
AIxiv 专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心 AIxiv 专栏接收报道了 2000 多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文将介绍数学推理场景下的首个分布外检测研究成果。该篇论文已被 NeurIPS 2024 接收,第一作者王一鸣是上海交通大学计算机系的二年级博士生,研究方向为语言模型生成、推理,以及可解释、可信大模型。该工作由上海交通大学和阿里巴巴通义实验室共同完成。

- 论文题目:Embedding Trajectory for Out-of-Distribution Detection in Mathematical Reasoning
- 论文地址:https://arxiv.org/abs/2405.14039
- OpenReview: https://openreview.net/forum?id=hYMxyeyEc5
- 代码仓库:https://github.com/Alsace08/OOD-Math-Reasoning
背景与挑战
分布外(Out-of-Distribution, OOD)检测是防止深度网络模型遭遇分布偏移数据时产生不可控输出的重要手段,它对模型在现实世界中的部署安全起到了关键的作用。随着语言模型的发展,复杂生成序列的错误传播会使得 OOD 数据带来的负面影响更加严重,因此语言模型下的 OOD 检测算法变得至关重要。
常规的检测方法主要面向传统生成任务(例如翻译、摘要),它们直接计算样本在输入 / 输出空间中的 Embedding 和分布内(In-Distribution,ID)数据的 Embedding 分布之间的马氏距离(Mahalanobis Distance)。然而,在数学推理场景下,这种静态 Embedding 方法遭遇了不可行性。研究团队可视化比较了数学推理和传统文本生成任务在不同域上的输入 / 输出空间:
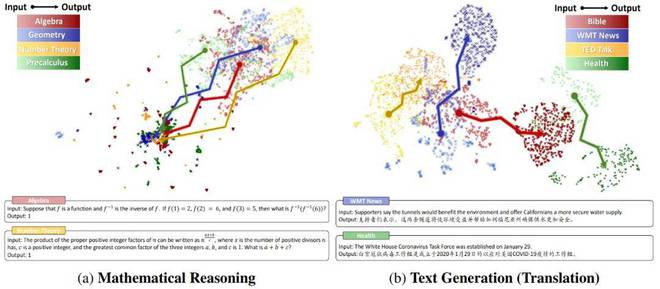
- 相比于文本生成,数学推理场景下不同域的输入空间的聚类特征并不明显,这意味着 Embedding 可能难以捕获数学问题的复杂度;
- 更重要地,数学推理下的输出空间呈现出高密度叠加特性。研究团队将这种特性称作 “模式坍缩”,它的出现主要有两个原因:
- (1) 数学推理的输出空间是标量化的,这会增大不同域上的数学问题产生同样答案的可能性。例如和这两个问题的结果都等于 4;
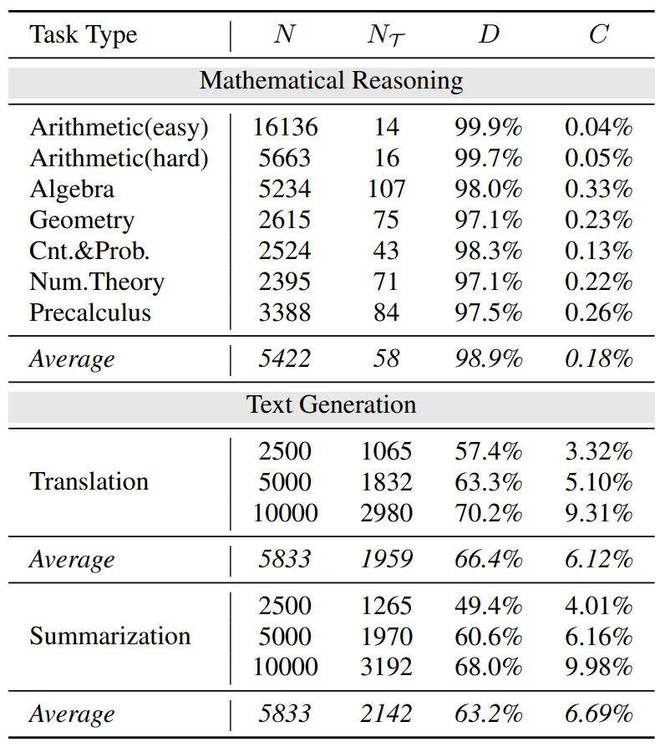
- (2) 语言模型的建模是分词化的,这使得在数学意义上差别很大的表达式在经过分词操作后,共享大量的 token(数字 0-9 和有限的操作符)。研究团队量化了这一观察,其中表示出现的所有 token 数,表示出现过的 token 种类, 表示 token 重复率,表示 token 种类在词表中的占比,发现在一些简单的算术场景下,token 重复率达到了惊人的 99.9%!
为了应对这个挑战,研究团队跳出了静态 Embedding 的方法框架,提出了一种全新的基于动态 Embedding 轨迹的 OOD 检测算法,称作 “TV Score”,以应对数学推理场景下的 OOD 检测问题。
动机与方法
1. 定义:什么是 Embedding 轨迹?

2. 动机:为什么用 Embedding 轨迹?
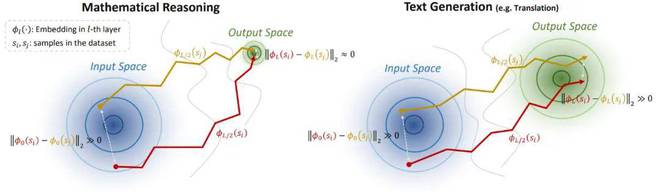
- 理论直觉
在数学推理场景下,输出空间具有显著的高密度模式坍缩特征,这使得在输入空间相差较大的两个起始点,通过隐藏层转移至输出空间后,将收敛到非常近的距离。这个 “终点收敛” 现象将增大不同样本的 Embedding 轨迹之间产生差异的可能性,如下图所示。该理论分析的数学建模和证明详见论文。
- 经验分析
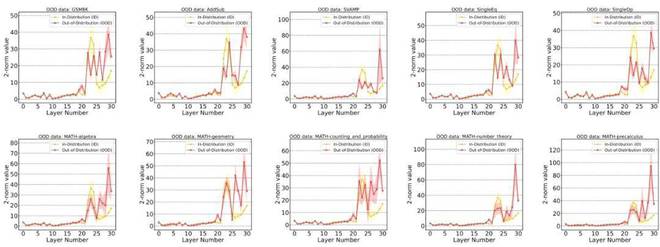
在初步获取了使用 Embedding 轨迹作为测度的理论直觉后,需要继续深入分析 ID 和 OOD 样本的 Embedding 轨迹之间会产生怎样的个性化差异。研究团队在 Llama2-7B 模型上统计了不同的 ID 和 OOD 数据集下的 Embedding 轨迹特征。其中,横坐标表示层数,纵坐标表示该层与其邻接层的 Embedding 之间的差值 2 - 范数,数值越大表示这两个邻接层之间的 Embedding 转换幅度越大。通过统计数据得出如下发现:
- 在 20 层之前,ID 和 OOD 样本都几乎没有波动;在 20 层之后,ID 样本的 Embedding 变化幅度先增大后又被逐渐抑制,而 OOD 样本的 Embedding 变化幅度一直保持在相对较高的范围;
- 通过这个观察,可以得出 ID 样本的 “过早稳定” 现象:ID 样本在中后层完成大量的推理过程,而后仅需做简单的适应;而 OOD 样本的推理过程始终没有很好地完成 —— 这意味着 ID 样本的 Embedding 转换相对平滑。
3. 方法:怎么用 Embedding 轨迹?
基于上述发现,研究团队提出了 TV Score,它可以衡量一个样本属于 ID 或 OOD 类别的可能性。受到静态 Embedding 方法的启发,文章希望通过计算新样本的 Embedding 轨迹和 ID 样本的 Embedding 轨迹分布之间的距离来获取测度,但轨迹分布和轨迹距离的计算并不直观。
因此,文章将 TV Score 的计算分为了三个步骤:

进一步地,考虑到轨迹中的异常点可能会影响特征提取的精度,研究团队在此基础上加入了差分平滑技术 (Differential Smoothing, DiSmo):

实验与结果
研究团队使用了 11 个数学推理数据集(其中 1 个 ID 数据集和 10 个 OOD 数据集)在两个不同规模的语言模型(Llama2-7B 和 GPT2-XL)上进行了实验。根据和 ID 数据集之间的难度差异大小,这 10 个 OOD 数据集被分为两组,分别代表 Far-shift OOD 和 Near-shift OOD。实验在离线检测和在线检测这两个场景下进行:
离线检测场景:给定一组 ID 和 OOD 样本的混合集合,检测 TV Score 对这两类样本的区分精度(本质上是一个判别任务)。评估指标采用 AUROC 和 FPR95。
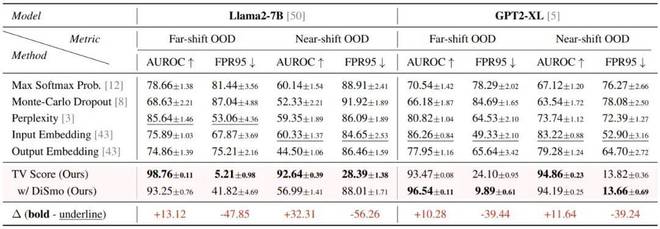
- 在 Far-shift OOD 场景下:AUROC 指标提高了 10 个点以上,FPR95 指标更是降低了超过 80%;
- 在 Near-shift OOD 场景下:TV Score 展现出更强的鲁棒性。Baseline 方法从 Far-shift 转移到 Near-shift 场景后,性能出现明显下降,而 TV Score 仍然保持卓越的性能。这说明对于更精细的 OOD 检测场景,TV Score 表现出更强的适应性。
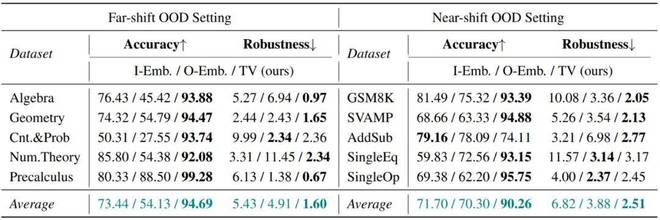
在线检测场景:在离线检测场景中获取一个分类阈值,之后面对新的开放世界样本时,可以通过和阈值的大小比较自动判定属于 ID 或 OOD 类别。评估指标采用 Accuracy。结果表明,TV Score 在开放世界场景下仍然具有十分优秀的判别准确度。
泛化性测试
研究团队还对 TV Score 的泛化性进行了进一步的测试,主要分为任务泛化和场景泛化两个方面:
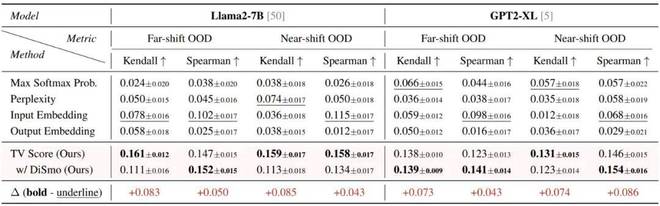
任务泛化:测试了 OOD 场景下的生成质量估计,使用 Kendall 和 Spearman 相关系数来计算 TV Score 和模型回答正确性之间的相关性。结果表明,TV Score 在该任务下仍然展现出了最优性能。
场景泛化:研究团队认为,TV Score 可以被推广到所有输出空间满足 “模式坍缩” 特性的场景,例如多项选择题,因为它的输出空间仅包含 ABCD 等选项。文章选取了 MMLU 数据集,从中挑选了 8 个域的子集,依次作为 ID 子集来将剩余 7 个域作为 OOD 检测目标。结果表明,TV Score 仍然展现出良好的性能,这验证了它在更丰富场景下的使用价值。

总结
本文是 OOD 检测算法在数学推理场景下的首次探索。该工作不仅揭示了传统检测算法在数学推理场景下的不适用性,还提出了一种全新的基于动态 Embedding 轨迹的检测算法,可以精准适配数学推理场景。
随着大模型的发展,模型的应用场景越来越广泛,而这些场景也越来越具有挑战性,早已不局限于最传统的文本生成任务。因此,传统安全算法在新兴场景下的跟进也是维护大模型在真实世界中稳定且安全地发挥作用的不可或缺的一环。






