
AIxiv 专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心 AIxiv 专栏接收报道了 2000 多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
此项研究成果已被 NeurIPS 2024 录用。该论文的第一作者是杜克大学电子计算机工程系的博士生张健一,其主要研究领域为生成式 AI 的概率建模与可信机器学习,导师为陈怡然教授。
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。
针对这一问题,来自杜克大学和 Google Research 的研究团队提出了一种新的解码框架 —— 自驱动 Logits 进化解码(SLED),旨在提升大语言模型的事实准确性,且无需依赖外部知识库,也无需进行额外的微调。

- 论文地址:https://arxiv.org/pdf/2411.02433
- 项目主页:https://jayzhang42.github.io/sled_page/
- Github 地址:https://github.com/JayZhang42/SLED
- 作者主页:https://jayzhang42.github.io
研究背景与思路总结
近期相关研究显示,尽管用户在访问大语言模型(LLM)时可能无法得到正确的答案,但 LLM 实际上可能已经基于海量的训练数据和漫长的训练周期学到了正确的答案,并将其存储于模型内部某处。
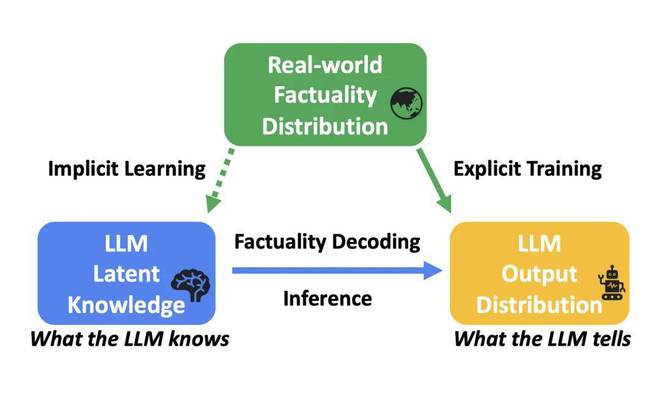
研究者将这类无法直观从模型输出中获得的信息称为 “潜在知识”,并用图一精炼出了对应的 “三体问题”。
图一:Factuality Decoding 的 “三体问题”

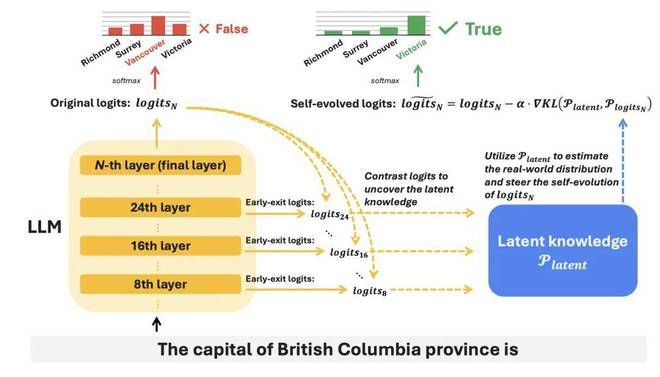
图二:SLED 框架的主要流程
方法设计


图三:研究者对三个不同规模的 LLaMA-2 模型计算了每一层对应的交叉熵损失。结果证实,就 KL 散度而言,最终层的 Logits 输出分布比所有早期层更接近真实世界的分布

实验验证
作为一种新型的层间对比解码架构,研究者首先将 SLED 与当前最先进的方法 DoLa 进行了比较。实验覆盖了多种 LLM families(LLaMA 2, LLaMA 3, Gemma)和不同模型规模(从 2B 到 70B),还有当前备受关注的混合专家(MoE)架构。
结果表明,SLED 在多种任务(包括多选、开放式生成和思维链推理任务的适应性)上均展现出明显的事实准确性提升。

此外 SLED 与其他常见的解码方式(如 contrastive decoding,ITI)具有良好的兼容性,能够进一步提升性能。
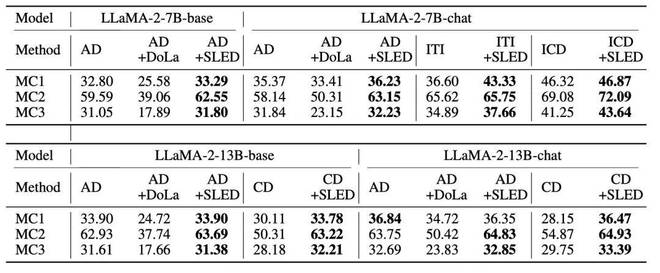
最后,研究者发现,与以往的算法相比,SLED 在计算上几乎没有明显的额外开销。同时,在生成质量方面,SLED 显著抑制了以往方法中的重复性问题,进一步优化了输出结果。

引申思考:与目前流行的 inference-time 算法的联系
实际上,不难看出,SLED 为后续的推理时(inference-time )算法提供了一个新的框架。与目前大多数 inference-time computing 方法主要集中于 sentence level 的输出或 logits 进行启发式修改不同,SLED 与经典优化算法衔接,如梯度下降法的结合更为紧密自然。
因此,SLED 不仅优化效率更高,同时有很多的潜在的研究方向可以尝试;另一方面,与 inference time training 方法相比,SLED 不涉及模型参数层面的修改,因此优化效率上开销更小,同时更能保持模型原有性能。
总结
本研究通过引入自驱动 Logits 进化解码(SLED)方法,成功地提升 LLM 在多种任务中的事实准确性。展望未来,可以探索将 SLED 与监督式微调方法结合,以适应其他领域的特定需求如医疗和教育领域。同时,改进框架设计也将是持续关注的方向。






