
新智元报道
编辑:LRS
Allen Institute for AI(AI2)发布了Tülu 3 系列模型,一套开源的最先进的语言模型,性能与 GPT-4o-mini 等闭源模型相媲美。Tülu 3 包括数据、代码、训练配方和评估框架,旨在推动开源模型后训练技术的发展。
只进行过「预训练」的模型是没办法直接使用的,存在输出有毒、危险信息的风险,也无法有效遵循人类指令,所以通常还需要进行后训练(post-train),如「指令微调」和「从人类反馈中学习」,以使模型为各种下游用例做好准备。
早期的后训练工作主要遵循 InstructGPT 等模型的标准方案,如指令调整(instruction tuning)和偏好微调(preference finetuning),不过后训练仍然充满玄学,比如在提升模型编码能力的同时,可能还会削弱模型写诗或遵循指令的能力,如何获得正确的「数据组合」和「超参数」,使模型在获得新知识的同时,而不失去其通用能力,仍然很棘手。
为了解决后训练难题,各大公司都提升了后训练方法的复杂性,包括多轮训练、人工数据加合成数据、多训练算法和目标等,以同时实现专业知识和通用功能,但这类方法大多闭源,而开源模型的性能又无法满足需求,在 LMSYS 的 ChatBotArena 上,前 50 名模型都没有发布其训练后数据。
最近,Allen Institute for AI(AI2)发布了一系列完全开放、最先进的训练后模型Tülu 3,以及所有数据、数据混合、配方、代码、基础设施和评估框架,其突破了训练后研究的界限,缩小了开源模型和闭源模型微调配方之间的性能差距。

论文链接:https://allenai.org/papers/tulu-3-report.pdf
TÜLU 3-70B:https://hf.co/allenai/Llama-3.1-Tulu-3-70B
TÜLU 3-8B:https://hf.co/allenai/Llama-3.1-Tulu-3-8B
TÜLU 3 数据:https://hf.co/collections/allenai/tulu-3-datasets673b8df14442393f7213f372
TÜLU 3 代码:https://github.com/allenai/open-instruct
TÜLU 3 评估:https://github.com/allenai/olmes
Demo:https://playground.allenai.org/
模型训练算法包括有监督式微调(SFT)、直接偏好优化(DPO)以及可验证奖励强化学习(RLVR)
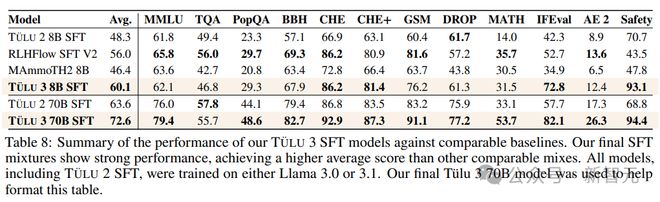
TÜLU 3 基于 Llama 3.1 的基础模型构建,其性能超越了 Llama 3.1-instruct、Qwen 2.5、Mistral,甚至超越了如 GPT-4o-mini 和 Claude 3.5-Haiku 等模型。
TÜLU 3 的训练过程结合了强化学习的新算法、前沿的基础设施和严格的实验,构造数据,优化不同训练阶段的数据混合、方法和参数,主要包括四个阶段。
第一阶段:数据构造
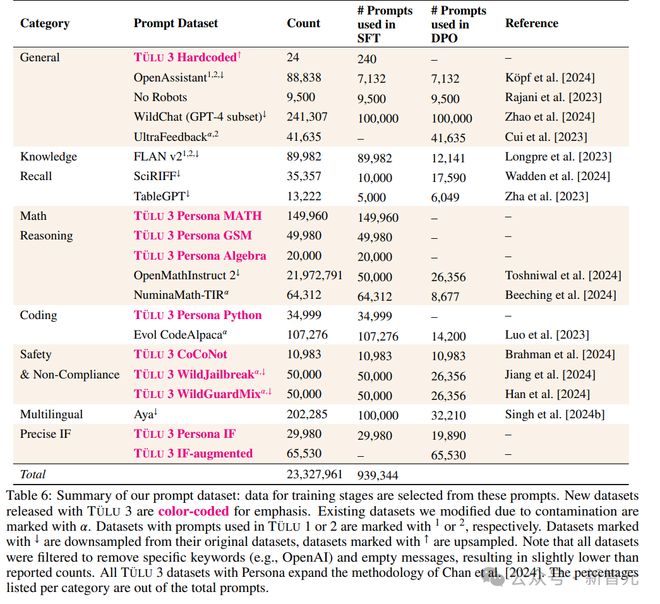
研究人员主要关注模型在知识召回(knowledge recall)、推理、数学、编程、指令遵循、普通聊天和安全性等核心通用技能,然后根据目标需求来收集人工数据和合成数据。
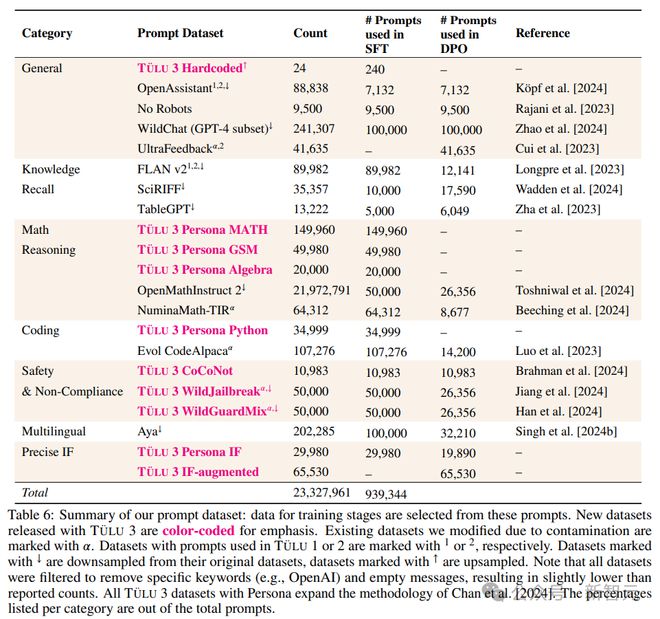
第二阶段:监督微调(SFT)
研究人员在精心选择的提示和完成内容上执行监督式微调(SFT),首先确定了在使用 Llama 3.1 模型训练在TÜLU 2 数据集上作为基准时,哪些技能落后于最先进的模型,然后有针对性地收集高质量的公开数据集和合成数据集。
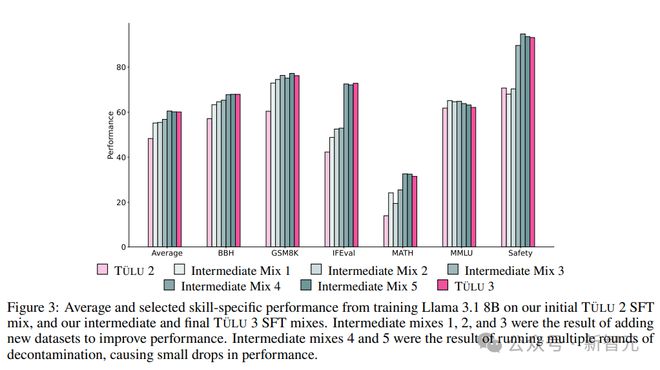
通过一个完善的实验,确定了最终 SFT 数据和训练超参数,以增强目标核心技能,同时不会显著影响其他技能的性能。
关键的数据实验包括:
1. 多样化的聊天数据:主要来自 WildChat,如果移除该数据集,可以看到大多数技能都有小幅但明显的下降,尤其是在 Alpaca Eval 上,凸显了「多样化真实世界数据」的重要性。
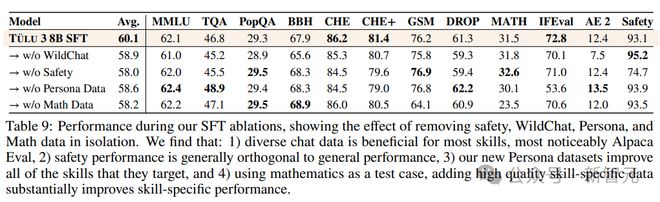
2. 安全性是独立的:移除特定安全数据集后,可以看到大多数技能的结果大致保持不变;添加对比提示,如 CoCoNot,有助于防止模型过度拒绝安全提示。
3. 新的 Persona Data,主要针对数学、编程和指令遵循进行构建,移除后,HumanEval (+)、GSM8K、MATH 和 IFEval 的性能都会显著下降。
4. 针对特定技能(Targeting Specific Skills),移除所有数学相关数据后,GSM8K 和 MATH 都有显著下降。
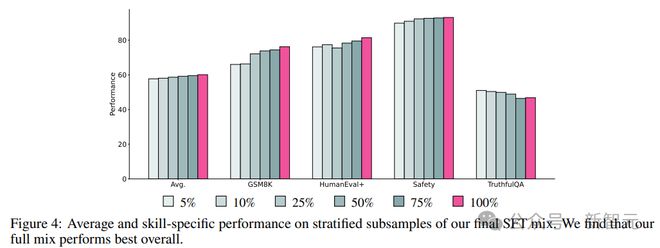
5. 智能体训练数据的数量,可以发现,在不断增加数据集规模时,模型平均性能持续提高,增加到完整混合数据集后,GSM8K 等指标上的性能大幅提升,但 TruthfulQA 的性能下降了。
第三阶段:偏好调整
研究人员主要使用直接偏好优化(DPO),针对新构造的、基于策略的合成偏好数据,以及从选定提示中获得的离策略数据。与 SFT 阶段一样,我们通过彻底的实验确定了最佳的偏好数据混合,揭示了哪些数据格式、方法或超参数能带来改进。
在TÜLU 3 项目中,研究人员探索了多种偏好微调方法,目标是提升整个评估套件的性能;并研究了多种训练算法,从直接偏好优化(DPO)及其衍生算法到强化学习算法,比如近端策略优化(PPO)。
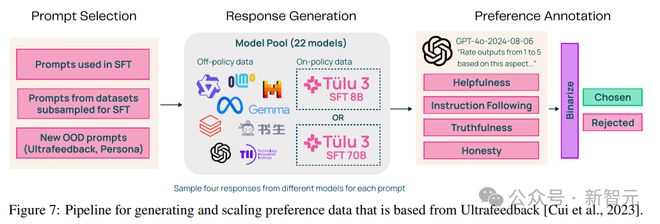
研究人员通过改进和扩展 UltraFeedback 流程,从提示中创建了策略内偏好数据(包括输入、两个输出选项和标签),使用大型语言模型(LLM)作为裁判,构造「偏好的、被拒绝的」数据对,主要包括三个阶段:
1. 提示选择
除了数据构造阶段的提示外,还包括了其他来源的提示,比如没有 TruthfulQA 实例的 Ultrafeedback 版本,或者通过在提示中添加新的 IF 约束。
2. 生成回复
对于给定的提示,从模型池中随机抽取四个模型来生成回复,再通过从TÜLU SFT 模型中抽样完成情况来包括策略内数据。其中一个回应是由策略内模型生成的,另一个回应是由策略外模型生成的。
3. 偏好标注
在为每个提示生成四个回复后,使用一个大型语言模型(LLM)作为裁判(GPT-4o-2024-0806),然后根据四个不同的方面(有帮助性、遵循指令、诚实性和真实性)对每个回复从 1 到 5 进行评分。
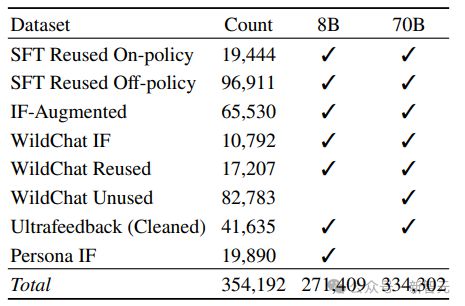
第四阶段:可验证奖励的强化学习
研究人员引入了一种名为可验证奖励强化学习(RLVR)的新型方法,用于训练语言模型完成具有可验证结果的任务,比如数学问题解决和指令遵循。
RLVR 基于现有的强化学习人类反馈(RLHF)目标,但将奖励模型替换为验证函数,当应用于具有可验证答案的领域,其在 GSM8K 等基准测试上显示出针对性的改进,同时还能保持其他任务的性能。
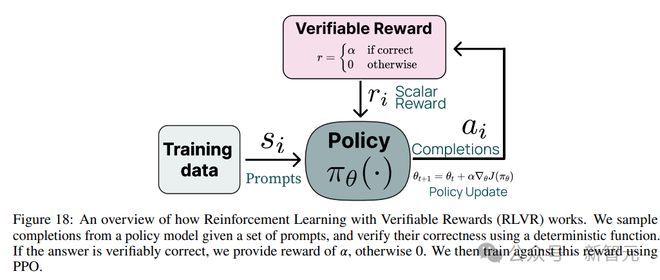
RLVR 可以看作是现有引导语言模型推理的方法的简化形式,或者是一种更简单的强化学习形式,其中使用答案匹配或约束验证作为二元信号来训练模型。
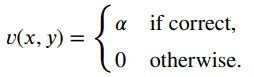
RLVR 数据主要包括两个领域(数学、精确指令遵循),评估数据集为 GSM8k, MATH 和 IFEval
为了提升效率,RLVR 的实现细节主要包括:
1. 用通用奖励模型来初始化价值模型;
2. 禁用 dropout,在奖励模型和强化学习训练期间,将 dropout 概率设置为0,确保在策略模型和参考模型的前向传递过程中,token 的对数概率可以确定性地计算,从而更准确地估计 KL 惩罚。此外,PPO 在滚动阶段和学习阶段计算 token 的对数概率,重要的是要确保这两个阶段的 token 对数概率相匹配,如果使用 dropout,对数概率差异会很大,导致裁剪后梯度为零。
3. 使用智能体训练数据集并在周期之间随机,PPO 可以训练的周期数超过可用提示的总数,有效地进行多个周期的训练。在我们的 RLVR 消融实验中,我们大约训练了 13 个周期。我们在周期之间对提示进行洗牌。对于我们的最终运行,我们每 40-100 步检查一次模型检查点,并选择在我们开发评估集上表现最佳的检查点。
4. 非序列结束(EOS)惩罚:在训练期间,PPO 通常采样固定数量的最大 token。如果采样的回复没有以 EOS token 结束,给予-10 的惩罚。
5. 优势归一化:过减去均值然后除以其标准差来归一化优势(advantages)。
研究人员首先将一个直接偏好优化(DPO)模型作为初始模型,然后进行了一系列消融实验:
1. 单独任务。分别在 GSM8K、MATH 和 IFEval 任务上应用了 RLVR 方法,并遍历了一系列 beta 值。在评估时,关注可验证的奖励、KL 散度和回应长度。
2. 价值模型初始化消融实验。尝试从一个通用奖励模型和锚定的 DPO 模型初始化 PPO 的价值模型,并在 GSM8K 任务上遍历一系列 beta 值。通用奖励模型是使用 UltraFeedback 数据集训练的。在评估时,检查 GSM8K 测试评估得分和所有评估的平均得分。
3. 从奖励模型得分的消融实验。在奖励模型的得分基础上增加可验证的奖励,并在 GSM8K 任务上使用了一系列 beta 值进行实验。
4. 从性能较弱的模型开始。模型的基础能力也是一个干扰因素,使用平均得分较低的 SFT 模型进行另一组实验。
TÜLU 3 评估
在后续训练方法中,建立清晰的性能目标和评估工具非常关键。
研究人员发布了一个统一的标准化评估套件和一个工具包,以指导开发和评估最终模型,并对训练数据进行净化,以符合评估基准,主要目标包括:
1. 评估过程应该是可复现的;
2. 应该评估模型对未见任务的泛化能力,而不仅仅是我们用于开发的特定基准测试。
3. 评估设置(例如,提示的模板和策略)对各种模型公平。
开放语言模型评估系统(OLMES)
为了使评估更加标准化和可复现,研究人员开源了 Open Language Model Evaluation System,其支持更广泛的模型集合和任务、可以对每个任务进行灵活配置、直接访问任务描述、分析模型预测、置信度等的详细实例级的数据。
比如说,要复现 Llama-3.1-8B-Instruct 在 MMLU-Pro 上的结果,只需简单运行类似「olmes –task mmlu_pro::tulu3 –model llama3.1-8b-instruct」的命令。
参考资料:
https://venturebeat.com/ai/ai2-closes-the-gap-between-closed-source-and-open-source-post-training/






