
新智元报道
编辑:桃子好困
两年一届的 ECCV 录用结果终于揭晓了!刚刚,ECCV 组委会公布了录用论文名单,共有 2395 篇论文被录用。
ECCV 2024 录用结果终于公布了!
一大早,ECC 组委会放出了所有被接受论文的 ID 名单,共录用了 2395 篇论文。

有网友估算了下,今年论文总提交量大约有 12600 篇,录用率是 18%。简直不敢相信今年 ECCV 的录用率如此之低,CVPR 2024 录用率还是 23.6%。

据统计,ECCV 2022 共有 5803 篇论文投稿,接收率为 28%。
再往前倒推,2020 年 ECCV 共收到有效投稿 5025 篇,接收论文 1361 篇,接收率为 27%。2018 年共有 2439 篇投稿,接收 776 篇,录用率为 31.8%。
ECCV 表示,在接下来的几天里,还将公布最终的评审意见和元评审意见。还有论文 Poster/Oral 结果也将在随后揭晓。
今年,是 ECCV 召开的第 18 届顶会,将于 9 月 29 日-10 月 4 日在意大利米兰正式开幕。

ECCV(欧洲计算机视觉国际会议)创办于 1887 年,每两年举办一次。
它与 CVPR(每年一届)ICCV(每两年一届)并称计算机视觉方向的三大顶级会议。

收到录用结果的小伙伴们,已经开始分享自己的成果了。
网友晒出成绩单
一位小伙伴 Jeff Li 同一天双喜临门,不仅收到了入职英伟达的 offer,同时 2 篇论文被 ECCV 接收。

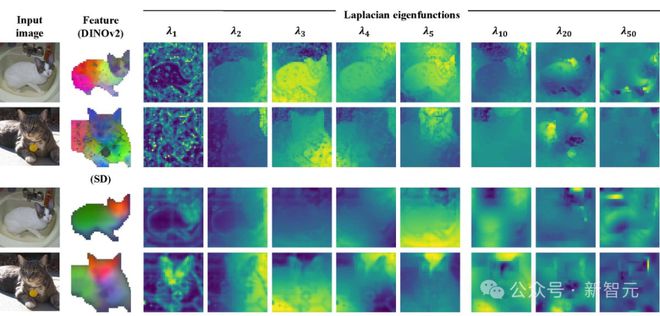
斯坦福计算机博士生,清华校友 Congyue Deng 实现了在噪声和特征不准确的情况下,获得更好的图像对应关系。

为此,作者提出了 Laplacian 特征函数,可以将图像对应问题性像素空间提升到函数空间,并直接优化全局一致的映射。
实验结果证明,新技术不仅能产生更平滑,而且更准确的对应关系,还能更好地反映作者所研究的大规模视觉模型中嵌入的知识。
论文地址:https://arxiv.org/abs/2403.12038
佐治亚理工学院 Bolin Lai 博士联手 Meta、UIUC 团队发表论文,提出了以自我为中心的动作框架——LEGO,由多模态模型和扩散模型组成,通过指令微调丰富动作提示。

最新框架的设计目标是,通过输入用户提示和以自我视角为中心的图像,基于用户的「上下文」(即动作帧)描述动作。然后用户再去学习,如何去无缝完成自己的工作。
论文中提出新模型能够按照指令生成一致的动作,并在动作过程中发生视点变化时,依旧保持一致性。此外,LEGO 模型还可以在相同的上下文中,推广到各种看不见的动作。

论文地址:https://arxiv.org/pdf/2312.03849
高斯泼溅
来自 UT Austin 的博士生 Zhiwen Fan,有 3 篇论文都被 ECCV 2024 接收了。
这几篇论文探索了许多新的领域:从稀疏视图进行 3D 重建、高质量 3D 多任务学习,以及使用全景格式的大规模 3D 生成。
在 DreamScene360 中,作者提出了一种 3D 全景的场景级别生成流程,该流程利用 GPT-4V 结合 2D 扩散模型和全景高斯泼溅技术,从任何具体程度的文本提示中生成具有完整 360 度覆盖的沉浸式高质量场景,实现了卓越的 3D 场景生成质量和实时的渲染速度。

项目地址:https://dreamscene360.github.io/

在 FSGS 中,作者提出了一种基于 3D 高斯泼溅的稀疏视角合成框架,该框架能够在仅有三张训练视图的情况下实现实时和高质量的视角合成。
作者通过精心设计的高斯 Unpooling 过程来处理稀疏的 COLMAP 点云,并在最具代表性的位置周围迭代分布新的高斯,随后在空白区域填充局部细节。
此外,作者还在高斯优化过程中集成了一个大规模预训练的单目深度估计器,利用在线增强视图引导几何优化走向最佳解决方案。
从有限输入视点观察到的稀疏点开始,FSGS 可以准确地扩展到未见过的区域,全面覆盖场景并提升新视角的渲染质量。
总体而言,FSGS 在包括 LLFF、Mip-NeRF360 和 Blender 在内的各种数据集上,在图像质量达到了 SOTA 的性能,渲染速度比基于 NeRF 的方法快2,000 倍以上。

项目地址:https://zehaozhu.github.io/FSGS/

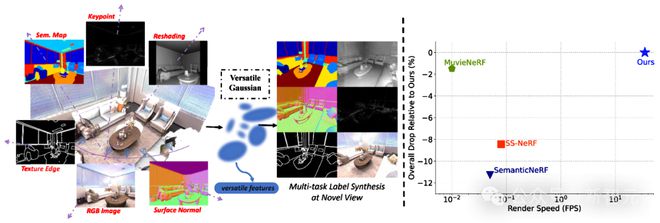
在 VersatileGaussian 中,作者提出将 Multi-task Learning 引入 Gaussian Splatting,来提升全任务的重建质量,尤其是 RGB 图像渲染质量得到明显提升。
本文提出特征图 Rasterizer,以及任务间的相关注意模块,能通过一种软加权机制传播任务特定知识,促进跨任务相关性学习,从而取得明显优越的性能。
在 ScanNet 和 Replica 数据集上的实验表明 VersatileGaussian 取得了明显优越的渲染质量和速度。

项目地址:https://shadowiterator.github.io/VersatileGaussian-Homepage/
图像编辑
UCSC 的助理教授 Xin Eric Wang 则带领团队提出了一种图像个性化编辑 SwapAnything 框架。

基于此,你便可以看到肌肉发达的 LeCun 大牛拍着小猫咪;乌龟的龟壳,也可以是美国队长盔甲的印记。
正如作者所述,SwapAnything 可在个性化可视化编辑中实现任意对象「交换」,包括单对象、部分对象、多对象、跨域、基于文本的「交换」等。
它有三个独特的优势:精准控制任意对象和部件,而不是主体;原封不动地保存上下文像素;个性化概念与形象的无缝改编。

论文地址:https://arxiv.org/pdf/2404.05717
ChatGPT 中的 DALL·E却无法利用参考概念,进行个性化视觉编辑。
在它支持的基于文本的编辑任务上,SwapAnything 也能实现更稳健的性能。

图像合并
谷歌研究科学家、DreamBooth 作者 Nataniel Ruiz 和团队提出的 ZipLoRA 算法,正式被录用。

在 AI 社区中,合并 LoRA 一直是一个热门话题,但调优过程可能非常繁琐。
谷歌和 UIUC 提出的 ZipLoRA 算法,可以让开发者轻松地将任何主体 LoRA 与任何风格 LoRA 结合起来。
这一方法的核心思想很简单:通过反向传播找到一个合并点,在这一点上两个 LoRA 都能很好地发挥作用,同时还能限制它们之间的信号干扰。
如下图所示,ZipLoRA 保留了令人印象深刻的细节主题,非常逼真地再现了用户给出的风格。

论文地址:https://arxiv.org/pdf/2311.13600
与社区其他类似方法相较之下,比如 direct arithmetic merge、StyleDrop+DreamBooth 等,ZipLoRA 更好地实现了主题保真度,以及风格指令遵循。

图像生成
英伟达高级研究科学家 Ali Hatamizadeh 刚刚宣布,团队提出的图像生成 ViT 算法 DiffiT 被 ECCV 2024 接收。
在这篇论文中,作者提出了扩散视觉 Transformer(DiffiT)用于图像生成。
具体来说,它们提出了一种对去噪过程进行精细控制的方法,并引入了时间依赖多头自注意力(TMSA)机制。
DiffiT 在生成高保真度图像方面显示出惊人的效果,同时有着更好的参数效率。

论文地址:https://arxiv.org/pdf/2312.02139
字体文本生成
微软高级研究科学家 Yuhui Yuan 发文称,FontStudio 模型已被 ECCV 2024 录用。

正如模型名字所示,这是用于生成连贯一致字体效果的形状自适应扩散模型。
为了训出这个模型,研究人员精心策划了一个高质量形状自适应图像-文本数据集,并将分割掩码作为视觉输入条件,以引导不规则画布内图像生成的功能。
其次,为了保持多个字母之间的一致性,他们还提出了一种免训练的形状自适应效果转移方法,用于将纹理从生成的参考字母转移到其他字母。
实验结果显示,与无可匹敌的 Adobe Firefly 相比,用户在微软提出的 FontStudio 上的偏好更明显。

论文地址:https://arxiv.org/pdf/2406.08392
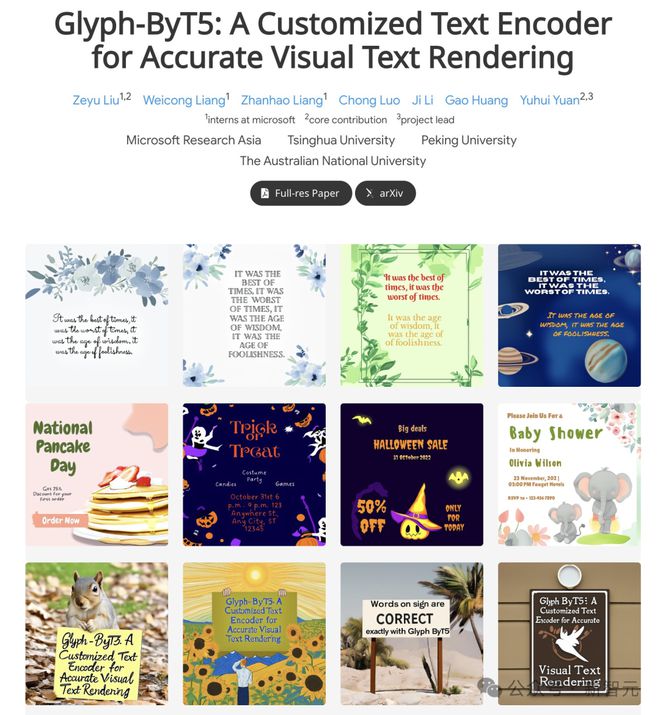
另外一篇微软联手清华北大、澳大利亚国立大学提出的文本编码器 Glyph-ByT5 也被录用。

为了实现准确的文本渲染,研究人员确定了对文本编码器的两个关键要求:字符识别和与字形对齐。
他们提出了一种将 Glyph-ByT5 与 SDXL 有效集成的方法,从而创建了用于设计图像生成的 Glyph-SDXL 模型。
这显著提高了文本渲染的准确性,在作者设计的图像基准测试中,模型准确率从不到 20% 提升到了近 90%。
值得注意的是,Glyph-SDXL 新获得了文本段落渲染的能力,可以为数十到数百个字符实现高拼写准确率,并且具有自动多行布局功能。
论文地址:https://arxiv.org/abs/2403.09622
你的论文被录用了吗?
最后借用网友一句勉励的话,「不论你的论文是否被 ECCV 录用,请记住你的价值和研究意义不仅仅局限于一个会议。每一次被拒都是走向成长的一步。继续前进,相信你的工作」!

参考资料:
- https://x.com/eccvconf/status/1807781867250155582
- https://x.com/WayneINR/status/1807798310071377945
- https://x.com/CongyueD/status/1807804473311637875
- https://x.com/bryanislucky/status/1807918906151194726
- https://x.com/natanielruizg/status/1807838353129177293
- https://www.reddit.com/r/MachineLearning/comments/1dsutwd/discussion_eccv_decisions_out_borderline_paper/






