
西风发自凹非寺
量子位公众号 QbitAI
国产大模型首次在公开榜单上超过 GPT-4o!
就在刚刚,“大模型六小强”之一的零一万物正式对外发布新旗舰模型——Yi-Lightning(闪电)。
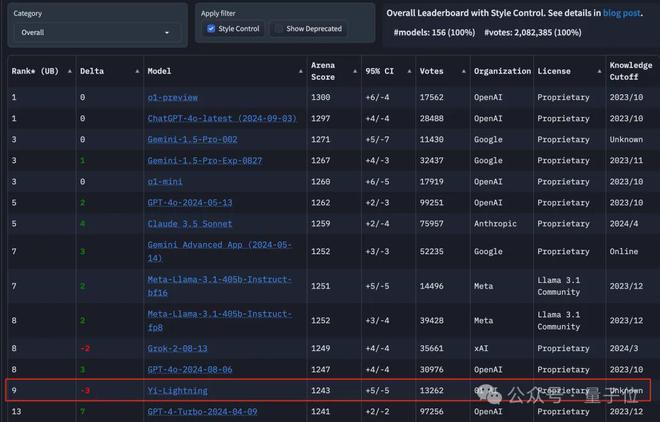
在大模型竞技场(Chatbot Arena)上,Yi-Lightning 性能直冲总榜单并列第6,数学分榜并列第3,代码等其它分榜也名列前茅。
总成绩几乎与马斯克最新 xAI 大模型 Grok-2-08-13 持平,超越 GPT-4o-2024-05-13、GPT-4o-mini-2024-07-18、Claude 3.5 Sonnet 等顶流。

同时,国内清华系大模型公司智谱 AI 的GLM-4-Plus也杀进了总榜,位居第9位。
该榜单结果来自全球累积超千万次的人类用户盲测投票。
前段时间大模型竞技场还刚刚更新了规则,新榜单对 AI 回答的长度和风格等特征做了降权处理,分数更能反映模型真正解决问题的能力。
这次 Yi-Lightning 杀出重围,Lmsys 团队特意发帖子,称这是竞技场上的大新闻:
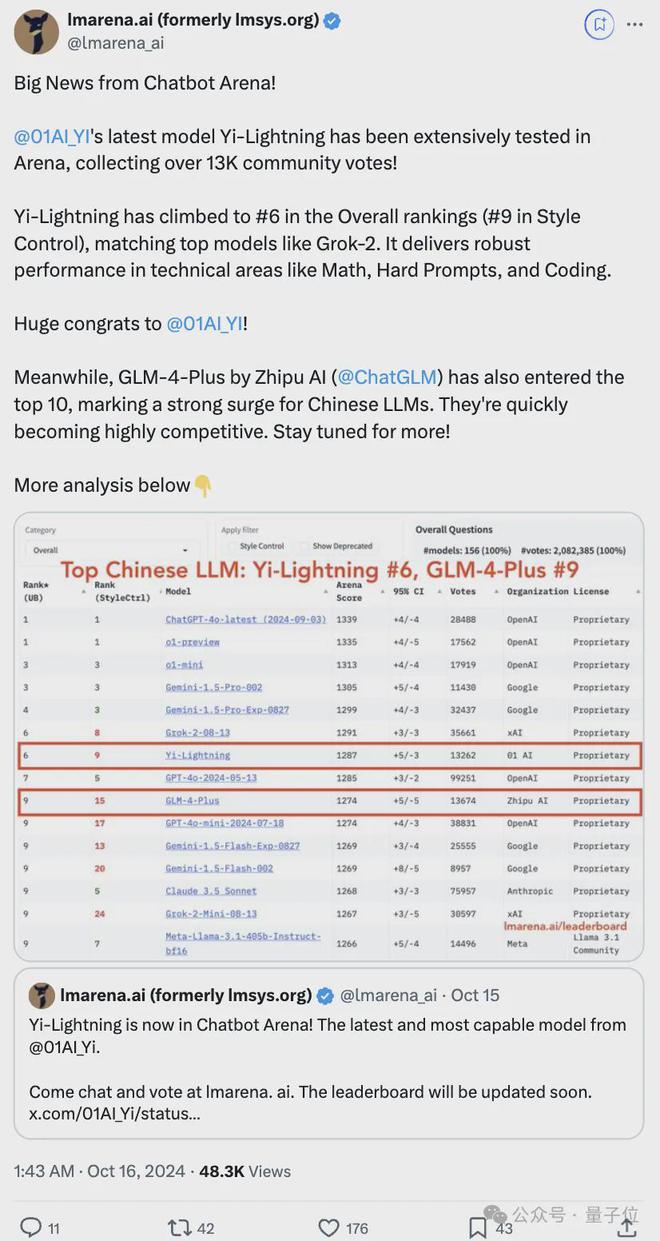
大模型竞技场总榜第六、国产第一
细看大模型竞技场分类榜上的“赛况”,Yi-Lightning 各项能力都排在前头。
在中文能力上,Yi-Lightning 和 GLM-4-Plus 两个国产大模型都名列前位。
Yi-Lightning 跃居并列第二,和 o1-mini 相差无几。
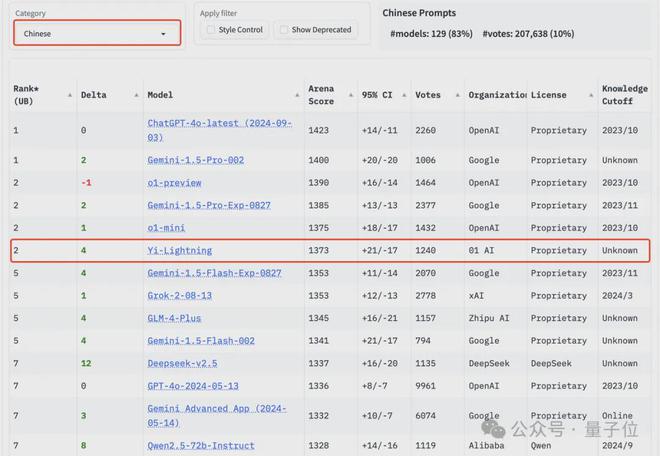
数学能力,Yi-Lightning 和 Gemini-1.5-Pro-002 并列第3,仅次于 o1-preview、o1-mini。

代码能力 Yi-Lightning 排名并列第4。
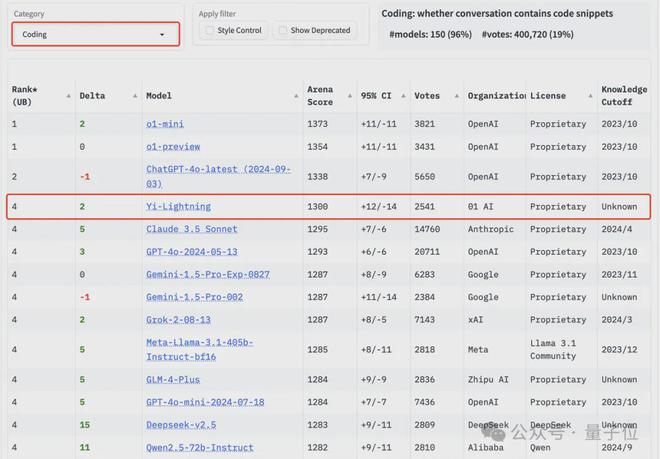
另外在Hard Prompts和Longer Query分榜,Yi-Lightning 也都排在第 4 位。
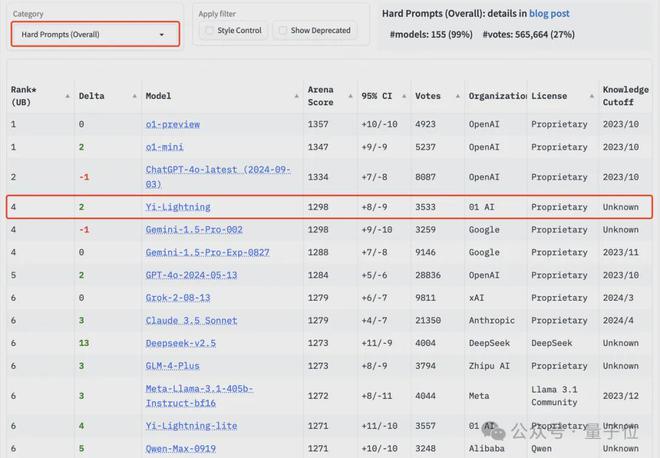
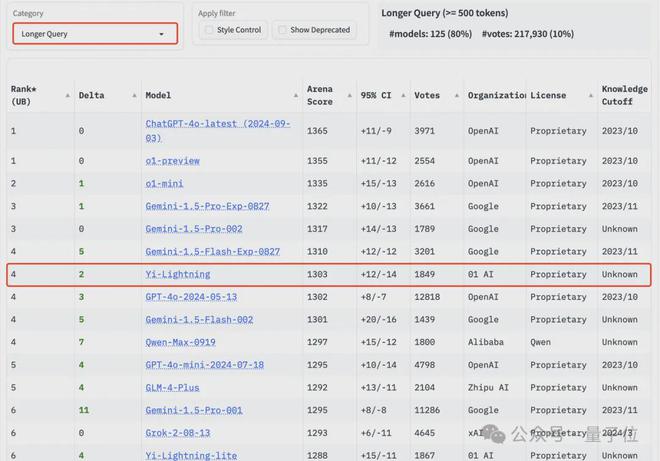
最后同样值得关注的是,竞技场新功能风格控制过滤,确保分数反映模型真正解决问题的能力,而不是用漂亮的格式、增加回答长度。
在对长度和风格等特征做了降权处理后,所有模型分数均有下降,Yi-Lightning 排名变化不大,整体还与 GPT-4o、Grok-2 同一梯队。
发布会上,零一万物创始人兼 CEO 李开复博士展示了 Yi-Lightning 在不同场景上的能力。
Yi-Lightning 主打一个“推理速度更快,生成质量更好”。
相比上半年 Yi-Large,Yi-Lightning 首包速度提升 1 倍,推理速度也提升了 4 成。
像是翻译下面这种文学作品,Yi-Lightning 不仅速度更快:
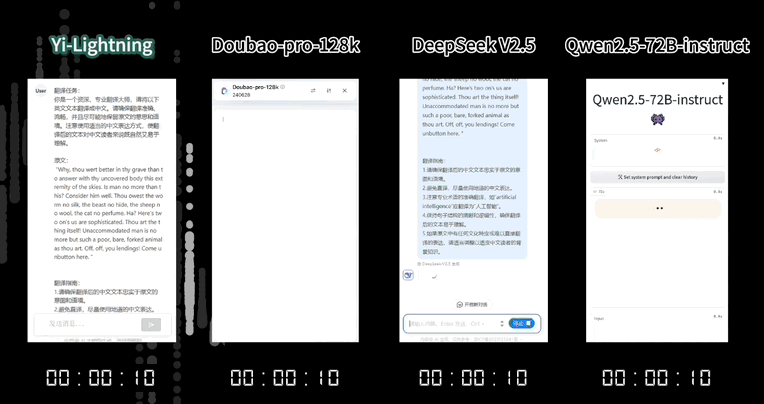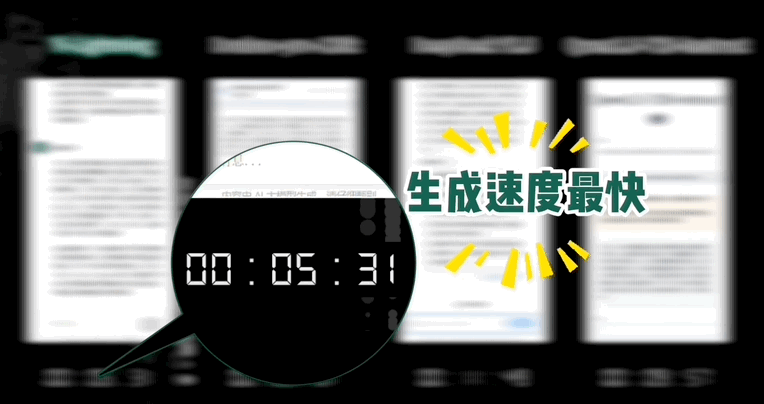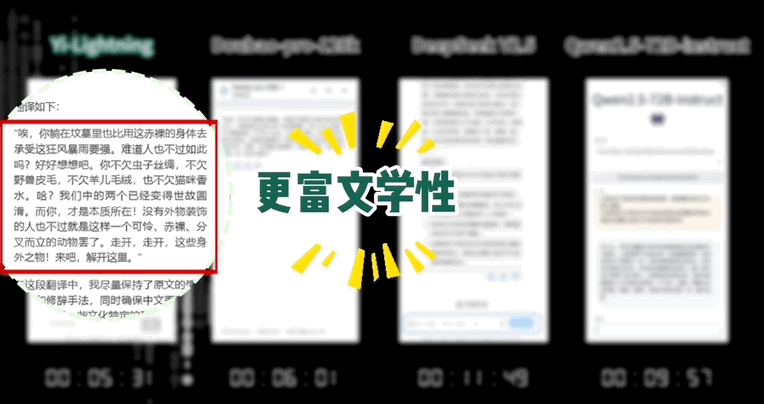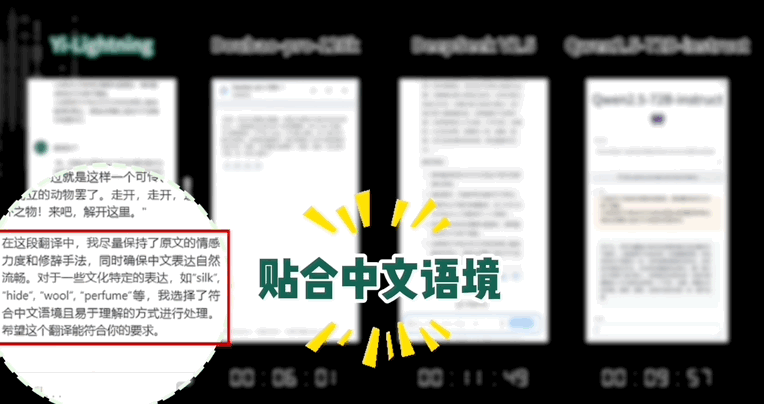
而且用词更精准,更具文学色彩:

那么 Yi-Lightning 是如何做到的?
好用还得极速
Yi-Lightning 采用 MoE 混合专家模型架构。
底层技术上,Yi-Lightning 在以下方面进行了提升。

首先是优化混合注意力机制(Hybrid Attention),只在模型的部分层次中将传统的全注意力(Full Attention)替换为滑动窗口注意力(Sliding Window Attention)。
由此以来,模型在保证处理长序列数据高性能表现的同时,还能大大降低推理成本。
Yi-Lightning 还引入了跨层注意力(Cross-Layer Attention, CLA),允许模型在不同的层次之间共享键(Key)和值(Value)头,减少对存储需求。
这使得 Yi-Lightning 能在不同层次之间更有效地共享信息。
总的来说,KV cache 缩小了2-4 倍,同时将计算的复杂度从O(L²)降至O(L)。
其次,Yi-Lightning 还采用了动态 Top-P 路由机制。
也就是说,Yi-Lightning 可以根据任务的难度动态自动选择最合适的专家网络组合——
训练过程中会激活所有专家网络,使模型能学习到所有专家知识;而推理阶段,根据任务的难度,模型会选择性激活更匹配的专家网络。
另外,之前有一些传言称国内大模型“六小强”,有一些已经不做预训练了,李开复博士这次在发布会上直接“辟谣”:零一万物绝不放弃预训练。
而且在模型预训练阶段,团队还积累了丰富的多阶段训练方法,将整个训练分为两块,一块做好以后就把它固定起来,然后在这个固定的模型上再做后段训练。
训练前期,更注重数据多样性,使得 Yi-Lightning 尽可能学习不同的知识;训练后期更重内容更丰富、知识性更强的数据。
同时团队还在不同阶段采用不同的 batch size 和 LR schedule 保证训练速度和稳定性。
李开复博士还表示,零一万物开发模型讲究“模基共建”,也就是共建模型和基础架构。
模型的训练、服务、推理设计,与底层的 AIInfra 架构和模型结构必须高度适配。
这样做的目的,不仅是让模型更好,而且让它在推理的时候能够更便宜。
再加上以上种种抬升“性价比”的技术加持,所以 Yi-Lightning 这次也是打到了白菜价——
0. 99 元每 1M token
在中文等方面,Yi-Lightning 比肩 OpenAI 的 o1-mini,o1-mini 的定价是每百万输入 3 美元,每百万输出 12 美元。
Yi-Lightning 每百万 token 只需 0.99RMB 也是打到了骨折。
但李开复博士表示,即便这样也:不亏钱。
除了发布新模型,零一万物这次还首发了AI2.0 数字人方案。
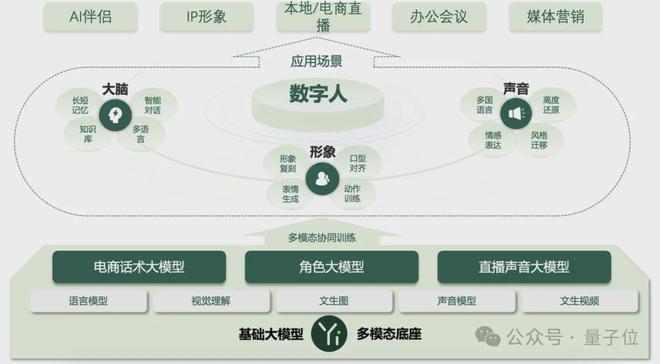
目前该数字人已接入 Yi-Lightning,实时互动效果相比以往更强更自然了,belike:
https://www.toutiao.com/article/7426244808324284968/
最后谈起和国外头部大模型的差距,李开复博士表示这次 Yi-Lightning 的排名证明了国产大模型跟硅谷最顶尖模型的差距缩小到了五个月。
去跟追上美国最顶尖的模型,缩短这个时间差非常困难,要付出很大的努力和有独特的打法。在国内不少公司都在努力,“模基共建”则是零一万物自己摸索的独特路径。
参考链接:






