
新智元报道
编辑:桃子
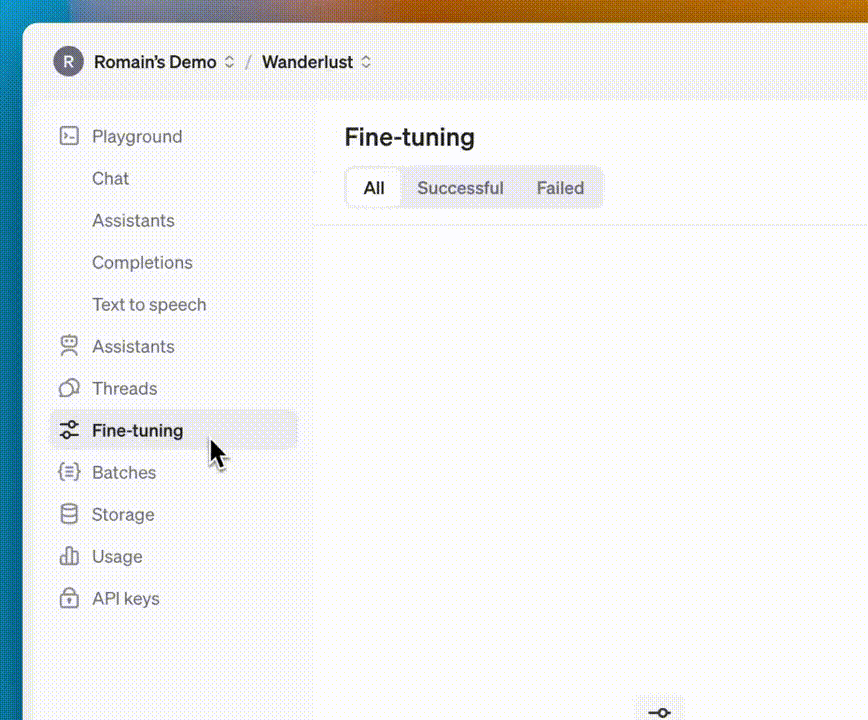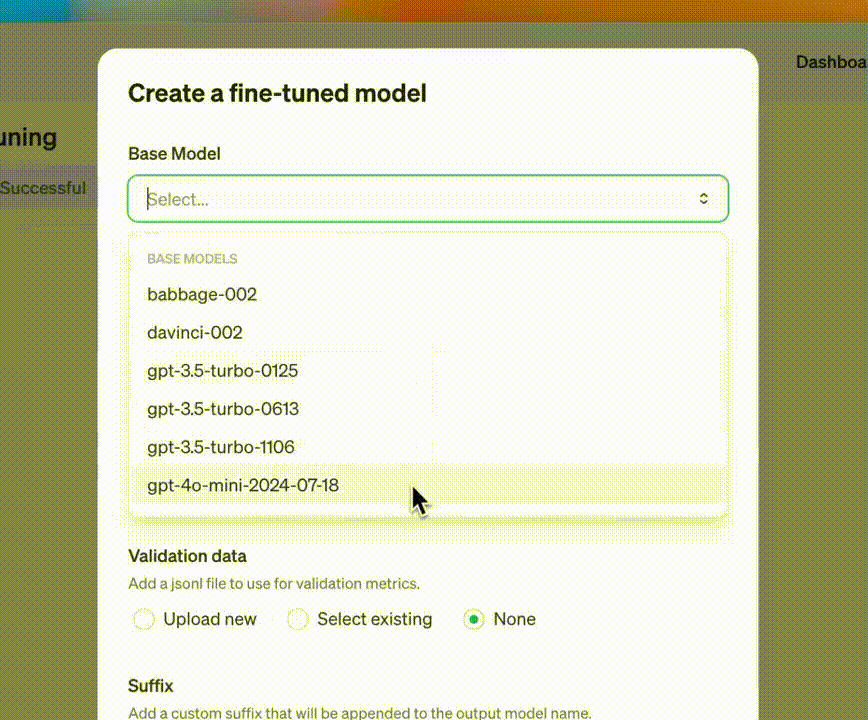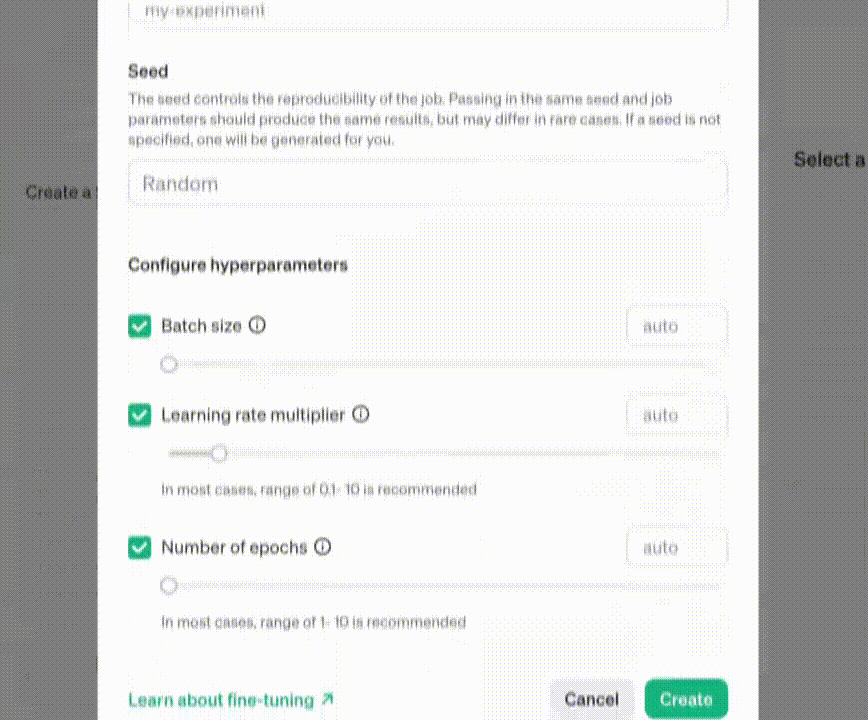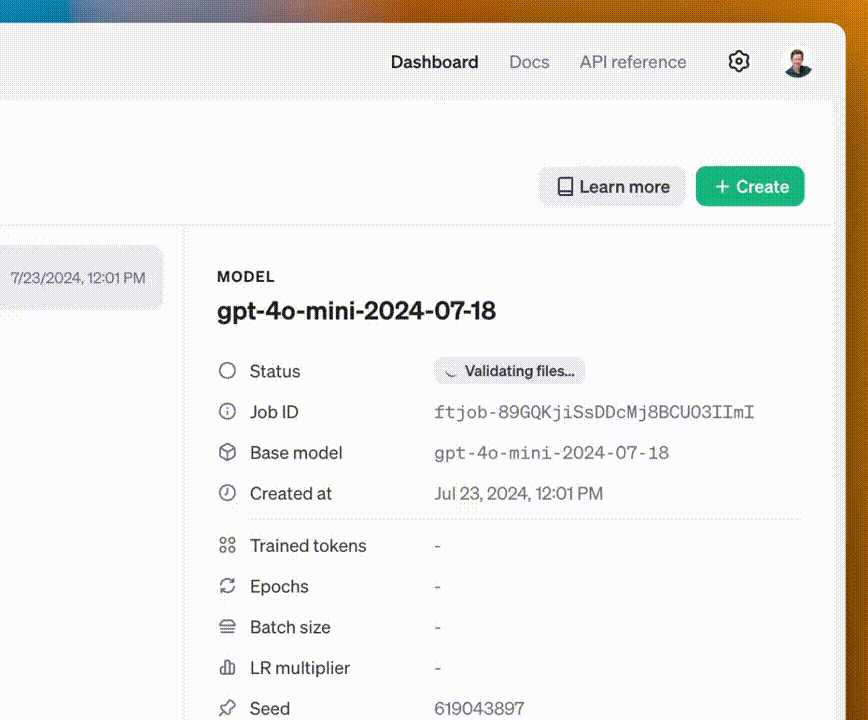
Llama 3.1 405B 巨兽开源的同时,OpenAI 又抢了一波风头。从现在起,每天 200 万训练 token 免费微调模型,截止到 9 月 23 日。
Llama 3.1 开源的同一天,OpenAI 也 open 了一回。

GPT-4o mini 可以免费微调了,每天畅用 200 万训练 token,限时 2 个月(截止 9 月 23 日)。

收到邮件的开发者们激动地奔走相告,这么大的羊毛一定要赶快薅。

另一边,GPT-4o mini 在大模型竞技场 LMSYS 排名也出来了。
总榜单中,GPT-4o mini 与 GPT-4o 并列第一。
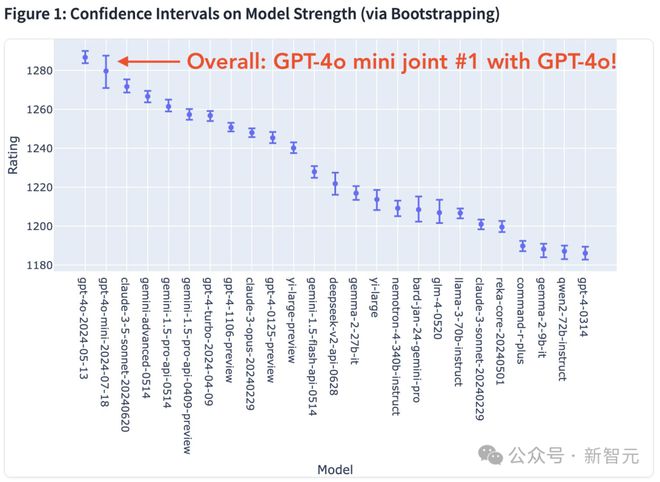
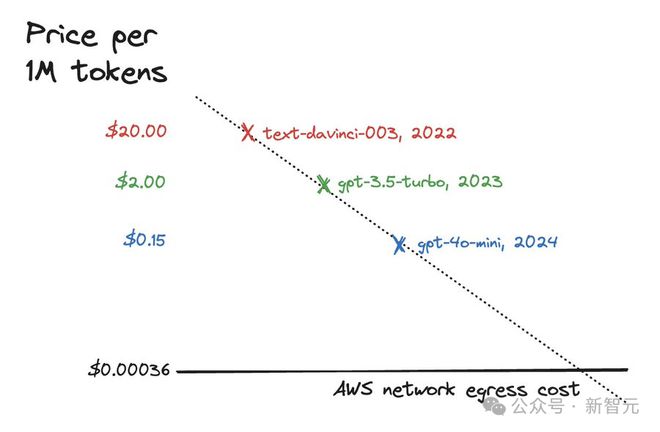
Altman 本尊激动地表示,我从未对任何一次评估如此兴奋过,GPT-4o mini 与 GPT-4o 性能如此接近,而价格仅有其1/20!

同时,他表示,GPT-4o mini 的微调现在上线了。

OpenAI 能把如此强大的模型,放出来让大家免费用,实在是出人意料。
网友一度以为,这可能是最高级的钓鱼邮件。

每天 200 万 token,GPT-4o mini 免费微调
邮件中,OpenAI 宣布现正式推出 GPT-4o mini 微调功能,为的是让最新小模型在特定用例上,表现更加出色。
7 月 23 日-9 月 23 日期间,开发者们每天可以免费使用 200 万训练 token。
超过的部分,将会按 3 美元百万 token 收费。
到了 2 个月免费使用截止后,微调训练也将按照 3 美元百万 token 收费。
此外,OpenAI 在邮件中给出了,每个人值得从 GPT-3.5 Turbo 切换到 GPT-4o mini 的原因:
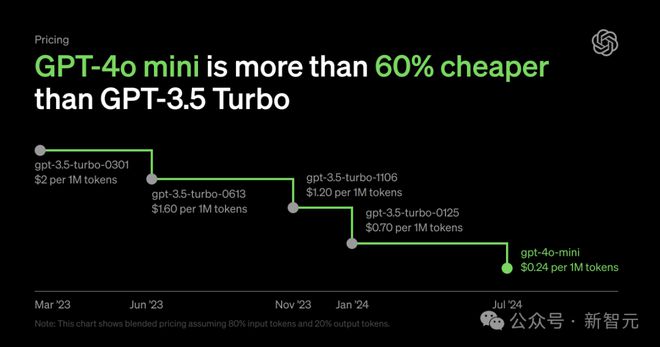
- 更实惠:GPT-4o mini 的输入 Token 费用比 GPT-3.5 Turbo 低 90%,输出 Tokens 费用低 80%。即使在免费期结束后,GPT-4o mini 的训练成本也比 GPT-3.5 Turbo 低一半。
- 更长的上下文:GPT-4o mini 的训练上下文长度为 65k Token,是 GPT-3.5 Turbo 的 4 倍,推理上下文长度为 128k Token,是 GPT-3.5 Turbo 的 8 倍。
- 更聪明且更有能力:GPT-4o mini 比 GPT-3.5 Turbo 更聪明,并且支持视觉功能(尽管目前微调仅限于文本)。
最后,邮件中还提到,GPT-4o mini 微调功能将向企业客户,以及 Tier 4 和 Tier 5 开发者开放,未来将逐渐扩大访问权限,扩展至所有级别的用户。

想要动手操作的小伙伴们,OpenAI 已经放出了微调指南,可参见:
https://platform.openai.com/docs/guides/fine-tuning/fine-tuning-examples
一部分网友对此并不看好,他们正在保存我们的数据,来训练和改进 AI 模型。

「又名,把你的私人数据给我,我会收你很少的钱」。

网友用例
拿到资格的网友,已经迫不及待上手测试了。
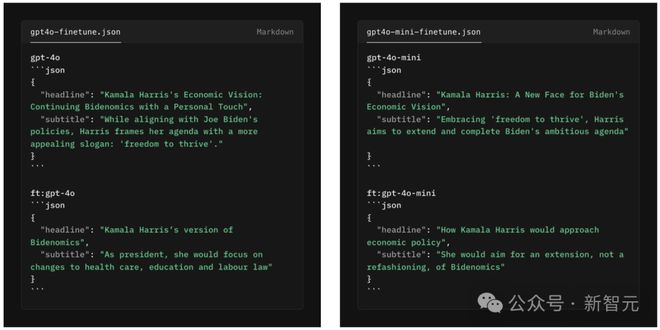
开发者使用《经济学人》风格的头条数据集,对 gpt-4o mini 进行了微调。


然后,他比较了 gpt-4o、gpt-4o min 原始模型和微调后的模型在生成头条方面的表现。
小模型霸榜,堪比 GPT-4o
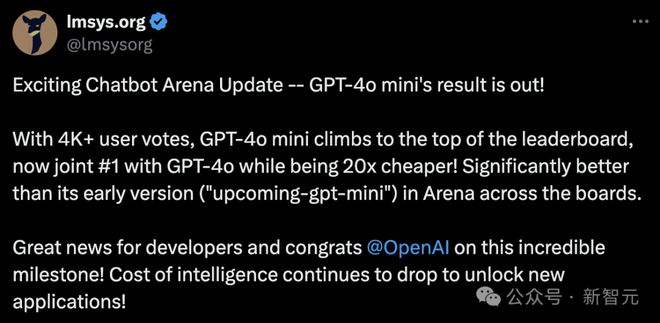
GPT-4o mini 发布一周后,在大模型排行榜中的成绩终于出来了。
共收到了 4K+ 用户投票,GPT-4o mini 小模型直接攀升至榜首,与 GPT-4o 并列第一。
最最重要的是,便宜 20 倍!
这对于众多开发者来说,是个好消息,能够以更低的成本,搭建更强大的应用。
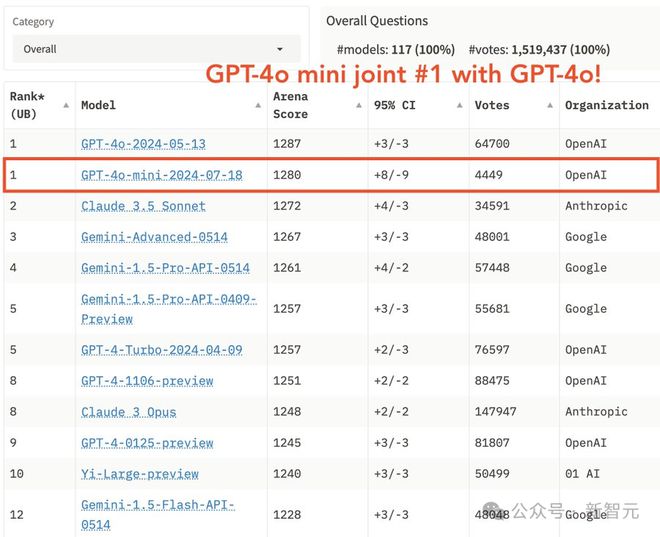
在数学细分领域中,GPT-4o mini 的性能有所下降,排在第9。

此外,在 hard prompt 评测中,GPT-4o mini 依旧保持了稳健的性能,实力仅次于 GPT-4o、Claude 3.5 Sonnet。
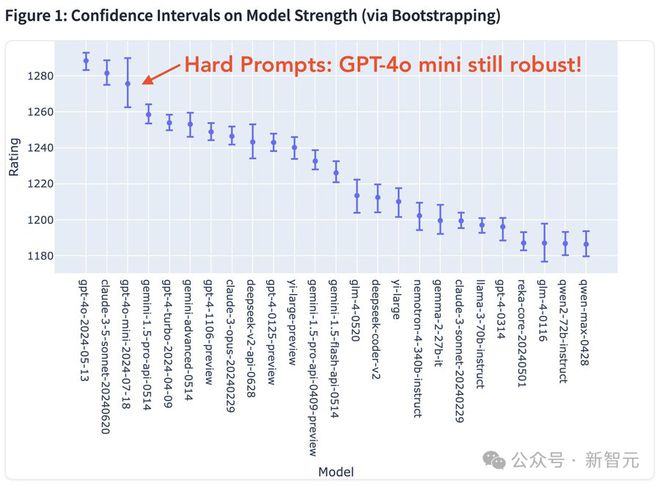
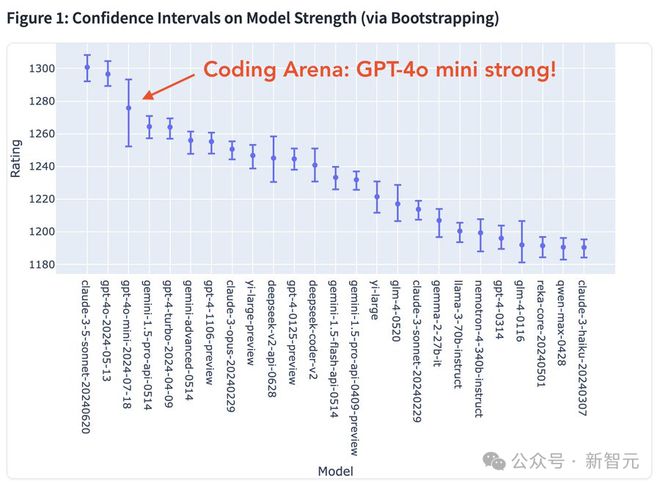
在编码领域,GPT-4o mini 同样展现出强大的能力。
关于 GPT-4o mini 在 Arena 中排名如此高的原因,很多人提出了疑问。
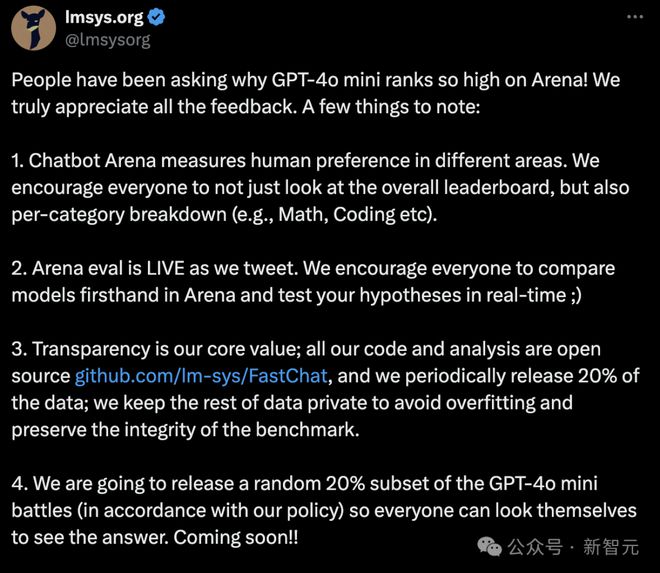
官方对此解释是:
- Chatbot Arena 根据不同领域的人类偏好进行评估。鼓励大家不仅关注总排行榜,还要查看各个类别的排名(如数学、编码等)。
- Arena 评估是实时进行的。鼓励大家在 Arena 中亲自对比模型,实时验证自己的假设。
- 透明性是我们的核心价值;所有代码和分析都是开源的(http://github.com/lm-sys/FastChat)。我们定期发布 20% 的数据,保留其余数据以避免过拟合,维护基准测试的完整性。
- 我们将根据政策发布随机的 20% GPT-4o mini 对战数据,大家可以亲自查看答案。
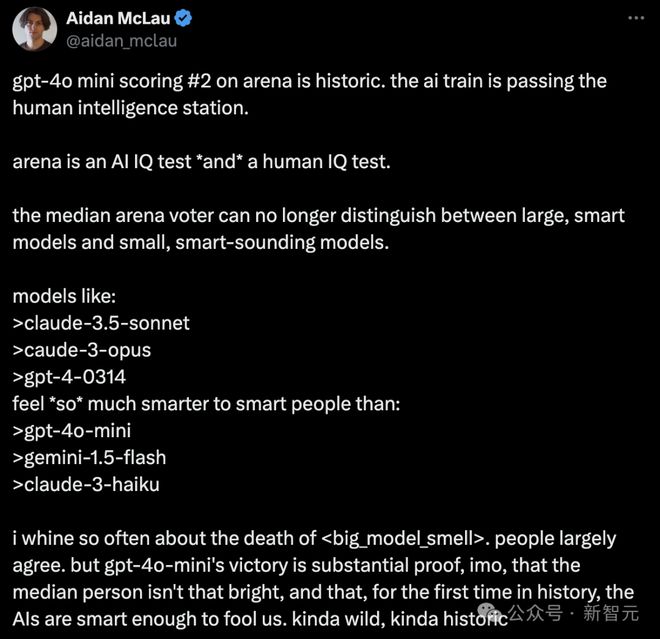
不过,另有网友认为,gpt-4o-mini 的胜利是一个实质性的证据,证明了普通人并不那么聪明。
而且,这是历史上首次,AI 变得足够聪明可以愚弄我们。有点疯狂,也有点具有历史意义。
参考资料:
https://x.com/moyix/status/1815840634013639086
https://x.com/HamelHusain/status/1815848198927434019






