
新智元报道
编辑:桃子乔杨
小模型时代来了?OpenAI 带着 GPT-4o mini 首次入局小模型战场,Mistral AI、HuggingFace 本周接连发布了小模型。如今,苹果也发布了 70 亿参数小模型 DCLM,性能碾压 Mistral-7B。
小模型的战场,打起来了!
继 GPT-4o mini、Mistral NeMo 发布之后,苹果也入局了。
DCLM 小模型包含两种参数规模——70 亿和 14 亿,发布即开源。最大 70 亿参数超越了 Mistral-7B ,性能接近 Llama 3、Gemma。

根据苹果 ML 小组研究科学家 Vaishaal Shankar(也是 DCLM 研发人员)的说法,这是迄今为止性能最好的「真正开源」的模型,不仅有权重和训练代码,而且是基于开放数据集 DCLM-Baseline。

相比模型性能,DCLM 做出的「真正开源」的典范更加引人关注。
对比大部分科技巨头只搞闭源模型,或「犹抱琵琶半遮面」,。

此外,Shankar 还预告说,之后会继续上线模型中间检查点和优化器状态。

难道,这就是 LLM 开源社区的春天了吗?

DCLM 系列全开源
目前,HuggingFace 上已经发布了全部模型权重,其中的模型卡已经基本涵盖了关键信息。
https://huggingface.co/apple/DCLM-7B
DCLM-7B 同样采用了 decoder-only 的架构,使用 PyTorch 和 OpenLM 框架进行预训练。
总共 4T token 的 DCLM-baseline 数据集来自于总量 240T 的 DCLM,DCLM-7B 模型又进一步过滤出其中的 2.5T 用于训练。

上下文长度为 2048,小于 Mistral 7B 和 Gemma 2 9B 的 8k 长度。
性能方面,作者直接使用评估套件 LLM Foundry,测试了模型在 53 个基准任务上的分数。
与其他模型进行比较时,除了 MMLU 分数,作者还自定义了两个指标——「核心准确率」(core)和「扩展准确率」(extended)。
前者是包括 HellaSwag 和 ARC-E 在内的 22 个任务中心准确率的均值,后者则涵盖全部 53 个任务。
与虽然使用的数据不是最多,但与其他同等大小的开放数据模型(权重与数据集都开源)相比,DCLM 在全部 3 个指标上的性能都达到了最佳。
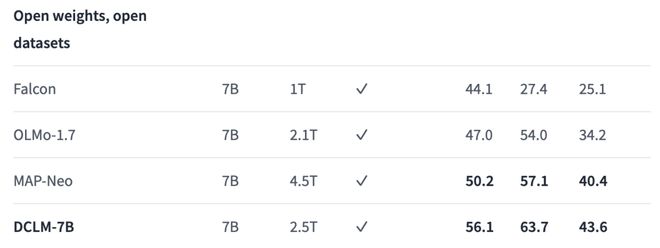
三列基准分数从左到右分别是:核心、MMLU、扩展
相比之前的 SOTA MAP-Neo 模型,DCLM-7B 在5-shot 的 MMLU 任务准确率达到 63.7%,提升了 6.6 个百分点,同时训练所需的计算量减少了 40%。
然而,如果和权重开源、数据集闭源的模型相比,效果就不尽如人意了。
DCLM 在各个指标上都与 Phi-3 存在不小差距,与 Mistral-7B-v0.3 或 Gemma 8B 的分数大致相当。
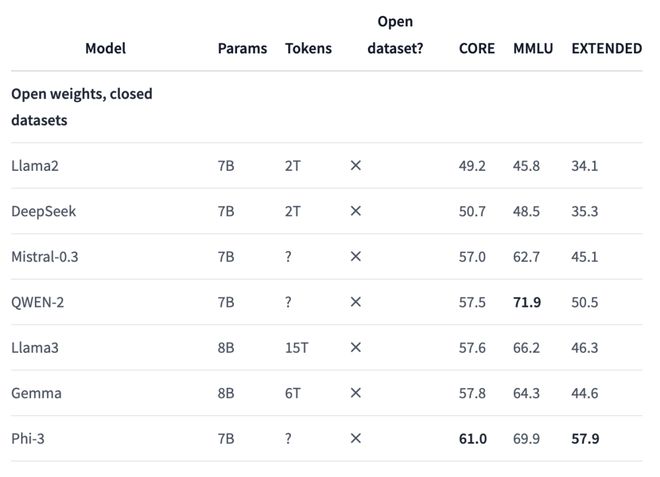
研究人员发现,如果使用同一数据集中额外的 100B 数据进行训练,并将上下文长度扩展到 8k 时,模型在核心和扩展基准上的分数还会进一步提升,但 MMLU 结果没有变化。

这个结果,就全面超过了 Mistral 7B-v0.3 的分数。
此外,HuggingFace 上还发布了 7B 模型的指令微调版本,在数学推理任务 GSM8K 上的性能实现大规模提升,分数由原来的 2.1 直接飙到 52.5。
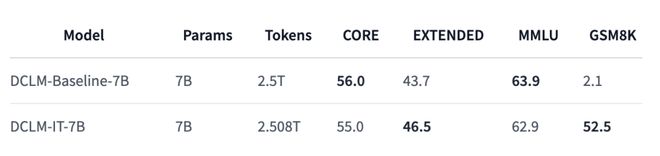
https://huggingface.co/apple/DCLM-7B-8k
除了 7B 版本,1.4B 版本也同步上线。神奇的是,训练数据量相比 7B 版本不降反增,多了 0.1T。

https://huggingface.co/TRI-ML/DCLM-1B
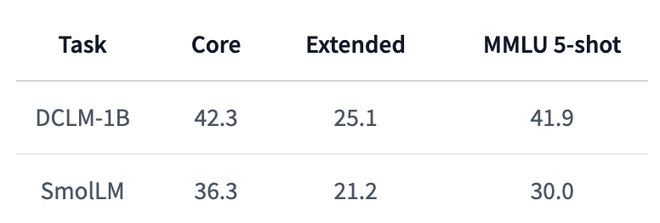
相比 HuggingFace 最近发布的 SmolLM,DCLM-1B 的性能显著更优,尤其是5-shot MMLU 分数,比 SmolLM 提升了 11.9%。
不仅如此,DCLM-1B 在 MMLU 上 41.9 的得分也同样高于 Qwen-1.5B 的 37.87 和 Phi-1.5B 的 35.90。
7B 模型落后的事情,反而让 1.4B 模型反超了,果然小模型才是苹果的看家本领。
值得注意的是,7B 模型仅能在 Apple 的示例代码许可(ASCL)下使用,但 1.4B 版本在 Apache 2.0 下发布,允许商业使用、分发和修改。
既然说到这次发布的 DCLM 系列模型,就不得不提它们的重要基础——DataComp 基准。

论文地址:https://arxiv.org/pdf/2406.11794
DataComp 这篇论文首发于 6 月 17 日,共同一作 Jeffrey Li、Alex Fang 和共同最后作者 Vaishaal Shankar,也同样都是苹果 DCLM 的研发人员。
文章不仅对数据集的构建过程进行了详细阐述,也提到了关于 DCLM 模型的部分内容。
Vaishaal Shankar 表示,将很快发布这篇论文的更新版,提供更多有关模型预训练的技术细节。
相比于对同一数据集修改模型,DataComp 的思路反其道而行之——测评所用的模型是固定的,任务是在总共 240T 的数据池中过滤、处理出最好的数据。
可以说,这种做法与科技巨头们的研发思路非常一致——对于 LLM 的性能而言,预训练数据正在成为比模型架构和权重更重要的因素。
毕竟,Llama、Gemma、Phi 等一系列「开源」模型都是只放权重、不公布数据。
既要 Scaling Law,又要 SLM
对于 AI 科技巨头来说,有时模型不是越大越好。

其实一直以来,AI 社区中,并不缺少小模型,比如微软 Phi 系列模型多次迭代,以及 6 月末谷歌刚刚更新的 Gemma 2 7B。
这周,OpenAI 突然发布 GPT-4o mini,Mistral AI 联手英伟达发布 Mistral NeMo,HuggingFace 的 SmoLLM 等小模型的发布,为小模型的领域再次添了一把火。
正如 OpenAI 研究员所言,「虽然我们比任何人都更喜欢训练大模型,但 OpenAI 也知道如何训练小模型」。

小模型,优势在于成本低、速度快、更专业,通常只使用少量数据训练,为特定任务而设计。
大模型变小,再扩大规模,可能是未来发展的趋势之一。

前两天,在 GPT-4o mini 发布时,Andrej Karpathy 也发表长推表达了类似的观点。

他认为,模型尺寸的竞争将会「反向加剧」,不是越来越大,反而是比谁更小更轻巧。
当前的 LLM 之所以逐渐变成「巨兽」,是因为训练过程仍然非常浪费,我们基本上是在要求模型记住整个互联网的内容(而且实际上,LLM 的记忆能力还相当不错,质量上比人类好很多)。
但对于小模型来说,训练目标已经改变。关键问题是,AI 系统如何从更少的数据中学到更多。
我们需要模型先变得更大,再变得更小,因为我们需要「巨兽」将数据重构、塑造为理想的合成形式,逐渐得到「完美的训练集」,再喂给小模型。
马斯克也表示同意这个观点。Karpathy 所描述的这个模型改进阶梯,正是现实中特斯拉曾走过的路。

23 年 4 月,Sam Altman 曾宣布了 AI 大模型时代终结。最近采访中,他还确认了数据质量是进一步 AI 训练的关键成功因素。

微软研究人员在开发 Phi 模型时,就提出了这样的假设。Hugging Face 的 AI 研究人员最近也证实了这一假设,并发布了一个高质量的训练数据集。
就以 GPT-4 为例,开发和使用超一万亿参数的成本超过了 1 亿美元。
而小模型,比如专在法律数据集上完成训练,可能使用不到 100 亿参数,成本不到 1000 万美元,使用更少算力响应每个查询,因此成本较低。
纳德拉曾表示,Phi⼩型模型系列规模仅为 OpenAI 背后免费模型1/100,而且在许多任务上的表现几乎同样出色。

除此以外,谷歌以及 AI 初创公司 Mistral、Anthropic、Cohere 今年也发布了规模较小的模型。
6 月,苹果曾公布了自己的 AI 发展路线图,计划使用小型模型,这样就可以完全在手机上运行软件,使其更快速和更安全。
对于许多任务来说,比如总结文档或生成图像,大模型可能有点大材小用。
Transformer 开山之作背后作者 Illia Polosukhin 表示,计算2+2 不应该需要进⾏千万亿次运算。
不过,科技巨头们也并没有放弃大模型。苹果在今年 WWDC 大会上,曾宣布了在 Siri 助手中植入 ChatGPT,以执行撰写电子邮件等复杂任务。
毕竟通往终极 AGI/ASI,参数规模的扩大和智能的增长成正比。

参考资料:
https://www.wsj.com/tech/ai/for-ai-giants-smaller-is-sometimes-better-ef07eb98?mod=tech_lead_story
https://the-decoder.com/ai-models-might-need-to-scale-down-to-scale-up-again/






