
阿里今天发布了 Qwen 家族的最新成员:Qwen2.5,包括语言模型 Qwen2.5,以及专门针对编程的 Qwen2.5-Coder 和数学的 Qwen2.5-Math 模型。
所有开放权重的模型都是稠密的、decoder-only 的语言模型,提供多种不同规模的版本,包括:
- Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 以及 72B;
- Qwen2.5-Coder: 1.5B, 7B, 以及即将推出的 32B;
- Qwen2.5-Math: 1.5B, 7B, 以及 72B。
除了 3B 和 72B 的版本外,所有的开源模型都采用了 Apache 2.0 License。
Qwen2.5 主要升级内容
- Qwen2.5 获得了显著更多的知识,在编程能力和数学能力有大幅提升。
- 在指令执行、生成长文本、理解结构化数据以及生成结构化输出方面有显著改进。
- 对各种 system prompt 更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。
- Qwen2.5-Coder 使即使较小的编程专用模型也能在编程评估基准测试中表现出媲美大型语言模型的竞争力。
- Qwen2.5-Math 支持中文和英文,并整合了多种推理方法,包括 CoT、PoT 和 TIR。
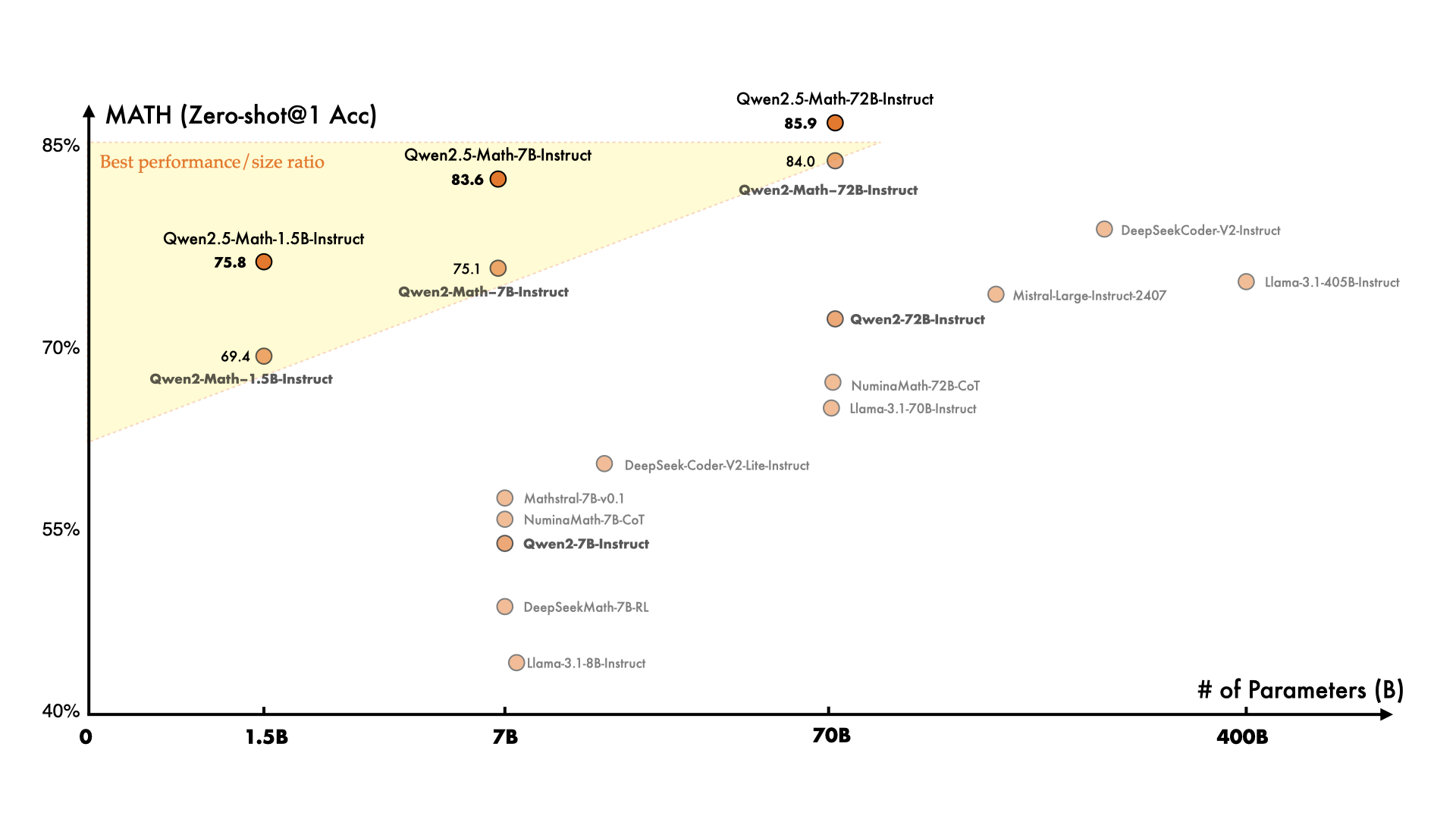
Qwen2.5-Coder & Qwen2.5-Math 性能表现

据介绍,Qwen2.5 语言模型在阿里最新的大规模数据集上进行了预训练,该数据集包含多达 18T tokens。
相较于 Qwen2,Qwen2.5 获得了显著更多的知识(MMLU:85+),并在编程能力(HumanEval 85+)和数学能力(MATH 80+)方面有了大幅提升。
此外,新模型在指令执行、生成长文本(超过 8K 标记)、理解结构化数据(例如表格)以及生成结构化输出特别是 JSON 方面取得了显著改进。
Qwen2.5 模型总体上对各种 system prompt 更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。
与 Qwen2 类似,Qwen2.5 语言模型支持高达 128K tokens,并能生成最多 8K tokens 的内容。它们同样保持了对包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韩文、越南文、泰文、阿拉伯文等 29 种以上语言的支持。
专业领域的专家语言模型,即用于编程的 Qwen2.5-Coder 和用于数学的 Qwen2.5-Math,相比其前身 CodeQwen1.5 和 Qwen2-Math 有了实质性的改进。
具体来说,Qwen2.5-Coder 在包含 5.5T tokens 编程相关数据上进行了训练,使即使较小的编程专用模型也能在编程评估基准测试中表现出媲美大型语言模型的竞争力。
同时,Qwen2.5-Math 支持中文和英文,并整合了多种推理方法,包括 CoT(Chain of Thought)、PoT(Program of Thought)和 TIR(Tool-Integrated Reasoning)。






