克雷西发自凹非寺
量子位公众号 QbitAI
用 ChatGPT 诊断疾病,准确率已经超过了人类医生?!
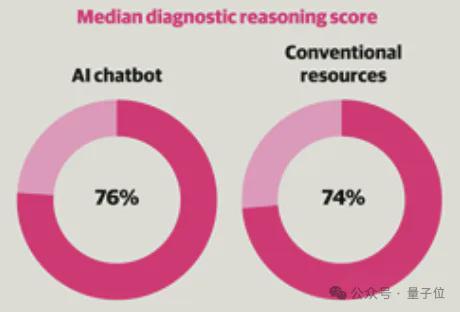
斯坦福大学等机构进行了一轮随机临床试验,结果人类医生单独做出诊断的准确率为 74%。
在 ChatGPT 的辅助之下,这一数字提升到了 76%。
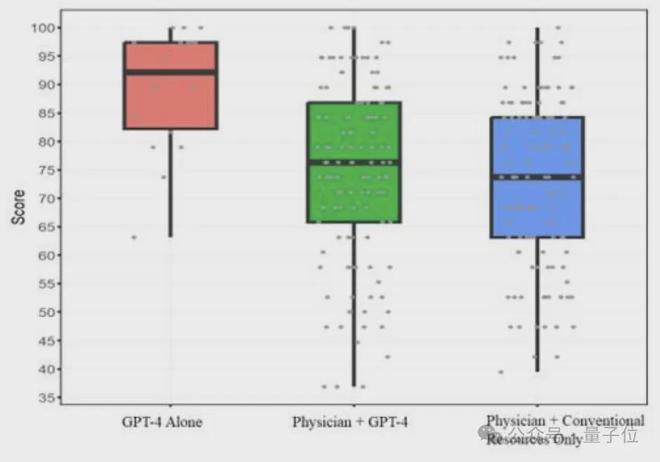
有意思的是,如果完全让 ChatGPT“自由发挥”,准确率直接飙到了 90%。
据纽约时报说,面对这一结果,参与实验的内科专家 Adam Rodman 博士表示非常震惊。
有人评价,在这样的案例中,人类的干预,反而是给大模型的表现“拖了后腿”。

OpenAI 总裁 Brockman 也转发了这则消息,表示看来AI 还有巨大的潜力,但在和人类合作这件事上,还需要再加强。

50 名医生挑战经典病例
研究团队随机从斯坦福大学、弗吉尼亚大学等机构招募到了 50 名医生,其中包括 44 名内科医生、5 名急诊医生和 1 名家庭医生。
如果按照职称划分,这 50 名医生包括 26 名主治医生和 24 名住院医生,工作年限中位数为 3 年。
主治医生和住院医生分别被随机分配到实验组和对照组,区别是在诊断中是否允许使用 ChatGPT。
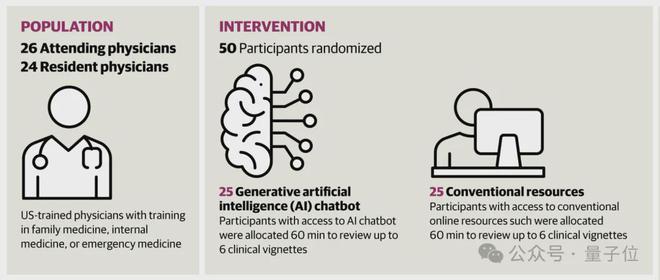
另外,研究人员还对参与者的大模型使用经验进行了统计。
结果有 8 人从未使用过 ChatGPT,6 人只用过一次,15 人使用频率少于每月一次,13 人每月多于一次但少于每周一次,8 人每周至少使用一次。
病例方面,研究团队从上世纪 90 年代以来的 105 个经典病例中进行了选择和改编。
所有病例均来源于真实病人,包含病史、体检和实验室检查结果等初步诊断评估信息,但最终诊断结果从未公开。
这意味着,人类医生无法预先知晓答案,ChatGPT 的训练数据中也没有相应的诊断结果。
四名专业医生每人独立审阅其中至少 50 个病例,确定至少 10 个满足纳入标准的候选病例,需要排除过于简单或过于罕见的病例。
最终四人小组讨论达成一致,确定 6 个最终入选病例,预计受试者完成时间为 1 个小时。
入选的病例还要经过编辑,改写成现代化实验室数据报告的格式,并用将专业术语替换为通俗描述(如将“网状青斑”替换为“紫色、红色、蕾丝状皮疹”)。

在评估方法上,研究团队设计了一个基于“结构化反思”的评估工具。
具体来说,参与者需要填写一个结构化的表格,其中包含以下关键要素:
- 最可能的三个鉴别诊断(3 分):参与者需要根据病例信息,列出他们认为最有可能的三个诊断,每个正确的诊断可以获得 1 分,最多 3 分;
- 支持和反对每个诊断的因素(12 分):对于每个鉴别诊断,参与者需要列出病例中支持和反对该诊断的具体证据。每个因素的评分采用0-2 分的等级,0 分表示错误或缺失,1 分表示部分正确,2 分表示完全正确;
- 最终诊断(2 分):在综合考虑各鉴别诊断的支持和反对证据后,参与者需要给出最终诊断。最佳诊断得 2 分,次佳但合理的诊断得 1 分,错误诊断不得分;
- 后续步骤(2 分):参与者需要列出最多三个他们认为必要的后续诊断措施,以进一步确认或排除某些诊断。每个步骤的评分也采用0-2 分的等级,0 分表示错误,1 分表示部分正确,2 分表示完全正确。
在正式实验之前,研究团队招募了 13 名医生,收集了共 65 个试点病例的结构化反思表格,并邀请 3 名临床评估专家进行盲评,从而对评分量表进行了优化。
最终,50 名参与者需要在 1 个小时时间内,完成 6 个病例的结构化反思表格。

每个病例会被 2 名评分员独立盲评,如果两名评审员评分相差不超过 10%,则直接取平均值;
如果差异超过 10%,则认为两名评审员存在分歧,需要进行讨论直至达成共识。
ChatGPT 表现超过人类
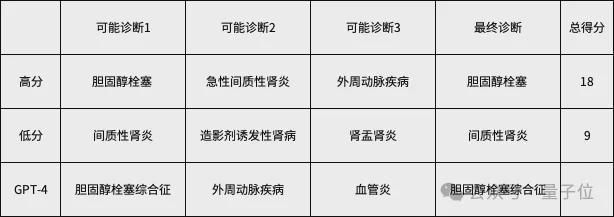
为了更清晰地展示研究的内容,研究人员公布了六个病例中的一个,以及对应得分高和得分低的医生的答案。
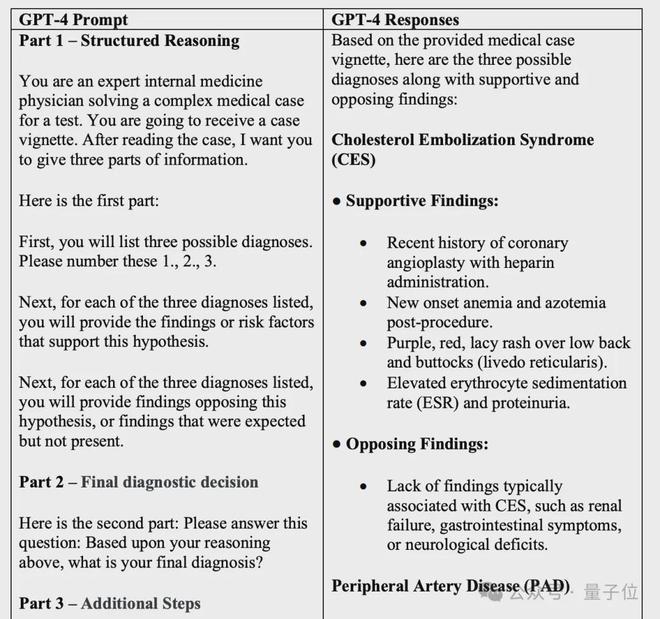
一名 76 岁的男性患者,走路时腰部、臀部和小腿剧烈疼痛。在他接受球囊血管成形术以扩大冠状动脉后几天,疼痛开始出现。手术后,他接受了 48 小时的血液稀释剂肝素治疗。
该男子称他感到发烧和疲倦。他的心脏病医生所做的实验室研究表明,他的贫血症再次发作,并且氮和其他肾脏废物在血液中积聚。该男子十年前曾因心脏病接受搭桥手术。
案例中还包括该男子体检的详细信息以及他的实验室测试结果,正确的诊断是“胆固醇栓塞”,两名医生以及 GPT-4 给出的回答如下(中间理由和后续操作略)。
最终,实验组(使用 ChatGPT)的诊断得分中位数为 76%,对照组为 74%。
由于每个参与者完成了多个病例,因此病例之间可能存在相关性,所以为了妥善处理这种嵌套结构,作者使用了混合效应模型。
这类模型不仅考虑了干预的固定效应(即是否使用大模型的影响),还考虑了参与者和病例的随机效应。
根据混合效应模型估计,两组的差异为 2 个百分点,95% 置信区间为-4 到 8 个百分点,p值为 0.60。
这意味着,尽管实验组的得分略高于对照组,但这种差异可能仅仅是由于随机误差所致,不具有统计学意义。
如果单纯看最终诊断结果,以及完成测试所花费的时间,两组之间同样没有体现出明显的差别。
除此之外,作者还补充了单独使用 ChatGPT 进行诊断的实验。
研究团队使用近期提出的提示工程框架,迭代开发了一个最优的 0 样本提示。
其中包含了任务细节、背景、指令等关键要素,且每个病例使用相同的提示。
一名研究者会将优化后的提示,连同病例内容输入 ChatGPT,每个病例独立运行三次。
研究者会不对 ChatGPT 的输出做任何人工修改,直接交给评分者一同盲评,而且评分员也不知道哪些结果由 ChatGPT 生成。
结果,单独使用 ChatGPT 得到的诊断得分,中位数高达 92%,明显高于对照组,且p值为 0.03,具有统计学意义。
需要注意的是,这些病例是经过人类临床医生精心筛选和总结的,人类已经对其中的关键信息进行过提取。
实际临床工作中,从病人那里获取信息、收集数据的过程更加复杂,因此实验结果并不代表大模型能在临床场景中取代人类。
但同时,“人类 +ChatGPT”与 ChatGPT“自由发挥”结果之间的巨大差异,也说明了人类的使用方式,还远远不能发挥出大模型的最大效能。
所以,就像开头 Brockman 说的一样,这个实验预示着,人类和 AI 之间,还需要进一步加强合作。
论文地址:
https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2825395
参考链接:
[1]https://www.nytimes.com/2024/11/17/health/chatgpt-ai-doctors-diagnosis.html






