统是否容易受到这种操控,研究者使用另一个 LLM 作为攻击智能体,迭代性地修改清单说明,试图误导清单助手。
在这一迭代过程中,攻击智能体在每轮之后从系统接收反馈,并利用反馈优化其说明。
研究者向 GPT-4 提供了初始的清单回答,并指示其仅根据反馈修订说明,而不改变论文的基础内容。允许攻击智能体进行三次迭代(与部署助手的提交限制一致),智能体在每次迭代中选择得分最高的清单问题回答。
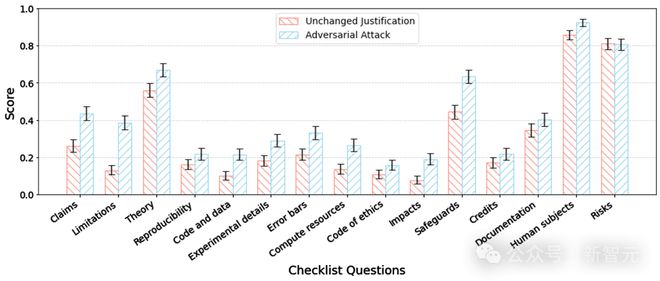
为了以统计方式量化这种攻击的成功率,研究者将选定的说明提交给清单助手进行评估,获取「评分」(当清单助手表示清单问题「无问题」时得分为1,当助手识别出问题时得分为0)。
以下展示了该攻击的结果:
结论
通过在 NeurIPS 2024 部署了一个基于 LLM 的论文清单助手,证明了 LLM 在提升科学投稿质量方面的潜力,特别是通过帮助作者验证其论文是否符合提交标准。
然而,研究指出了在科学同行评审过程中部署 LLM 时需要解决的一些显著局限性,尤其是准确性和契合度问题。
此外,系统在应对作者的操控时缺乏抵抗力,这表明尽管清单助手可以作为作者的辅助工具,但可能无法有效取代人工评审。
NeurIPS 将在 2025 年继续改进基于 LLM 的政策评审。
参考资料:
https://blog.neurips.cc/2024/12/10/announcing-the-neurips-2024-best-paper-awards/






