
新智元报道
编辑:Aeneas 好困
就在刚刚,The Information 曝出:OpenAI 的草莓将于两周内上线!收费疑似 200 刀一个月,最大的特色就是比其他模型多思考 10 到 20 秒。然而因为「狼来了」太多回,网友们忍不住吐槽:OpenAI 现在就是个炒作公司。
最新消息,「草莓」将在两周内发布!
这一消息由外媒 The Information 曝出,据称是两位已经测试过草莓模型的人士透露的。
发布时间比此前报道的秋季要早。

草莓跟其他模型的最大区别是啥呢?
答案是,更智能,但更慢、更贵。
而知名爆料人 Jimmy Apples 的说法是,一个模型(可能被称为 GPT-4.5)预计会在十月发布。
与此同时,GPT-5 很可能会在 12 月发布,但保险起见,说 2025 年第一或第二季度发布,是比较稳妥的。

在 9 月 3 日,Jimmy Apple 还曾经艾特 Sam Altman,戏谑地问道:「我耳边的低语是真的吗?我们终于要在十月做一些事了吗?」
根据 Jimmy Apple 的说法,需要耐心的时代已经过去,现在,我们迎来了发布的季节。
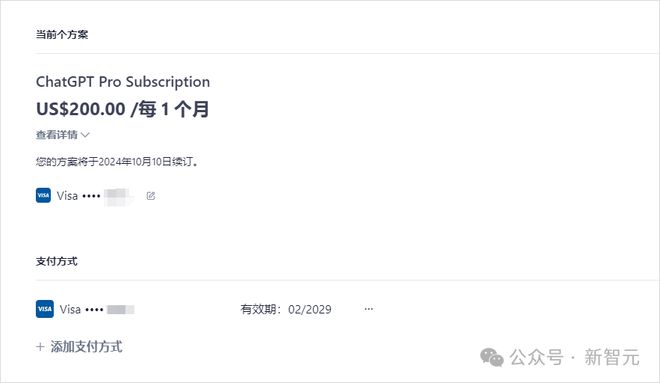
而 AI 大V「数字生命卡兹克」表示,自己的朋友发现 ChatGPT Pro 会员已经上线了,售价 200 美元每月。
他们推测,ChatGPT Pro 会员,或许就是为即将上线的草莓而准备的。

不过根据此前的爆料,草莓本身的目的,似乎是为 OpenAI 的下一代大模型猎户座生成更高质量数据。
因此也有人说,我们不必对草莓抱以过高期待。
草莓,比我们预期的更早?
据悉,两位已经测试过草莓模型的人士透露,OpenAI 计划在两周内将其作为 ChatGPT 服务的一部分发布。
这一次,报道中透露了一些新细节。
首先,虽然草莓是 ChatGPT 的一部分,但它是一个独立的产品。
目前还不清楚它将如何推出,一种可能是将其包含这种驱动 ChatGPT 的 AI 模型的下拉菜单中,根据两位人士的说法。
这就会让草莓跟常规的服务有很大不同。
第二点,草莓和其他对话式 AI 最大的区别,就是它在响应之前会思考 10 到 20 秒,然后才回答问题。
多个网友现身说法,表示自己上周发现 ChatGPT 返回某个响应时需要 10 秒才能加载,或许 OpenAI 已经在进行a/b测试了。

第三点,草莓的初始版本目前只能接收和生成文本,而不能处理图像,这也就意味着,它尚未像 OpenAI 的其他模型一样实现多模态功能。
因为如今发布的大多数 LLM 都是多模态的,这个缺陷对比之下就很显著。
最后,就是定价问题了。
现在 OpenAI 的聊天机器人有免费的,也有分等级的订阅价格。
草莓可能会有低价位和高价位的两档,前者会有速率限制,并且限制用户每小时的最大消息数量;而更高价位的版本,响应的速度也会更快。
这种安排,当然也是希望让更多用户为新模型付费,就像此前 OpenAI 限制 ChatGPT 免费用户消息数量一样。
草莓会怎样收费呢?
根据 The Information 此前的爆料,每月 50、75、200、2000 刀似乎都有可能。

一位知情人士称,在 OpenAI 早期的内部讨论中,订阅价格曾高达每月 2000 美元,但并未最终确定
如今看来,200 美元/月的定价应该是没跑了。
来源:数字生命卡兹克
The Information 还预测,目前为 ChatGPT 付费(每月 20 美元)的客户,会比免费用户更早访问首个草莓模型。
处理复杂问题更拿手
据悉,草莓会比 GPT-4o 更擅长复杂的问题,或多步骤查询。
目前,如果用户想在 ChatGPT 中得到理想的答案,往往还需要输入各种格外的 prompt。
比如用「连贯思维提示」,让 ChatGPT 通过中间推理步骤来得出答案。
而草莓可能会避免这种麻烦,让用户一步得到结果。
这也就意味着,草莓不仅在数学和编码问题上会更好,还会更擅长主观的商业任务,比如头脑风暴一个产品营销策略。
爆料人表示,草莓的思考步骤,会避免它出错。
而多思考的那十秒到二十秒,会让它更可能知道,何时要向客户询问后续问题,来完成对他们的解答。
多思考 20 秒是鸡肋?
然而两位人士透露,OpenAI 还需要再解决一些问题。
比如,理论上讲,草莓应该能够在用户提出简单问题时,跳过其思考步骤。然而在实际应用中,模型并不总是这样。
它可能会错误地花费过多时间,来回答那些其他 OpenAI 模型很快就能回答的问题。

用过草莓模型的人抱怨说,跟 GPT-4o 相比,草莓的回复只是稍稍更好一些,但并没有好到值得用户去等 10 到 20 秒。

另外,OpenAI 希望迎合用户的这一特定偏好:在回答新问题前,草莓会记住并且整合与用户先前的聊天记录。
这个细节非常重要,比如如果用户希望软件代码以某种格式书写的时候,这种能力就非常有用。
然而令人沮丧的是,草莓并不总是能做到这一点。
网友吐槽:还要挤多久?
冷知识:距离 OpenAI 发布 GPT-4,已经过去了一年零六个月。而新模型的影子,至今还没看到。
OpenAI 的草莓,来来回回炒作了好几遍。狼来了的故事来了太多次,网友们都快麻了。

别家都是要发模型就干脆利落地发,只有它把同一个话题来回来去地炒,就是不发真东西。
现在提起 OpenAI,很多群众的第一反应就是——

没错,它已经逐渐沦为「炒作」的代名词。
更有网友做出梗图,调侃道:OpenAI 发布新模型的姿势是这样的——

这样的——

以及这样的——

本来在大模型领域,OpenAI 是遥遥领先的领导者。但如今,竞争者们早已后来居上了。
上个月,谷歌就推出了 AI 语音助手 ,能够灵活处理用户的突然中断和话题变化。
要知道,OpenAI 在五月就首发了「Her」的功能,然而这个语音助手 GPT-4o Voice 随后却推迟了发布,原因是 OpenAI 在提高安全措施,确保模型拒绝不当内容。
如今正值草莓模型的发布前期,可能 OpenAI 也在做类似的准备。
而最令人失望的一点其实是,跟前两年的如火如荼相比,今年 OpenAI 的发展似乎已经停滞了。

与此同时,模型的计算量、参数大小、数据集大小,都纷纷遭遇瓶颈,开源模型和闭源模型的能力也在逐渐缩小。
是不是因为没有不够的 GPU,所以我们现在依然离 AGI 如此遥远?

如何破局?用 RL
打破瓶颈的方法,如今各家都走到了同一路径——Self-play RL。
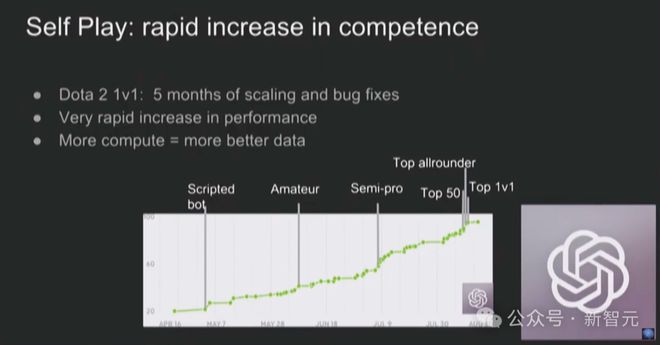
在 LLM 领域,自我博弈理论看起来就像是 AI 反馈
Claude 3.5 就是基于 Self-play RL 做出的,因此代码能力强到突出。
而我们都知道,草莓有一个重要作用,就是给下一代大模型合成数据,这里面有个前提,就是它同样是基于新范式 Self-play 做出的。
很多 LLM 的弱点就在推理能力上,而有些初创公司为了提高它们的推理能力,就采用了一种廉价的技巧,将问题分解为更小的步骤,尽管这些方法速度慢且成本高昂。
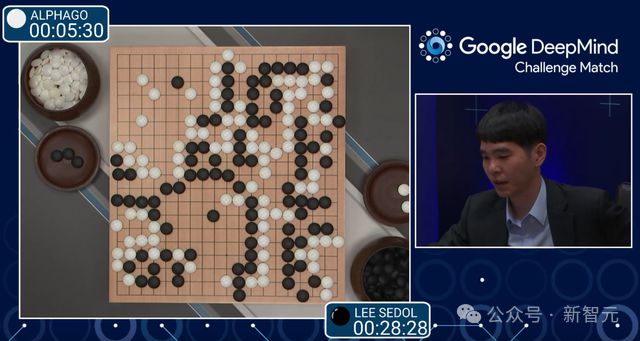
AlphaGo 就是通过 Self-play 学习,击败了李世石
在草莓中,我们也看到了类似的思路。
用 Self-play RL 去验证,自然就能让草莓的数学和代码能力上飞速暴涨。
同样,付出的代价就是极高的推理成本,导致它又贵、又慢。
但得到的结果,是极高的智能,或许启发我们通往 AGI 的路线,就靠草莓这种思路了。
说起来,「草莓之父」,其实就是已经离职了的 OpenAI 的首席科学家 Ilya Sutskever。
据悉,OpenAI 的一些人认为Q*可能是 OpenAI 在 AGI 上取得的一个突破
在 Ilya 离职之前,OpenAI 的研究人员 Jakub Pachocki 和 Szymon Sidor,在 Ilya 的工作基础上开发了一个新的数学求解模型Q*。
据称,Q*解决的此前从未见过的数学题。
另外,在去年Q*的前期准备中,OpenAI 研究人员开发了一种被称为「测试时计算」的概念变体,目的是提升 LLM 的问题解决能力。
这样,LLM 就会花更多时间考虑被要求执行的命令,或问题的各个部分。
当时,Ilya 发表了一篇与这项工作相关的博客,展示了模型如何解决了数个极有难度的数学问题。
比如在下面这道题中,GPT-4 成功执行了一系列复杂的多项式分解。

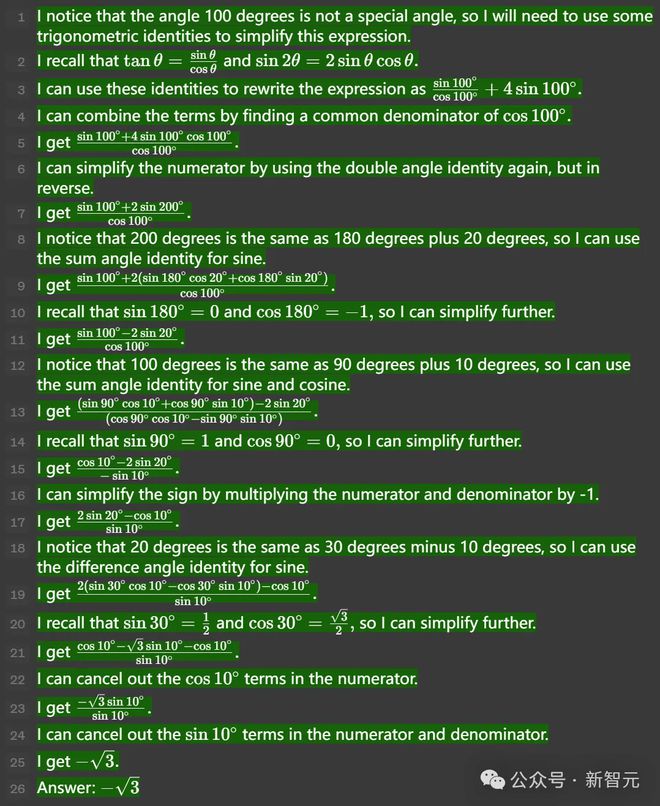

基于这类技术做出的草莓,虽然更贵、更慢,但数学和推理的进步无疑是惊人的。
或许对于普通用户,它未必是一个更值得付费的产品。
但对于需要高阶能力的场景,草莓会更有发挥的余地。
大佬猜测:谷歌 DeepMind 论文疑似揭示方法
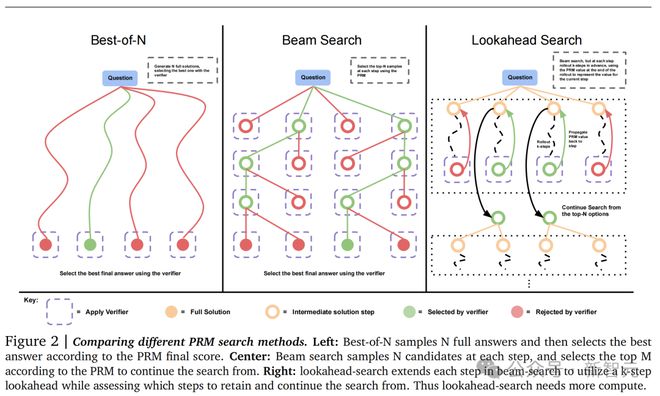
有趣的是,Menlo 风投负责人、前谷歌搜索工程师 Debarghya Das 发推称:Google DeepMind 在最近一篇论文中提出的方法,可能就是 OpenAI 在 Strawberry 上用的。

论文提出,让 LLM 进行更多的「测试时计算」(test-time computation),对于构建能在开放语境下操作、能实现自我提升的 agent,是关键的一步
而这篇论文就重点研究了扩展「推理期计算」(inference-time computation)这个问题。
如果允许 LLM 使用固定但非平凡量的推理期计算,它在应对具有挑战性的提示词时,可以有多少性能提升?
这个问题不仅影响 LLM 的可实现性能,还关系到 LLM 预训练的未来,以及如何在推理计算和预训练计算之间进行权衡。
为了回答这个问题,研究团队分析了扩展测试时计算的两种主要机制:(1)针对密集的、基于过程的验证器奖励模型进行搜索;(2)根据测试时得到的提示词,自适应更新模型对响应的分布。
结果显示,在这两种情况下,对测试时计算的不同扩展方法的有效性,很大程度上取决于提示词的难度。

论文地址:https://arxiv.org/abs/2408.03314
基于此,研究团队提出了一种「计算最优」扩展策略——通过为每个提示词自适应地分配测试时计算,使测试时计算的扩展的效率提高 4 倍以上。
另外,在 FLOPs 一致的评估中,对于那些较小的基础模型已取得一定程度非平凡成功率的问题,测试时计算可以使其超越规模大 14 倍的模型。

不过,网友们对这一猜测并不认可。
Topology 首席执行官 Aidan McLaughlin 表示,谷歌 DeepMind 探讨的是最佳N采样和蒙特卡洛树搜索(MCTS)。
而「草莓」可能会是一个具有特殊 token(回溯、规划等)的深度混合模型。它可能会通过人类数据标注者和来自易于验证领域(如数学/编程)的强化学习进行训练。
另一位网友也提出疑问——「草莓」不是一个神经符号模型吗?
对此,Deedy 解释道:「根据网上的这些信息和传闻:『草莓』将通过在响应空间中使用搜索技术来改进推理,其推理时间计算为 10 到 20 秒。」
而这,正是这项研究所解释的内容。
参考资料:
https://x.com/apples_jimmy/status/1833595024543781088






