
新智元报道
编辑:Aeneas 好困
谷歌 DeepMind 最新基础世界模型 Genie 2 登场!只要一张图,就能生成长达 1 分钟的游戏世界。从此,我们将拥有无限的具身智能体训练数据。更有人惊呼:黑客帝国来了。
就在刚刚,谷歌 DeepMind 的第二代大规模基础世界模型 Genie 2 诞生了!

从此,AI 可以生成各种一致性的世界,最长可玩 1 分钟。
谷歌研究人员表示,相信 Genie 2 可以解锁具身智能体的下一波能力。

![]()
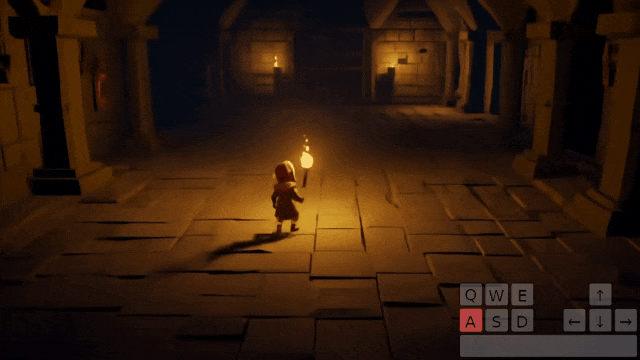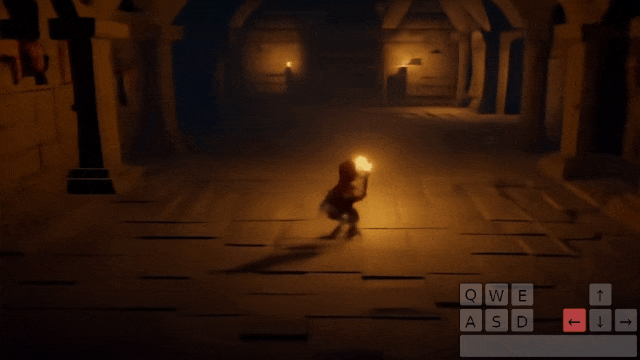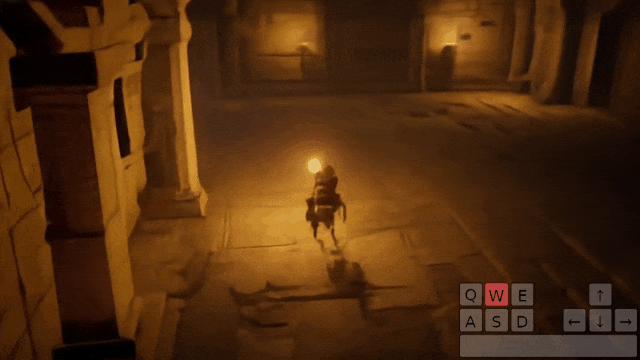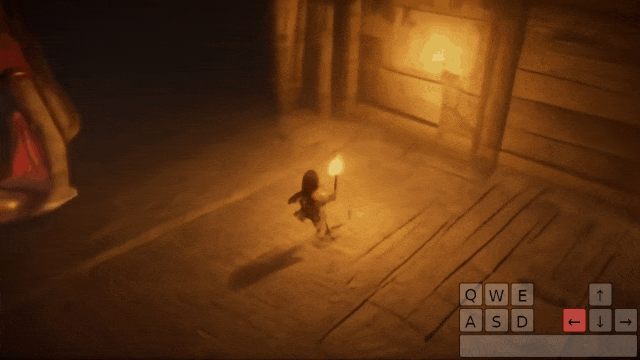
从第一人称的真实世界场景,到第三人称的驾驶环境,Genie 2 生成了一个 720p 的世界。
给定一幅图像,它就能模拟出世界动态,创建一个可通过键盘和鼠标输入的、可操作的一致环境。
具身智能体的潜力有多大?
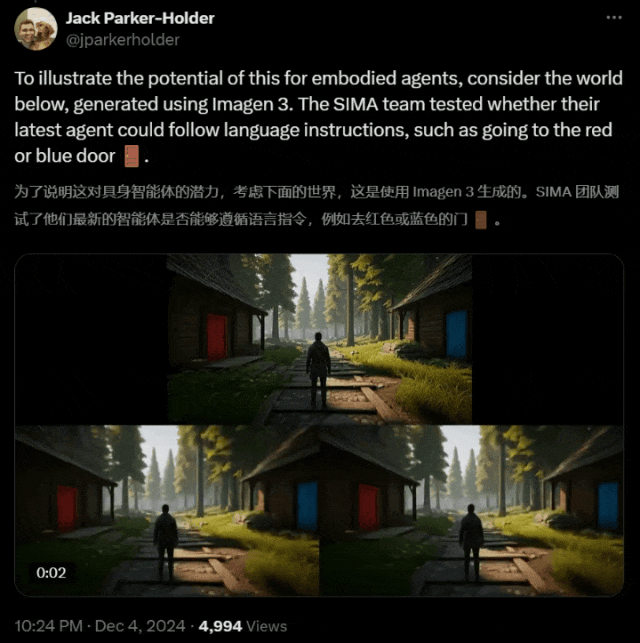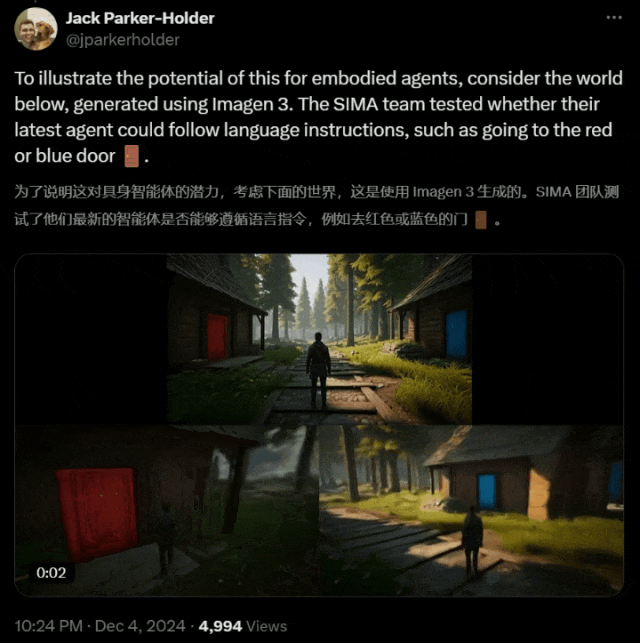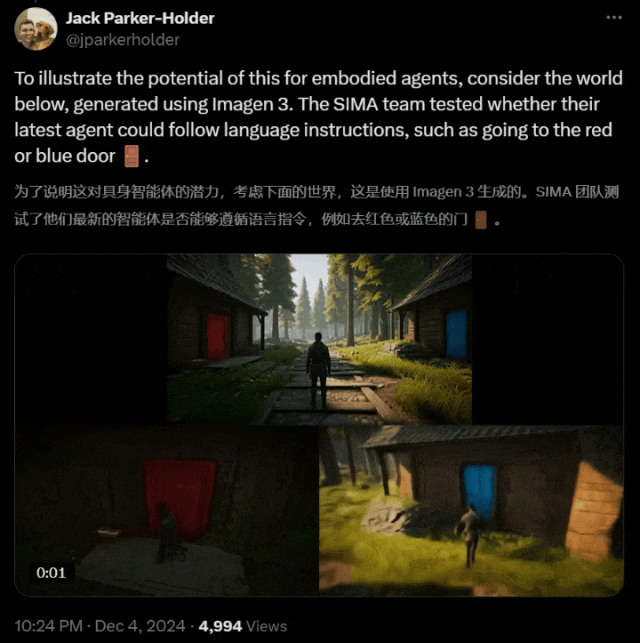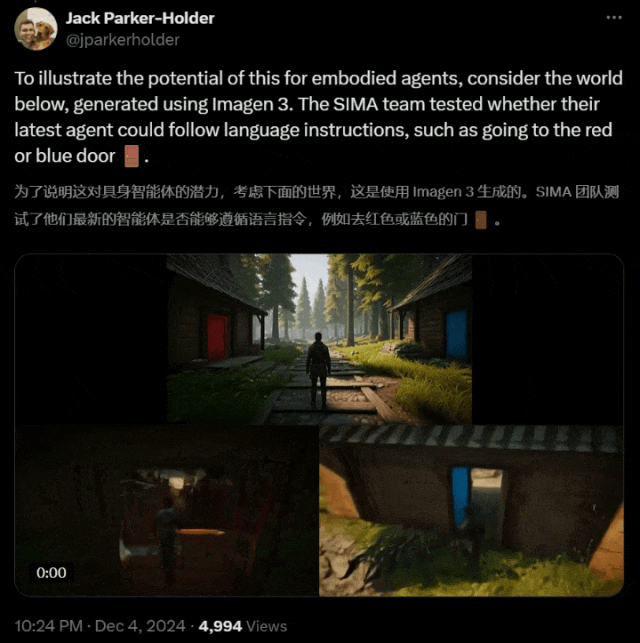
在以下这个 Imagen 3 生成的世界中,研究者测试出最新的智能体是否可以遵循语言指令,走到红门或蓝门。
结果令人惊喜!
就这样,现在我们拥有了一条通往无限环境的道路,来训练和评估具身智能体了。
研究者创造了一个有 3 个拱门的世界后,Genie 2 再次模拟了这个世界,让团队解决了任务。

对此,网友们纷纷表示赞叹:」这项工作实在是太棒了!今后,我们终于可以将开放式智能体与开放世界模型结合起来。我们正在朝着近乎无限的训练数据体系迈进。」
还有网友表示:「黑客帝国」的世界,要来了!
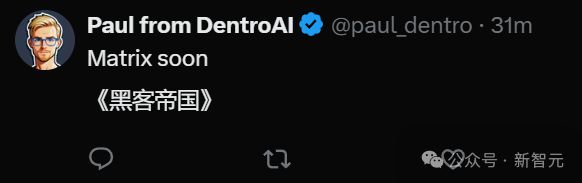
为未来的通用智能体,生成无限多样的训练环境
作为一种基础世界生成模型,Genie 2 能生成无限多样的、可操控且可玩的 3D 环境,用于训练和评估具身智能体。
基于一张提示词图像,它就可被人类或 AI 智能体操作了!方式是使用键盘和鼠标输入。
在 AI 研究中,游戏一直扮演着至关重要的角色。因为具有以引人入胜的特性、独特的挑战组合以及可衡量的进展,游戏成为了安全测试和提升 AI 能力的理想环境。
自 Google DeepMind 成立以来,游戏一直都是研究的核心——从早期的 Atari 游戏研究,到 AlphaGo 和 AlphaStar 等突破性成果,再到与游戏开发者合作研究通用智能体。
然而,训练更通用的具身智能体,却因缺乏足够丰富和多样化的训练环境而受到限制。
但现在,Genie 2 的诞生改变了一切。
从此,未来的智能体可以在无限的新世界场景中进行训练和评估了。
交互式体验原型设计的新型创意工作流程,也有了全新的可能性。
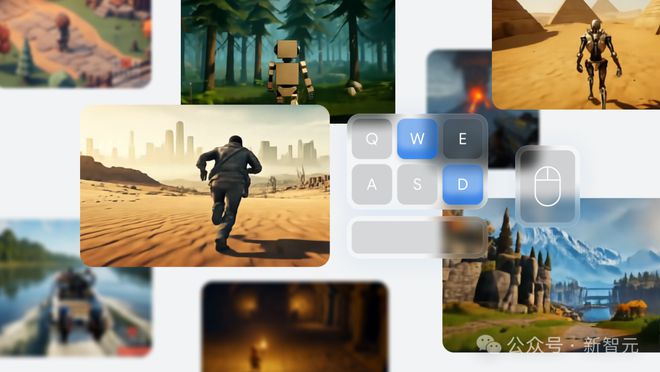
基础世界模型的涌现能力
迄今为止,世界模型在很大程度上都受限于对狭窄领域的建模。
在 Genie 1 中,研究人员引入了一种生成多样化二维世界的方法。
而到了 Genie 2 这一代,在通用性上实现了重大突破——它能生成丰富多样的 3D 世界了。
Genie 2 是一种世界模型,这就意味着,它可以模拟虚拟世界,包括采取任何行动(如跳跃、游泳等)的后果。
基于大规模视频数据集进行训练后,它像其他生成式 AI 模型一样,展现出了各种规模的涌现能力,例如物体交互、复杂的角色动画、物理效果、建模、预测其他智能体行为的能力等等。
对于每个人类与 Genie 2 互动的 demo,模型都以由 Imagen 3 生成的单张图片作为提示词输入,
这就意味着,任何人都可以用文字描述自己想要的世界,选择自己喜欢的渲染效果,然后进入这个新创建的世界,并且与之互动(或者,也可以让 AI 智能体在其中被训练或评估)。
每一步,人或智能体都能通过键盘和鼠标提供动作,而 Genie 2 会模拟下一步的观察结果。
在长达一分钟的时间里,Genie 2 可以生成一个一致的世界,持续时间直接长达 10-20 秒!
动作控制
Genie 2 能够智能响应通过键盘按键采取的动作,识别角色并正确移动。
例如,模型必须计算出,箭头键应该移动机器人,而不是移动树木或云朵。

一个在树林中的可爱的人形机器人

一个在古埃及的人形机器人

在紫色的星球上,以机器人第一人称视角观察

在现代都市的公寓中,以机器人第一人称视角观察
生成反事实
Genie 2 能够基于同一个开始画面,创造出多个不同的发展。
这意味着我们可以为 AI 训练提供各种「如果这样做会怎样」的场景。
在下面 demo 中,每个视频都会从完全相同的画面开始,但人类玩家会选择不同行动。

长时间记忆
Genie 2 能够记住那些暂时离开画面的场景,并在它们重新进入视野时,精确地还原出来。



持续生成新场景
Genie 2 能在过程中实时创造出符合逻辑的新场景内容,并且可以在长达一分钟的时间内保持整个世界的一致性。
![]()
![]()
多样化环境
Genie 2 能够生成多种不同的观察视角,比如第一人称视角、等距视角(45 度俯视角)或第三人称驾驶视角。



3D 结构
Genie 2 能够创建复杂的 3D 视觉场景。

物体属性与交互
Genie 2 能够建模各种物体交互,例如气球爆裂、开门和射击炸药桶。



角色动画
Genie 2 能够为不同类型的角色,制作各种动作的动画。



NPC
Genie 2 能够为其他智能体建模,甚至与它们进行复杂交互。



物理效果
Genie 2 能够模拟出水面的动效。


烟雾
Genie 2 能够模拟烟雾的效果。


重力
Genie 2 能够模拟重力。


光照
Genie 2 能够模拟点光源和方向光。

反射
Genie 2 能够模拟反射、泛光和彩色光照。


基于真实图像的模拟
Genie 2 还可以将真实世界的图像作为提示词输入,并模拟出草叶在风中摇曳或河水流动等场景。


快速创建测试原型
有了 Genie 2,制作多样化的交互场景就变得简单了。
研究人员可以快速尝试新环境,来训练和测试具身 AI 智能体。
例如,下面就是研究人员向 Genie 2 输入 Imagen 3 生成的不同图像,来模拟操控纸飞机、飞龙、猎鹰或降落伞等不同的飞行方式。
在这个过程中,也同时测试了 Genie 处理不同控制对象动作时的表现。

凭借强大的离散泛化能力,Genie 2 可以将概念设计图和手绘草图转化为可实际交互的场景。
从而让艺术家和设计师能够快速验证创意,提升场景设计的效率,并加快相关研究的进度。
以下是由概念设计师创作出的一些虚拟场景示例。

AI 智能体在世界模型中行动
借助 Genie 2,研究人员能够快速构建出丰富多样的虚拟环境,并创造全新的评估任务,来测试 AI 智能体在从未接触过的场景中的表现。
下面这个 demo,就是由谷歌 DeepMind 与游戏开发者共同开发的 SIMA 智能体,它能够在 Genie 2 仅通过一张图片生成的全新环境中,准确理解并完成各种指令。

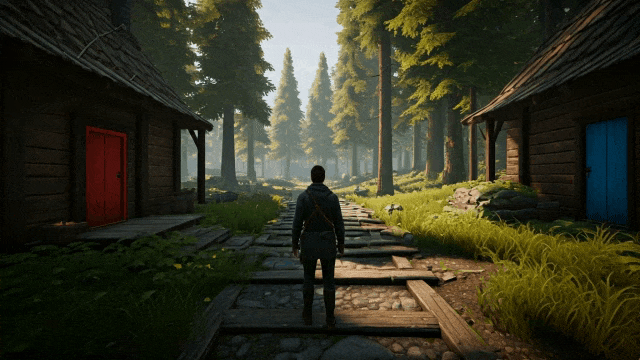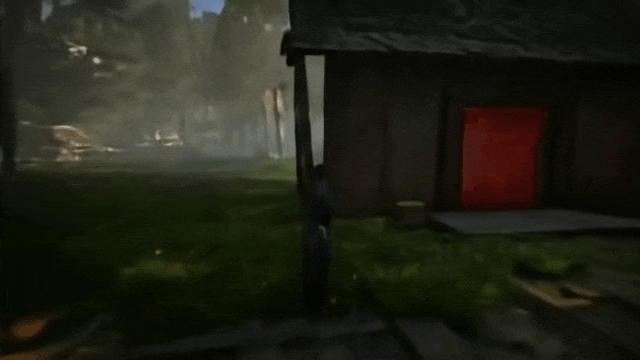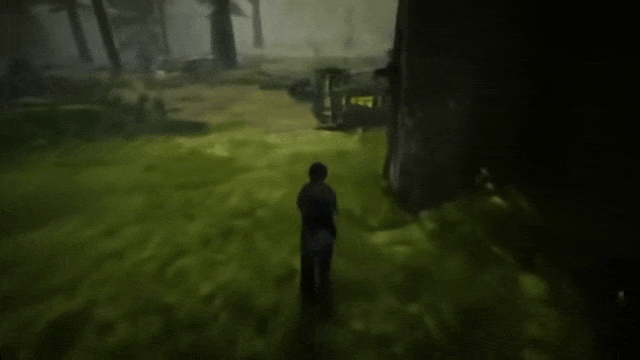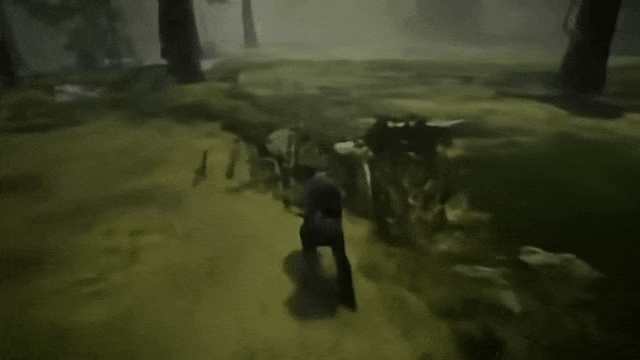
prompt:一张第三人称开放世界探索游戏的截图。画面中的玩家是一名在森林中探索的冒险者。左边有一座红门的房子,右边有一座蓝门的房子。镜头正对着玩家的身后。#写实风格 #身临其境
SIMA 智能体的目标是,能够在多样化的 3D 游戏环境中,通过自然语言指令完成各种任务。
在这里,团队使用 Genie 2 生成了一个包含两扇门(蓝色和红色)的 3D 环境,并向 SIMA 智能体提供了打开每扇门的指令。
过程中,SIMA 通过键盘和鼠标来控制游戏角色,而 Genie 2 负责实时生成游戏画面。

打开蓝色的门
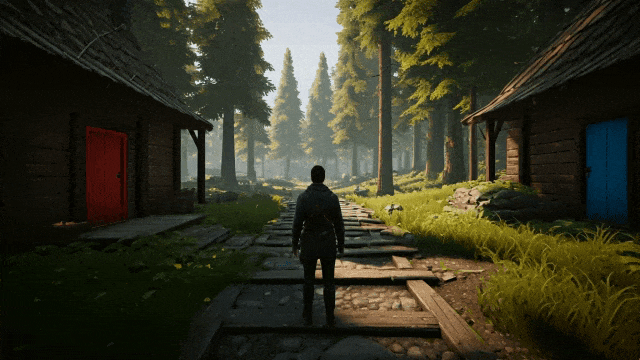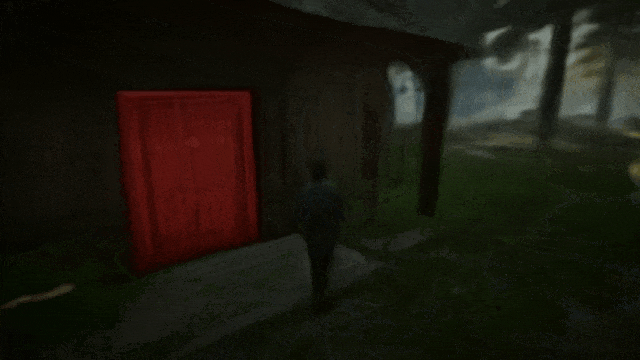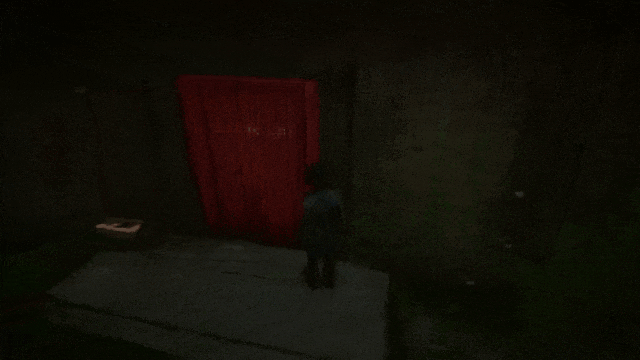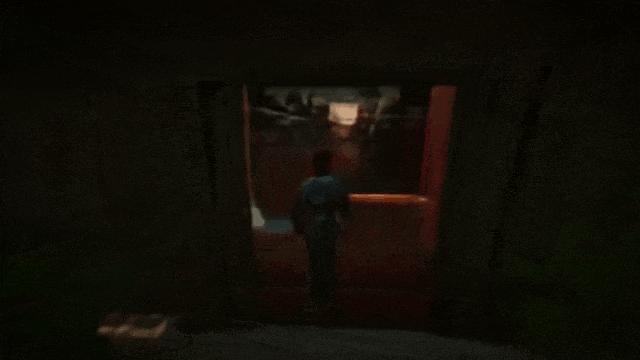
打开红色的门
不仅如此,我们还可以借助 SIMA 来评估 Genie 2 的各项能力。
比如,通过让 SIMA 在场景中四处查看并探索房屋背后的区域,测试 Genie 2 是否能够生成一致性的环境。
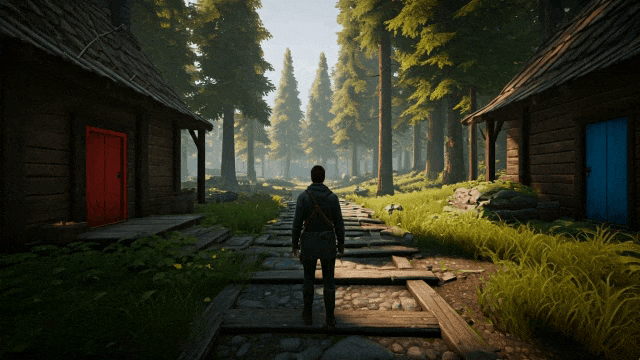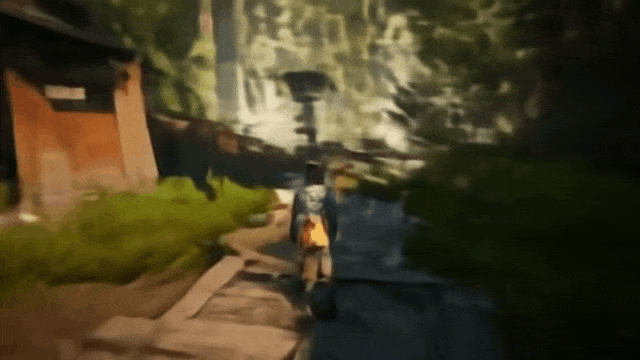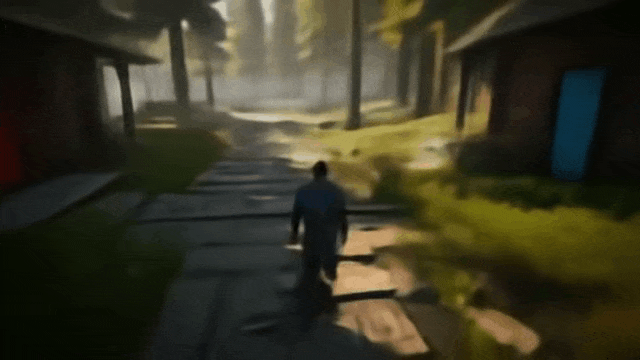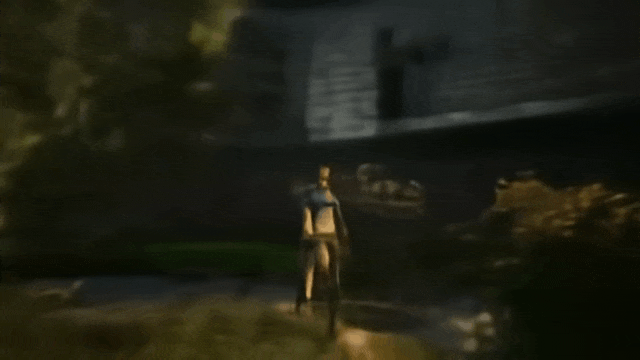
转身
去房子后面
尽管这项研究还处于起步阶段,无论是 AI 智能体的表现,还是环境的生成都还有待提升。
但研究人员认为,Genie 2 是解决安全训练具身智能体这一结构性问题的路径,同时也能够实现通向通用人工智能(AGI)所需的广度和通用性。

prompt:一个电脑游戏场景,展示了一座粗犷的石洞或矿洞内部。画面采用第三人称视角,镜头在主角上方俯视着。主角是一位手持长剑的骑士。骑士面前矗立着三座石砌的拱门,他可以选择进入任一道门。透过第一扇门,可以看到隧道内生长着散发荧光的奇异绿色植物。第二扇门后是一条长廊,洞壁上布满了铆接的铁板,远处隐约透出令人不安的光芒。第三扇门内则是一段粗糙的石阶,蜿蜒通向未知的高处。

走上楼梯
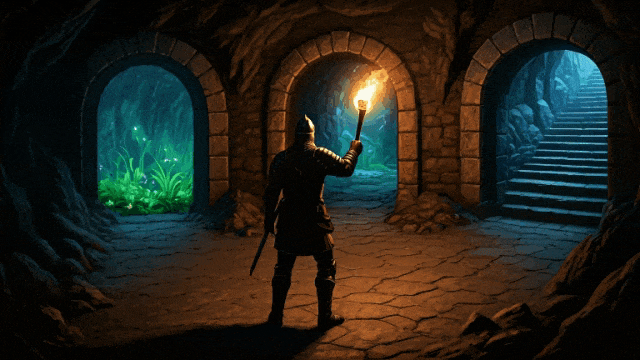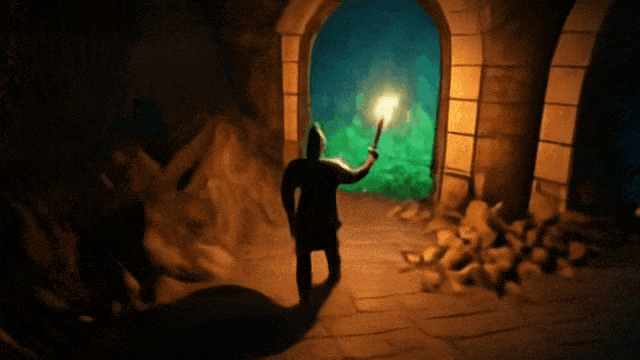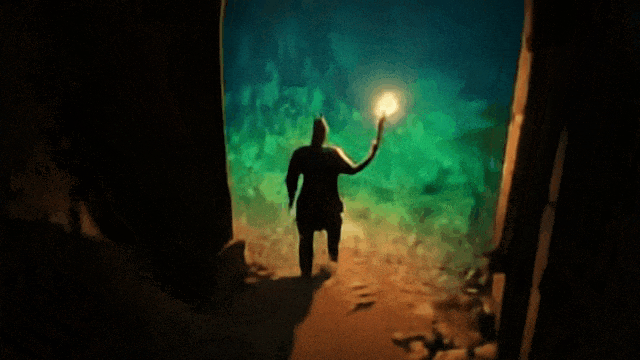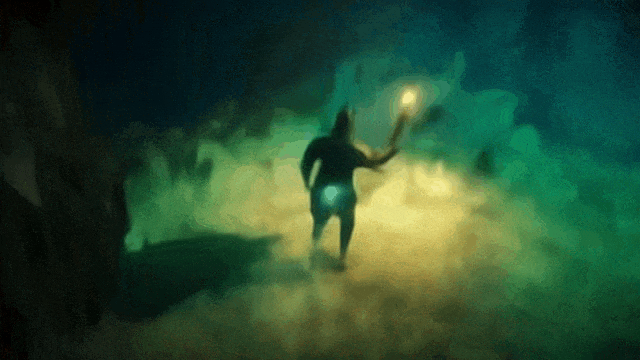
去有植物的地方

去中间的门
扩散世界模型
Genie 2 是一种基于大规模视频数据集训练的自回归潜变量扩散模型。
其中,视频的潜变量帧首先先会由自动编码器进行处理,然后被传递给一个基于类似 LLM 中因果掩码训练的大规模 Transformer 动态模型。
在推理阶段,Genie 2 可以以自回归的方式进行采样,逐帧利用单个动作和先前的潜变量帧。期间,无分类器指导(classifier-free guidance)会被用于提高动作的可控性。
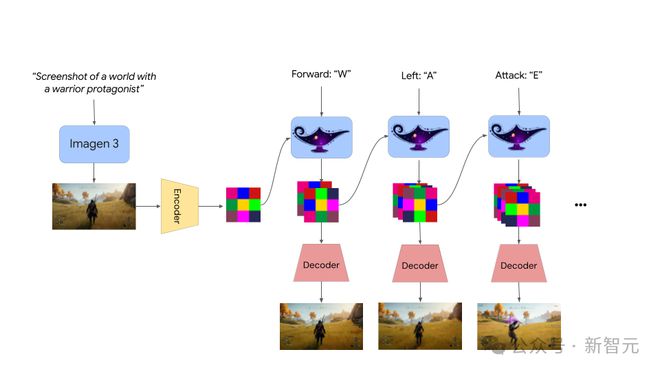
值得注意的是,上文中的演示均由未经蒸馏的「满血版」基础模型生成,从而充分地展示技术潜在的能力。
当然,也可以实时运行经过蒸馏的版本(distilled version),但输出质量会相应降低。
花絮
除了这些酷炫的 demo 之外,团队还在生成过程中发现了很多有意思的花絮:
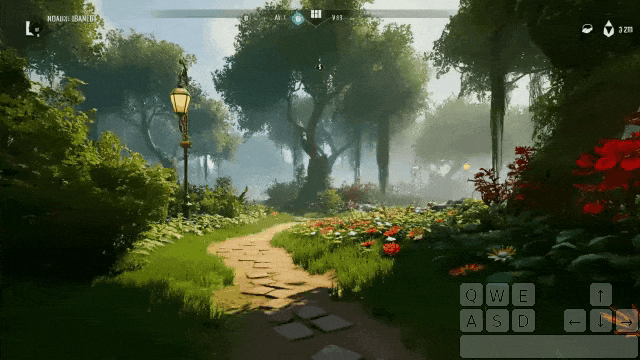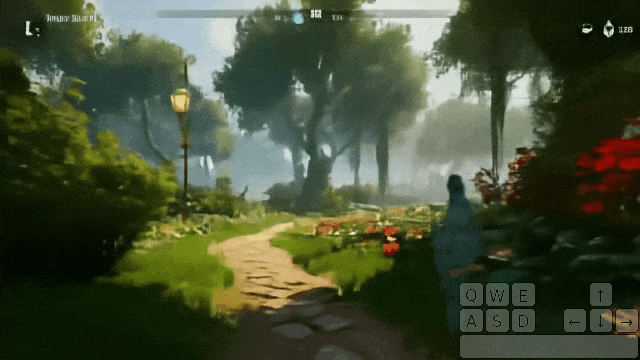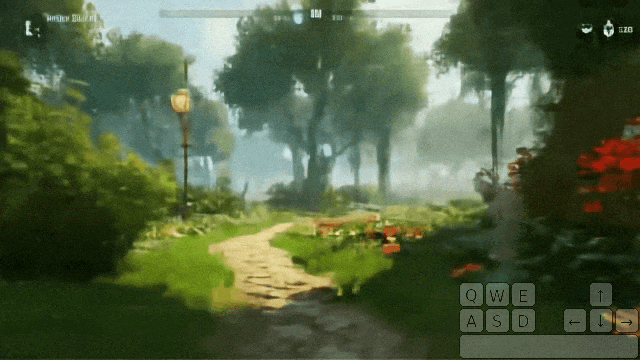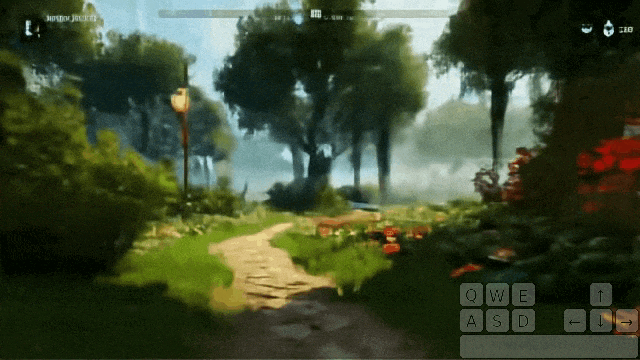
在花园里站着发呆,突然间,一个幽灵出现了

这位朋友更喜欢在雪场里跑酷,而不是老老实实地用滑雪板滑雪

能力越大,责任越大
致谢
最后,谷歌 DeepMind 团队放出了一个长长的致谢名单。

参考资料:
https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/






