
新智元报道
编辑:Aeneas 好困
震惊!就在刚刚,Scale AI 创始人 Alexandr Wang 宣布:公司的年化收入已经达到近 10 亿美元。OpenAI 的年收入,也仅仅是 35-45 亿美元。数据墙愈渐紧逼的今天,Scale AI 早早踩对了风口,如今终于一飞冲天了。
就在刚刚,创业成功的 27 岁亿万富翁 Alexandr Wang 宣布——
Scale AI 的年化收入,几乎达到了 10 亿美元!
这个数字,足够震惊整个硅谷的。

这 Scale AI 是什么来头,能在营收上取得如此惊人的成绩?
原来,它主攻的就是如今 AI 模型的一大软肋——对数据的巨大需求。

我们正在进入 LLM 开发的第三阶段。 第一阶段是早期的试验,从 Transformer 到 GPT-3 第二阶段是规模扩展第三阶段是创新阶段:除了 o1 之外,还需要哪些突破性进展才能让我们达到新的 proto-AGI 范式
Scaling Law 的存在意味着,随着模型变大,对数据的需求也呈现指数级增长,越来越多的人担心大模型会耗尽可用数据。
Scale AI 的主营业务——做 AI 模型的「数据工厂」,恰好处于这个风口之上。
如果能攻克「数据墙」这个 AI 进步的巨大瓶颈,Alexandr Wang 理所当然会赚得盆满钵满。


在 AI 浪潮中,赚得盆满钵满
生意能做这么大,源于 Scale AI 越做越成功的一项大业务。
在 AI 生态圈中,为大公司提供基础设施或服务支持的业务,市场需求巨大。
Scale AI 做的就是后者——为这些公司提供人工数据标注员。帮 AI 公司提高 LLM 的准确性。Meta、谷歌等大公司,都是它的客户。
而且,今年 Scale AI 的生意越做越红火了。
跟去年同期相比,它今年上半年的销售额增长了近 4 倍,已经接近 4 亿美元。
可以肯定地说,Scale AI 是从 AI 热潮中受益最多的私营企业之一。

投资者们当然也看到了这一点。
今年 5 月,Scale AI 以 138 亿美元的估值,进行了新一轮融资。
投资者包括 Accel、Founders Fund、Index Ventures、Thrive Capital 和 Greenoaks Capital 等。
并且,除了亚马逊和 Meta 之外,Scale AI 还吸引了各种各样的新投资者:思科、英特尔、AMD 等风险投资部门参与其中,而且很多注资过的公司也回归了,包括英伟达、Coatue、Y Combinator 等等。
就在近期,Wang 手下的高管团队,再度进行了调整。
首席技术官 Arun Murthy 将离开公司,而去年离开风投公司 Benchmark 的前优步高管 Jason Droege 将加入公司担任首席战略官,直接向 Wang 汇报。

首席策略官 Jason Droege 解释自己为什么要加入 Scale AI:这让我有机会参与到我一生中技术领域最根本的变革中
在 Droege 看来,Scale 解决了人工智能中最困难的挑战之一:通过数据改进模型。做到这一点需要卓越的人才、复杂的运营和对 AI 未来发展的强烈愿景。虽然团队迄今已经取得了瞩目成就,但仍处于起步阶段。
2023 年上半年开始,公司收入激增
这家成立 8 年的初创公司,一直负责合同工的招聘和培训,但尚未实现盈利。
然而就在今年上半年,它成功改善了运营的毛利率——每产生 1 美元收入,只需要花费约 1.2 美元,而在去年上半年,这一数字为 1.5 美元。
如今仅考虑业务成本(比如合同工的工资),Scale AI 保留的收入只有一半。毛利率这一财务指标,略低于 50%。比起 2022 年上半年约 57% 的毛利率,这个数字有所下降。
这一水平,大大低于科技投资者对软件公司的期望。
但尽管如此,5 月份的融资还是为 Scale AI 提供了雄厚的资金实力。截至上半年末,公司还有约 9.8 亿美元的现金。
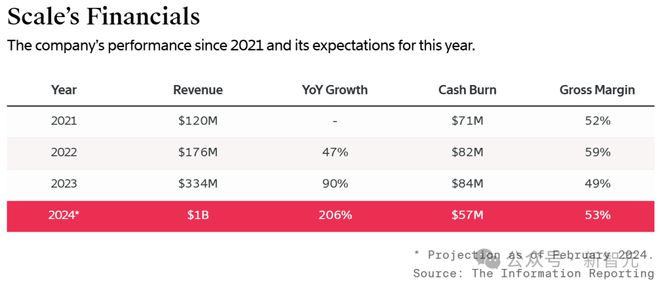
从去年上半年开始,公司收入就开始激增。因为构建 LLM 的客户需要很多合同工,通过向聊天机器人提交问题、撰写答案,来训练 AI 模型。
在给投资者的 PPT 上,Scale AI 自称是「一个人机混合系统,以低成本生产高质量数据」。
根据外媒消息,它还通过一家名为 Outlier 的子公司,雇佣了数十万个小时工,来进行数据微调。
显然,Scale AI 选择聚焦 LLM 客户,是一种战略转型。
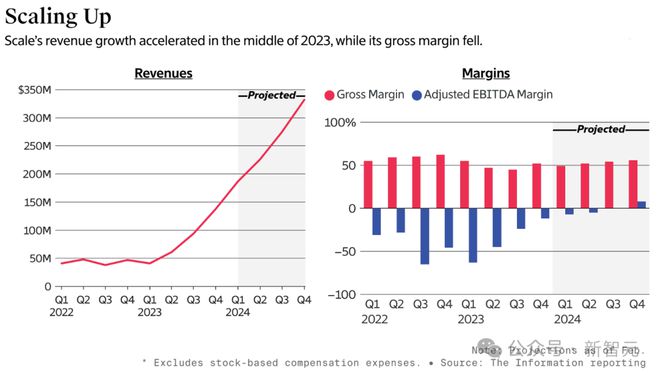
此前,它还有一项类似业务,主要是利用菲律宾和肯尼亚的低成本劳动力,为自动驾驶汽车公司标注数据。但近年来,这项业务的增长已经放缓。
现在,即使雇佣薪酬更高、更专业的合同工,Scale AI 的收入也依然能提高,因为它可以将这些更高的成本转移给客户。
当然,现在 Scale AI 也并非硅谷投资者眼中稳赚不赔的投资。投资者担忧的问题,包括公司较低的毛利率,以及过度依赖少数几个大客户的问题。
天才少年辍学创办独角兽
Scale AI 由 Alexandr Wang 和 Lucy Guo 于 2016 年创立,由著名创业孵化器 Y Combinator 投资。客户包括 Meta、微软、英伟达、OpenAI、丰田和哈佛医学院。
2019 年,Scale AI 成为独角兽。
2022 年,Alexandr Wang 成为全球最年轻的白手起家的亿万富翁。
Wang 于 1997 年出生于新墨西哥州,父母都是在新墨西哥州洛斯阿拉莫斯国家实验室的物理学家。
高中阶段,他开始通过网络自学编程,开始参加世界级编程大赛,如美国计算机奥林匹克竞赛(USACO)。
17 岁,他成为美国知名问答网站 Quora 的全职码农;18 岁,考入麻省理工学院攻读机器学习;在 MIT 大一刚结束后的暑假,他就和 Guo 一起创办了 Scale,并且拿到了 Y Combinator 的投资。
Wang 跟爸妈说,「这就是我夏天随便玩玩的事。」

Scale AI 刚起步时,有些人确实觉得这就是一个笑话,毕竟公司当时只有三名员工。
不过,在不断地融资和发展之下,Scale AI 发展飞速,到 2021 年已经成长为价值 73 亿美元的独角兽企业,2023 年初公司规模也扩展到了 700 人。
Wang 透露,随着企业客户竞相训练生成式 AI 模型,Scale AI 的这方面业务快速增长。
2023 年,公司年度经常性收入增加了两倍,预计 2024 年底将达到 14 亿美元。

由于 Scale AI 的惊人成就,Alexandr Wang 已经被硅谷公认为「下一个扎克伯格」。
AI 模型的「数据工厂」
AI 领域公认的三个基本支柱——数据、算法和算力。
算法领域,前有谷歌、微软的大型研究院,后有推出过 Sora 和 GPT 系列模型的 OpenAI;算力领域有供货全球的英伟达,但在 Scale AI 还未诞生的 2016 年,数据领域仍处于空白。
19 岁的 Alexandr Wang 在看到这一点后,做出了辍学创业的决定,「我创办 Scale 的原因是为了解决人工智能中的数据问题」。

大部分数据都是非结构化的,AI 很难直接学习这些数据;而且大型数据集的标注一项资源密集型工作,因此,「数据」被很多人认为是科技领域最辛苦、最卑微的部分。
但 Scale AI 却在短时间内就获得了巨大成功。他们可以为不同行业的企业客户量身定制数据服务。
在自动驾驶领域,Cruise 和 Waymo 等公司通过摄像头和传感器收集了大量数据,Scale AI 将机器学习与「人机回路」监督相结合,管理和标注这些数据。
他们曾经开发的「自治数据引擎」,甚至推动了 L4 级自动驾驶的发展。

Wang 表示,Scale AI 将自己定位为整个 AI 生态的基础设施供应商,构建「数据铸造厂」,而不仅仅是在子公司 Remotasks 中雇佣大量的合同工进行人工标注。
他强调,来自专家的、包含复杂推理的数据是未来人工智能的必备条件。
传统的数据来源,比如从 Reddit 等社区的评论中抓取数据存在局限性。Scale AI 构建了一些流程,模型先输出一些内容,例如撰写研究论文,在此基础上,人类专家可以改进这些内容,从而改进模型的输出。
「虽然人工智能生成的数据很重要,但想要获得有一定质量和准确性的数据,唯一方法是通过人类专家的验证。」
Alexandr Wang 在 Scale AI 的官网上这样写道,「数据丰富不是默认情况,而是一种选择,它需要汇集工程、运营和 AI 方面最优秀的人才」。
Scale AI 的愿景之一是「数据丰富」,从而将前沿 LLM 扩展到更大数量级,「为通向 AGI 铺平道路。在达到 GPT-10 的过程中,我们不应该受到数据的限制」。

业内盛赞的 LLM 排行榜更新
Scale AI 对业界所做的贡献,不仅是数据标注这么简单。
今年 5 月,Scale AI 重磅推出了全新 LLM 排行榜——SEAL,开始对前沿模型开展专业性评估。
对于这个榜单,Jim Fan 大加赞赏。他认为 SEAL 是 LMSys 的非常好的补充和参照,提供公开模型的私密、安全、可信的第三方评估。

对此,Andrej Karpathy 也深以为然。

随着 OpenAI 最强模型——o1 的推出,SEAL 排行榜也第一时间进行了评测。
除了在高级编程、数学和科学等领域表现出色之外,o1 系列也为「prompt engineering」(提示工程)引入了新的变化。

左右滑动查看
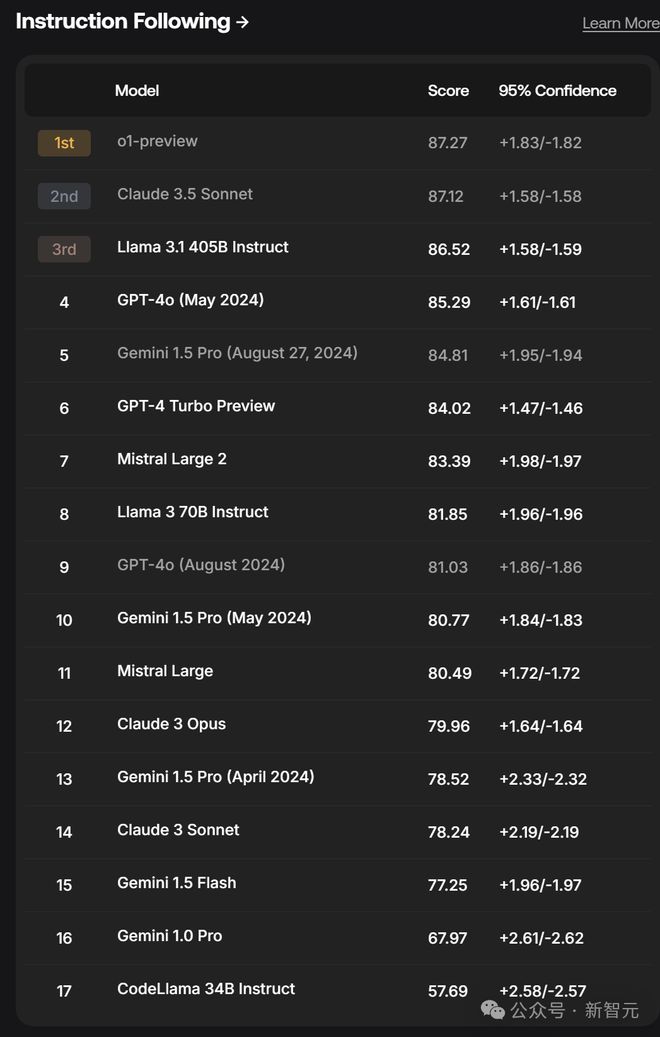
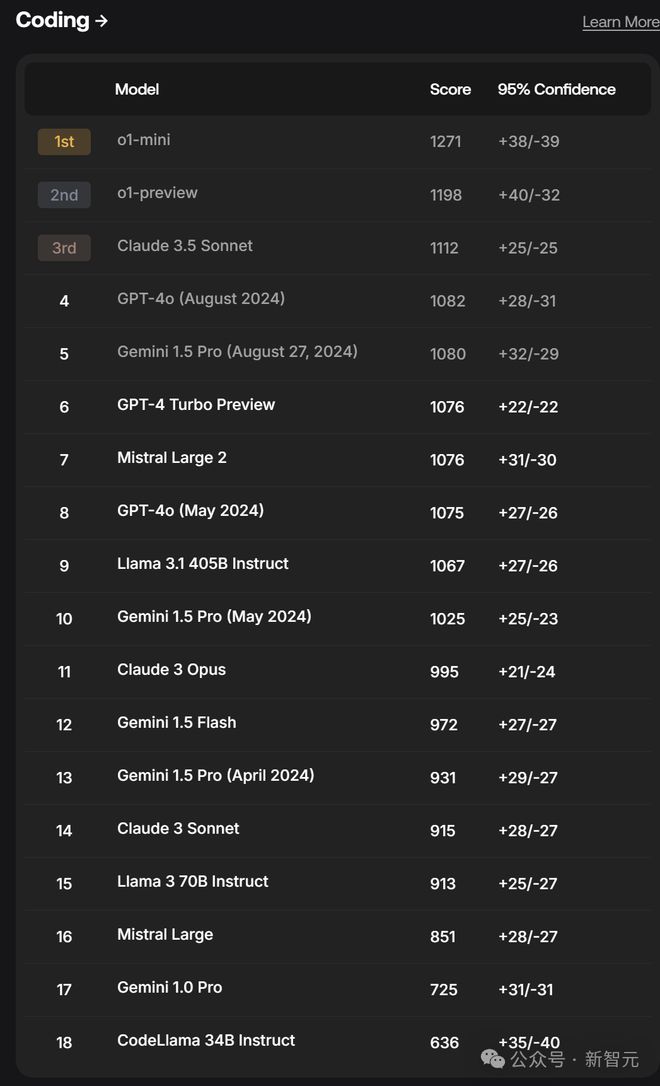
在工具使用和指令跟随方面,o1-preview 表现出色。而在编程能力方面,o1-mini 夺得榜首,o1-preview 紧随其后位居第二。
- 编程排行榜
在 SEAL 编程排行榜上,o1-mini 以 1271 分的成绩领跑,紧随其后的是 o1-preview,得分为 1198。
评估数据集使用了 1000 个提示词,用于测试各种编程任务,涵盖从代码生成到优化和文档创建等多个方面。
过程中,每个模型的响应都会从正确性、性能和可读性三个维度进行评估,综合运用人工审核和代码执行测试的方法。
- 指令跟随排行榜
在对精确指令跟随能力的评估中,o1-preview 以 87.27 分的成绩领先,超越了知名 Claude 3.5 Sonnet 和 Llama 3.1 405B Instruct。
评估数据集包含 1054 个跨领域的提示词,涉及文本生成、头脑风暴和教育支持等多个方面。
提示工程的变化
与我们熟悉的 GPT、Gemini 或 Claude 等模型相比,o1 模型的提示词使用和可操控性明显不同。
根据 OpenAI 的建议,简单直接的指令有助于充分发挥 o1 的潜力。
与之前的模型不同,用户应避免要求模型进行思维链推理。他们还指出,提示词中的无关上下文对 o1 模型的干扰可能比之前的 GPT 系列更大,因此在检索增强生成(RAG)提示中加入一些示例很重要。
Cognition Labs 发现,要求模型「think out loud」(大声思考)实际上会损害性能,而只要求给出最终答案反而会提高性能,因为 o1 模型无论如何都会产生内部的思维链。他们还指出,冗长或重复的指令会损害性能,而过于具体的指示似乎会影响模型的推理能力。
虽然 o1 在基准测试中取得了出色的结果,但让它完成你自己的具体任务似乎需要更多努力——它们往往会忽视明确(甚至是强调的)关于如何解决问题的指令。
由此可见,现实世界的提示和基准测试中使用的提示之间,实际上存在着不小的差距:后者旨在只包含明确的、自包含的、最小呈现的问题,没有关于如何解决它们的建议或意见。
需要注意的是,o1-preview 响应的延迟,特别是其「首个 token 的时间」,明显高于 GPT-4o。不过,o1-mini 用更快的 token 推理速度弥补了「思考」的时间。
一些实测
- 词汇约束
在官方示例中,o1 在臭名昭著的「strawberry 这个词中有多少个R?」等「陷阱」任务上,有着不小的改进。
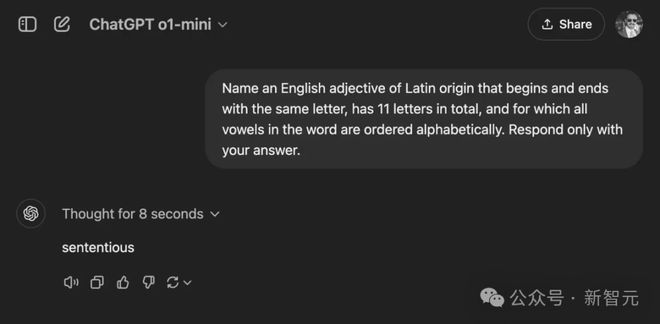
为了验证这一点,我们向 o1-preview 提出了一个新编写的谜语:
「说出一个拉丁语源的英语形容词,它以相同的字母开头和结尾,总共有十一个字母,并且词中所有元音按字母顺序排列。」
在第一次尝试中,模型成功解决了这个谜语,答案是:sententious。
但如果反复提问同一个,o1 却并不能次次做对:
sententious ✅
facetiously ❌
transparent ✅
abstentious ❌
facetiously ❌
- 解码密码
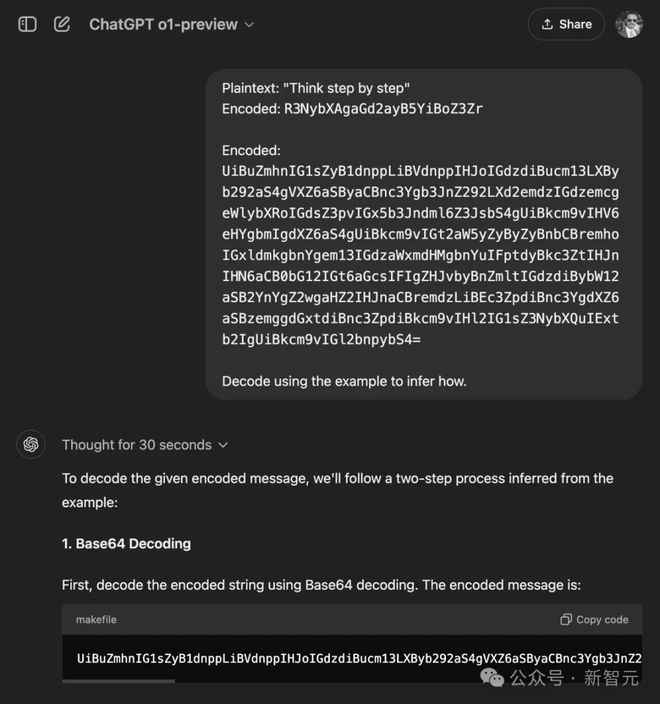
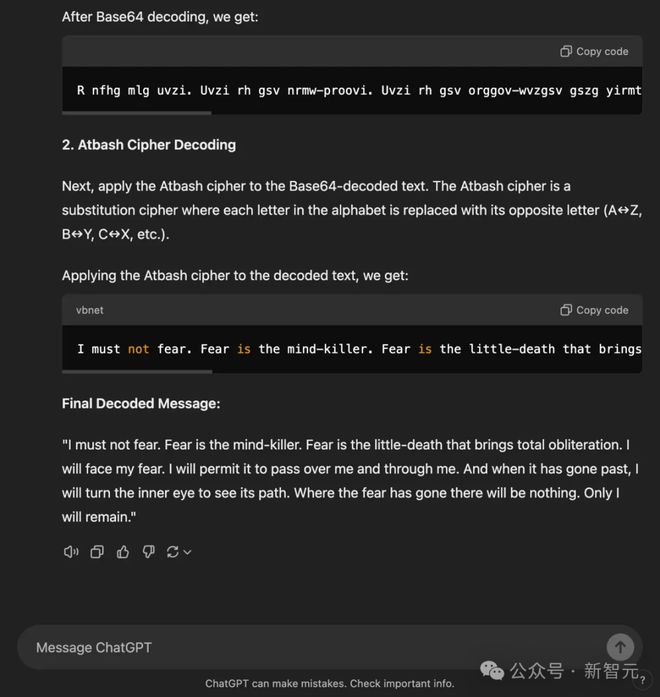
同样令人深刻的,还有一个解码复杂密码的例子。
类似的,我们也尝试了这个提示词的各种变体,包括 ROT13 密码、Atbash 密码、Base64 编码、反转字符串等各种组合。
然而,大多数测试都不成功——在 7 次尝试中,o1-preview 只有 2 次能够解码给出的加密信息(《沙丘》中的「迎恐祷词」(the Litany Against Fear))。
在每个 prompt 中,o1 都被要求从 OpenAI 给出的示例中推断出一种编码方式。
在以下每个测试中,o1 都未能在一次尝试中解码目标消息:
ROT13 密码 → 反转字符串 → Base64 编码 → 反转字符串
ROT13 密码 → Base64 编码 → ROT13 密码 → 反转字符串
ROT13 密码 → Base64 编码 → ROT13 密码
ROT13 密码 → Base64 编码 → Atbash 密码
ROT13 密码 → Base58 编码
在第一次尝试中成功解码的两个测试是:
Atbash 密码 → Base64 编码
ROT13 密码 → Base64 编码
这里展示了第一个成功的例子——其他测试除了使用的编码不同外,都是相同的:
结论
总结来看,OpenAI 的 o1 模型在推理能力方面都取得了重大突破,在 AIME、Codeforces、Scale 的 SEAL 排行榜等关键基准测试中表现出色。
这些结果表明,o1-preview 和 o1-mini 是解决复杂推理问题的强大工具。然而,要充分发挥这些模型的潜力,可能需要比用户习惯的其他模型发布更多的实验和尝试。
参考资料:
https://www.theinformation.com/articles/scale-ais-sales-nearly-quadrupled-in-first-half?rc=epv9gi
https://scale.com/blog/first-impression-openai-o1?utm_offer=blog






