白小交发自凹非寺
量子位公众号 QbitAI
我在外滩大会上生成 Deepfake,结果没骗过机器人……
反倒啪的一下,秒秒钟就被找出?!

而机器人手中的神兵利器,仅仅只是我们日常都在使用的手机摄像头。

实在是太火了!
Deepfake 攻防,成为整个外滩大会现场最受关注的展区之一;相关讨论也成为整个外滩大会最火热的论坛,现场可以说是人山人海人挤人。


之所以如此受关注,也有大众已知的原因。
这不最近 DeepFake 可以说是来势汹汹,用这项 AI 技术犯罪的严重程度被网友直呼是「韩国N号房再现」。
刚提到的这场“全球 Deepfake 攻防挑战赛”,吸引了全球 26 个国家和地区,2200+ 技术研究者对抗 Deepfake 威胁。在这期间,大赛队伍中科院自动化所表示,将开源 AI 模型供大家免费使用,一时间引发全网朋友共鸣。
如今在外滩大会,终于有机会亲自体验这个 Deepfake 从生成到对抗的流程是什么样,看 AI 如何帮助普通人识别伪造风险。
这背后究竟还有哪些细节?除此之外还有哪些亮点,我们一起来看看。
探展蚂蚁数科
那么首先就来看蚂蚁数科里这个超火的展区:Deepfake 攻防。
整个过程你唯一需要做的,就是站在一个定点,由 iPad 拍摄人脸。
然后,就由现有 AI 模型来生成的换脸图 or 视频。

Deepfake 就由机械臂来从三组图+一个视频中找出真照片。可以看到视频还是很逼真的,这下谁能证明“我不是我”。

由于是现场实时物理采集,机械臂手持智能手机打开相机拍照来收集数据,然后再进行一个识别的操作。
短短几秒钟的时间,bingo~机器人就识别出来了正确答案。

据现场工作人员介绍,在他们日常工作中,往往最快三秒就可以识别出来。
这背后是由天玑实验室以及安全品牌 ZOLOZ提供技术支持。
前者主要专注在可信数字身份这块,自研了一套自动化生物识别测评体系。当前市面上 70% 的安卓手机,都要来到天玑实验室经历一番“毒打”。它也是谷歌全球唯一官方合作”安卓生物识别安全”检测实验室。
而后者,则是蚂蚁数科旗下安全科技品牌 ZOLOZ,现在在为中国、印尼、马来西亚、菲律宾等 14 个国家和地区的 70 余家合作伙伴提供技术服务,包括像端到端身份验证、在线欺诈检测以及持续风险监控服务等。
今年 4 月,他们推出了反 Deepfake 产品ZOLOZ Deeper。外滩大会展示的,正好是他们日常的真实业务场景——
几十万测试样本,每月超 20000 次的攻防测评,模拟上百种伪造攻击情况·····
同样以直观可感的方式展示出来的,还有他们的 AI 标注场景。
AI 大模型生产流程通常包括三个步骤:采集-标注-合成。
首先是采集过程。
现场准备了一个模拟真实环境的沙盘,我们通过控制机械臂来对沙盘中任意位置 or 场景,进行实时拍照。

这时候图像数据也就被传输到系统当中去,这也就完成了数据生产的起点。
随后就是标注这一步骤,不再是传统依靠纯人工的方式,而是依靠自研的多模态大模型来 AIGD(AI 生成数据)。
模型会自动完成目标检测并标注、语义分割、文本描述、深度检测、3D 建模等任务。

人类主打一个协助审核的作用,比如在文本描述阶段,需要靠人工来审核识别目标的细节,比如物体的颜色、形状等等。
最后就来到数据合成。核心特点就是可控。既可以对单个物体编辑,也可以对整体场景把关。

这样一来无需采集,打破原有真实条件限制,可持续地生产全新的数据。
而除了实景标注,旁边还有个视频标注的模块,只需对任意视频中的任意一帧进行采集,同样也可以完成接下来的标注和合成操作。
这样一套全链路生产体系,实测显示,在同类结构和同类规模数据量的情况下,会让标注效率提升 40% 以上。
除了智能化标注产品,蚂蚁数科还配备了万人的人工标注团队,垂直专业领域同高阶标注人才超过 90%。

提到数据标注,当前市面上最具代表的莫过于 Scale AI,科技圈当红独角兽,他最新完成近 10 亿美元融资,估值升至 138 亿美元。
不过同 Scale AI 不同的是,此次可以看到蚂蚁数科还提供数据加工、合成服务。
比如在一些企业私域或者垂直领域,大量数据尚未公开没有被充分挖掘。
结合蚂蚁数科多年来场景和技术优势,这时候除了帮助企业实现数据服务的“就地取材”,还可以针对性地数据泛化,比如像交通、政务、金融等垂直场景,合成更多高质量数据。
好了,以上 Deepfake 攻防与智能标注是此次蚂蚁数科最具代表性的展区内容。
值得注意的是,这正好是当前业界正在热议也是最受关注的两个问题:
当 AI 应用泛滥,如何应对造假问题;大模型加速落地,高质量数据缺失又应该如何解决?
如今大模型时代来到应用时期,更多风险和问题由此暴露出来,给企业带来了不少挑战。
对于本身在产业深耕多年的蚂蚁数科,其实这次也带来了他们的解决方案。
这藏在外滩大会上,藏在这两个最受关注的产品之中。
他们整个业务布局,可以这样总结:从 AI For Data 到 Data for AI。
从 AI For Data 到 Data for AI
什么是从 AI For Data 到 Data for AI?要回答这个问题,需要从整个产业现状开始看。
AI 发展到现在,从模型驱动来到了数据驱动,而随着数字化转型的深入,企业生产经营实际上是数据的流通。技术与场景,AI 与 Data,从未像今天这样如此契合。业务场景需要 AI 来提效,而高质量数据需要充分利用为给 AI。
一边是AI for data,利用 AI 来充分挖掘数据的价值,进行数据分析、判别等。
以风控场景为例,这是每个企业经营生产时都会面对的场景。
蚂蚁数科搭建了一套决策式 AI 驱动的风控算法模型。引入像工商司法数据、财报数据、产业链数据、发票税务数据、舆情数据等,来帮助企业做出高效准确的决策。
以往需要大量人力进行人肉风控,对于他们来说,理解管理诉求和快速决策布控非常具有挑战性。而现在只需要 AI 这个决策辅助在手,运营新手面对再复杂的场景也能 hold 住了。
比如蚂蚁数科与中铁建的合作中,他们共建了一套“产业数据 +AI 模型”的产业风控平台,让产业链的客商准入效率提升了至少 50%。
一边data for AI,高质量数据是训练 AI 模型的基础。AI 驱动的数据服务-数据加工-数据标注于一体的方案,加速企业大量原始非结构化数据朝着高质量结构化数据的转化。
除此之外,还有像蚁天鉴这样的大模型安全产品,来保障大模型在训练生产和使用过程中的安全可控可靠。
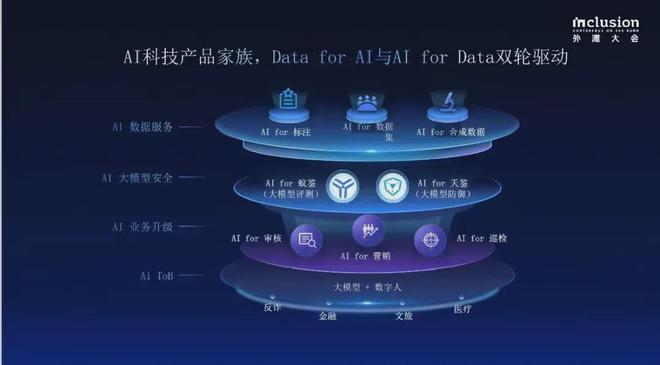
我们注意到,蚂蚁数科已经形成 ABC 三大业务板块:
首先是云服务(Cloud+),帮助企业迈入数字化「上云」阶段,打造更强大的科技引擎;
第二块是 AI 服务(AI+),以 AI 技术重构升级风控、营销等场景效率,助力企业在大模型时代建立竞争优势。
第三块是区块链服务(Blockchain+),通过科技构建产业信任,提升数字化协作效率,加速数据资产流通。
对于蚂蚁数科来说,ABC 中的“A”很重要,很明显的指向是,此次蚂蚁数科呈现出来的业务布局“从 AI For Data 到 Data for AI”,有三个特点:
产业、产业还是产业。用 AI 真实创造产业价值,解决实际问题。这同样也是大模型应用最紧要的命题。
产业需要什么样的 AI?
大模型发展到现在,人们对大模型的看法已经变了。
比如就从最近诸多行业问题与思考开始,图像视频生成模型频频开卷,人们的目光不再聚焦于效果多么惊艳,而是因为效果过于逼真,开始担心背后的潜在隐忧;被「缓解高质量数据荒」的数据合成,结果 Nature 封面一个:Garbage in Garbage out,数据合成越多会导致语言模型崩溃,给这个新兴行业趋势浇了冷水……
以及关于 ScallingLaws 的讨论,在行业应用的大模型,参数量到底在多少合适?真的是越来愈多,模型性能就会好吗?
种种问题,甚至还导向了另一种倾向:大模型,是不是真的存在泡沫?
之所以能引起这样的思考,其实也不难理解。
随着大模型技术的发展和应用的深入,一方面人们逐渐意识到了大模型能力的边界。模型的参数量不再作为模型能力的核心指标,高质量的数据流入才能保证模型高性能。
另一方面,大模型进入应用深水区。产业界对 AI 的需求,已经不仅仅是单纯的技术追求,解决实际问题才是衡量大模型的唯一标准。

随之而来的,就是场景中的诸多挑战。
以数据问题为例,当前市面上通用大模型都是基于互联网公开的数据集。他们虽然数量众多、类别广泛,但是无法保质保量,甚至大部分都是“脏”数据。
对于专业严肃的应用场景来说,一来更多高质量的行业数据是非公开的,又或者是企业内部自身的,这需要系统来统一调度和管理,还有一些非结构数据需要转化;二来,对于大量公开的数据需要工程级别的清洗、标注,才能达到能使用训练的水平。
因此看大模型落地千行百业,不能简单看大模型的性能展示,而是说怎么同产业的深度融合。
而本身就在产业有着长期投入的企业,他们有着天然的场景优势,也最有可能将 AI 能力和影响力才能渗透进行业之中。
蚂蚁数科,就是一个。
— 完 —






