
新智元报道
编辑:编辑部 HYZ
在「全球最难 LLM 评测榜单」上,国产万亿参数模型杀入全球第五,拿下中国第一!国内明星初创阶跃星辰的这个自研模型太过亮眼,甚至引起了外国网友的热议。
不低调了!
刚刚,国际权威榜单 LiveBench 最新榜单出炉,一个国产黑马闪耀其中。
没错,它就是阶跃星辰自研的万亿参数大模型 Step-2。
Step-2 以碾压之势,强势杀入 LiveBench 全球前五,一举夺得国内 TOP 1。
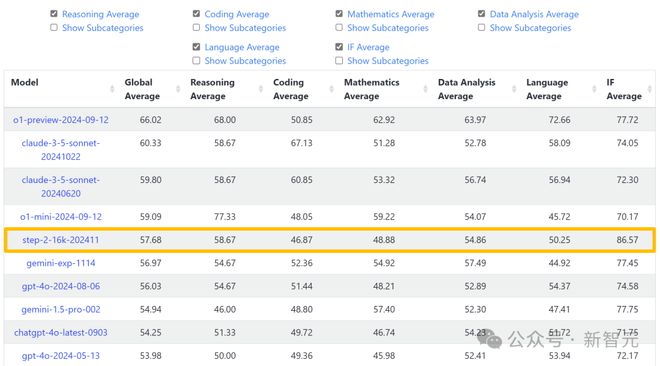
更让人热血沸腾的是,这款 Step-2 语言大模型,成为唯一一个冲进榜单前十的中国语言大模型。
根据榜单评测,Step-2 成绩逼近 OpenAI o1-mini(2024-09-12),超越 GPT-4o(2024-08-06)、Gemini 1.5 Pro 002 等国际主流模型。
Step-2 的真实表现,彻底震惊了歪果仁。在 Reddit 和X上,可谓是热议连连。
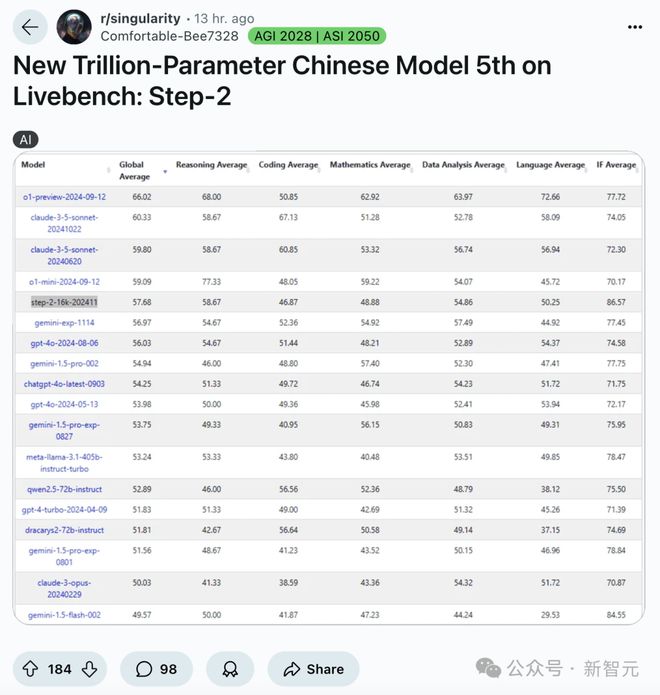
太令人印象深刻了!或许 OpenAI、Anthropic、DeepMind 发布万亿参数模型时,我们也能看到这一结果。
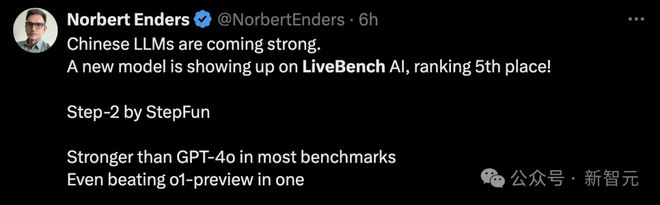
中国的 LLM 正在变得强大,一个全新模型登上 LiveBench 榜单第五名,而且在多个基准测试中超越了 GPT-4o,甚至在其中一个基准上击败了 o1-preview
如今,Step-2 以王者姿态,实至名归。
赶超 o1-preview,全凭惊人理解力
根据榜单,在 IF Average(指令跟随)一项中,Step-2 的表现超越了所有上榜的国内外模型。
甚至,连 OpenAI o1-preview(2024-09-12)也被碾压式击败,领先近 10 分。
这意味着,Step-2 在语言生成上对细节有最强的控制力,模型能够更好地理解和遵循人类指令。
比如,即便给出模糊的指令,凭借出色的理解能力,Step-2 基于上下文推断用户的需求,精准捕捉其真实意图,提供更准确、个性化的响应。
Step-2 的与众不同在于,在知识覆盖面和深度上,取得了实打实的突破。
不仅能处理常见的领域知识,还能更深层次理解、回答特定领域复杂问题。
在文字创作方面,Step-2 更展现出了令人惊叹的控制力。
它就像一位丰富的文字匠人,比如在创作古诗词时,对字数、格律、押韵、意境都可以做到精准把握。
Step-2 既能生成高质量、有创意的文字内容,又具备了出色的细节控制力,根据用户指令对文本进行精准调整和优化。
大模型最权威评测,LeCun 领衔
值得一提的是,LiveBench 是由图灵奖得主 Yann LeCun 联手 Abacus.AI、NYU、英伟达等多家机构推出的 LLM 评测基准。
其含金量,不言而喻。
而且,它被行业誉为「世界上第一个不可玩弄的 LLM 基准测试」。

当前,测试集污染,已经成为公平评估大模型面临的一个普遍问题。
就好比 LLM 在训练时偷看了测试数据,使得原有评测失去了意义。
虽然业界尝试通过人工/LLM 打分来收集新提示词和评估结果,但这种方法会引入新的偏差,特别是在评估复杂问题时表现不佳。
LiveBench 就是为了破解这一难题而诞生。
这一创新基准从数学、推理、编程、语言理解、指令遵循和数据分析在内的多个复杂维度对模型进行评估。
而且,它还会每月定期更新,基于最新信息源的测试问题。
每个测试问题都配备了可验证的、客观的参考答案,这使得即使是较为复杂的问题也能够准确且自动地完成评分,无需依赖 LLM 作为评判标准。

为了确保测试的「新鲜度」,它采用了多种创新方法,保证测试内容未受数据污染。
比如,精心设计基于最新数学竞赛、arXiv 论文、新闻文章和数据集的问题,同时收录了来自现有评测基准(如 Big-Bench Hard、AMPS 和 IFEval)的改进版任务。
发布之初,研究团队基于 LiveBench 对知名闭源模型进行评测,以及对参数规模从 5 亿到 1100 亿参数不等的数十个开源模型进行了评估。
测试结果却令人深思:即使是最强大的模型,准确率也未能突破 65% 的天花板。
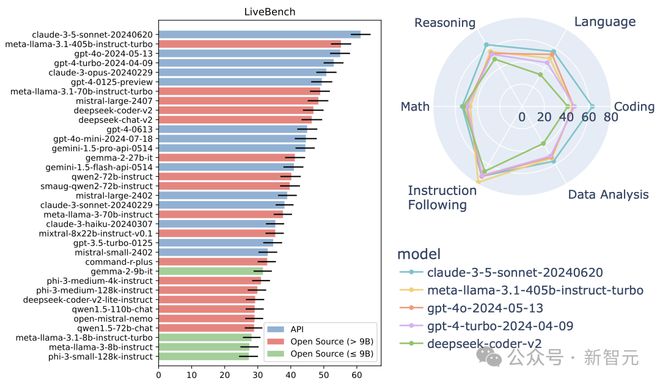
足见,LiveBench 在大模型评测中的权威性和挑战性。
这也从侧面说明了,能够跻身 TOP 5 的模型,必定是真材实料、技术过硬的佼佼者。
那么,究竟是怎样的技术实力,让 Step-2 能够在如此严苛的考验下脱颖而出?
让我们一起来揭开这个谜底...
万亿参数 Step-2,是怎样炼成的
今年 3 月,还是 LLM 战场新玩家的阶跃星辰,就一口气发布了千亿参数语言大模型 Step-1、千亿参数多模态大模型 Step-1V,以及来自国内大模型初创的首个万亿参数 MoE 语言大模型 Step-2 预览版。
今年 7 月,Step-2 正式亮相后,更是直接跻身国际顶尖模型的行列。
在数理逻辑、编程、中文知识、英文知识、指令跟随等方面,Step-2 的能力和使用体验已经全方位逼近 GPT-4。
目前,阶跃星辰已将 Step-2 接入了C端智能助手「跃问」,在跃问 App 和跃问网页端皆可体验。
体验地址:https://yuewen.cn
从千亿模型扩展到万亿参数,并不是简单的「大力出奇迹」,而是需要跨过技术上的「分水岭」,对各个维度的要求都是水涨船高。
一旦其中任何维度出现短板,Scaling Law 都将不再适用,出现「只投入,不产出」的尴尬局面。
为了训出强悍的 Step-2,技术团队在算法和系统方面都做出了大量的关键创新。
阶跃星辰创始人、CEO 姜大昕博士表示,模型扩大到万亿级别时,MoE 几乎是必选项,这是权衡了性能、参数量、训练成本、推理成本等各个维度后的最佳选择。
要训练如此大规模的 MoE 模型,有两条路可走:一是将已有模型进行向上复用(up-cycle)。
这个方案最大的好处,就在于省钱省力,算力需求低、训练效率高,但会限制模型能力的上限,容易造成比较严重的专家同质化。
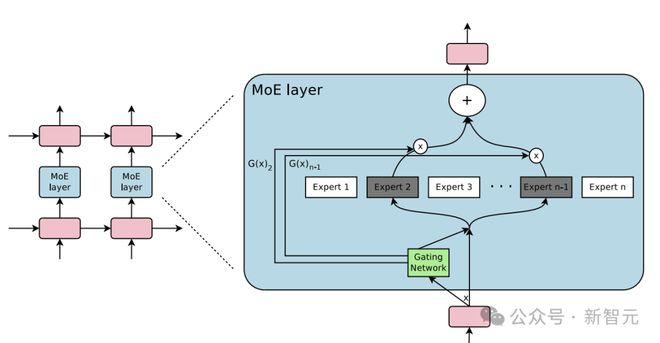
为了达到最优性能,阶跃星辰团队选择迎难而上,没有采用第一种方案,而是完全自主研发,从头开始。
Step-2 的架构中采用了部分专家共享参数、异构化专家等一系列新颖的设计,充分利用万亿参数。
虽然在 MoE 架构中,每次训练或推理只会激活部分参数,但背靠万亿总量,激活的参数量也能超越大部分稠密模型。
当参数增长到万亿级别时,训练效率至关重要,这离不开高效且稳定的系统部署。
高效,意味着 GPU 的使用效率高,让有限的硬件输出最多的算力;稳定,意味着训练过程需要持续进行,不能轻易被故障打断。
即使每张 GPU 日夜不停连续跑两个月才出现一次故障,放在万卡集群中,相当于平均每 10 分钟就有一张卡出问题。
如果没有自动的故障检测和恢复机制,每张卡出问题时都要恢复检查点、重启训练,不仅工程师不用睡觉了,模型的训练周期更是成倍拉长。
在 Step-2 训练过程中,阶跃星辰的系统团队突破了 6D 并行、极致显存管理、完全自动化运维等关键技术,从高效、稳定两个层面同时发力,才能在 3 个月的时间内发布新模型。
如今,哪条是通往 AGI 的坦途,业内大佬们依旧争论不一。
从 Step-2 霸榜惊艳表现,到多模型齐头并进,阶跃星辰展现出一家顶尖 AI 公司应有的实力和远见。
这不仅仅是一个技术突破的见证,更是一个关于中国 AI 力的最好注脚。
参考资料:






