
新智元报道
编辑:LRST
本文研究发现大语言模型在持续预训练过程中出现目标领域性能先下降再上升的现象。本文引入「稳定性差距」概念来解释该现象,并提出了三种策略来缓解问题。首先,本文提出在适当大小的数据子集上进行多轮预训练,能比单轮大数据集预训练更快的性能恢复。其次,应选取最高质量的子语料进行多轮预训练。最后,通过混合数据来接近预训练数据分布。这些策略在医疗领域的持续预训练和指令精调中均显著提升效果和削减计算量。相关 Llama-3-Physician-8B 模型现已开源于 HuggingFace。
大规模语言模型(LLMs)的持续预训练是提升其在特定领域性能的重要方法。通过在新领域的语料库上预训练大语言模型,这一过程能够显著增加模型的领域知识储备和任务能力。
然而,尽管已有许多研究探讨了从头预训练的 LLMs 的学习机制和性质,关于持续预训练过程中 LLMs 行为的研究却相对较少。
最近北京大学、香港科技大学等开源了一个 8B 医学大模型,通过测试模型在连续预训练和指令微调实验过程中的表现变化,发现了许多有趣的现象。

论文链接:https://arxiv.org/abs/2406.14833
开源地址:https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct
先下降后上升: 模型训练中存在的稳定性缺失问题
本文首先选取 TinyLLaMa-1b 和 OpenLLaMA-3b 模型作为基座模型,并在 5 百亿医疗 tokens 上做做连续单轮预训练。在预训练过程中,作者每隔 5b 测试一次模型在医疗维基语料上的困惑度(PPL)和下游医疗任务的平均表现。
如图 1 所示,尽管模型在医疗维基语料上的困惑度持续下降(图 1b),但在连续预训练初期,模型在医学任务上的表现却出现了下降 (图 1a)。随着更多数据的训练,任务表现逐渐恢复并超过了原始模型的水平 。
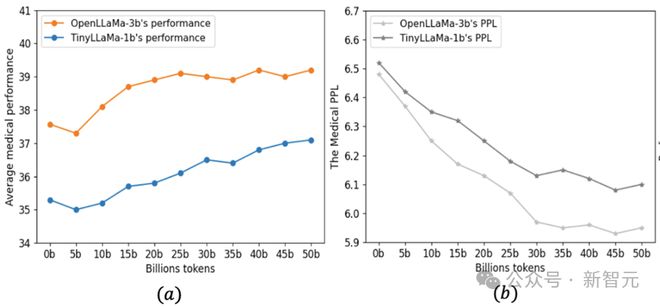
图1:(a)预训练过程中模型在四个医疗 QA 任务上的平均表现(b)预训练过程中模型在医疗维基语料上的困惑度
为了解释表现先下降后上升的行为,我们借鉴了持续学习中的稳定性差距概念。基于它的解释,医疗任务表现最初下降是因为学习新领域的可塑性梯度超过了维持通用任务能力的稳定性梯度,导致未能维持医疗任务的性能。随后,任务损失增强了稳定性梯度,这一前后稳定性差距最终导致性能恢复并上升。
为了验证以上假设,我们进一步测试了模型在医疗持续预训练中的通用任务表。如图 2 显示,一般任务性能呈现类似的V形曲线,表明一般指令跟随能力在最初下降后恢复。
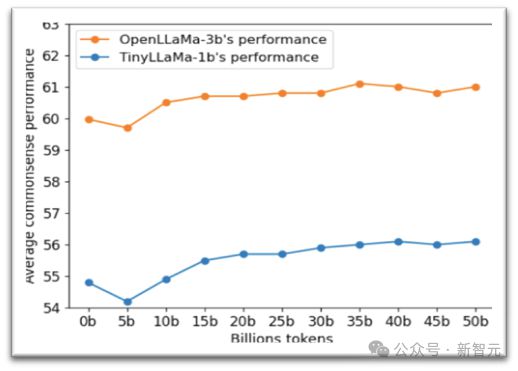
图2:预训练过程中模型在 10 个常识和阅读理解任务上的平均表现
三个针对稳定性差距的训练策略
为了克服持续预训练中存在的稳定性差距问题,本文提出了三种有效策略:
策略1:在适当大小的数据子集上进行多轮预训练,而不是在大数据集上进行单轮预训练。这种策略减少了每次预训练所需的高可塑性梯度,促进了稳定性梯度的上升,进而加速了性能恢复。
策略2:仅在高质量的子语料库上进行预训练,以快速提升特定领域的性能。
策略3:按照预训练数据分布采取其它来源的数据并和医疗高质量数据混合训练,减少预训练分布和连续预训练差距,促进模型稳定性梯度的形成。
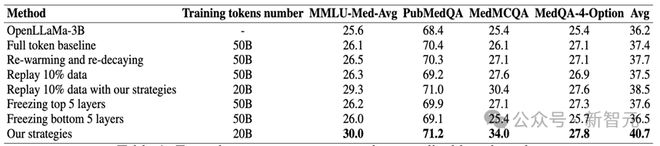
表1:在医疗预训练完成后模型在四个医疗任务上的 zero-shot 表现
实验结果:本文通过对比多种基线方法来验证提出的三条策略的有效性, 其中包括 500 亿医疗数据单轮训练、学习率 Re-warming and Re-decaying、重采样和参数固定等基线。
如下表 1 所示,基于本文的策略,OpenLLaMa 模型只需要在高质量 50 亿数据上训练 4 个轮次(即原计算预算的 40%),便可以在医疗任务平均表现上显著超越了所有基线,尤其在 PubMedQA 等医学问答任务中表现突出。
面向 GPT4 水平的 8B 医疗专家模型
连续预训练:本文按照提出的三种策略对 Llama-3-8B 模型做进一步的医疗连续预训练。在这个过程中使用了 50 亿高质量医学数据,并对模型做四个轮次的重复训练。
指令微调:连续预训练完成后,本文采用多个类型的医疗任务指令对模型做指令微调,包括问答任务、分类任务、关系提取任务、自然语言推理任务和总结任务。
微调过程中,研究团队继续采用提出的三种策略来优化指令微调效果。首先是多轮次训练,这在医学指令微调过程中是常见的。其次,利用 Deita 自动指令数据选择器,选择高质量的医学指令数据子集。最后,使用高质量的通用指令数据集,如 Airoboros-3.2,以缓解模型在通用任务完成能力上的遗忘。
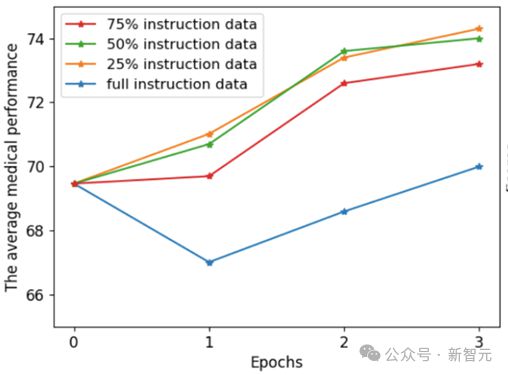
图3:指令微调过程中模型的医疗平均表现
如图 3 所示,在指令微调过程中,使用所有数据做微调仍然可能在初始训练阶段时面临表现下降问题。而通过我们的三种策略,模型仅需 25% 的指令数据就能达到最佳性能,这降低了计算资源的消耗。
实验比较:本文进一步将达到最佳表现的指令微调模型 Llama-3-Physician-8B-insturct 与其它医疗模型比较。如表 2 所示,Llama-3-Physician-8B-insturct 在医疗问答任务上明显优于其它同尺寸的开源模型,并且超过了闭源的 GPT-3.5-turbo 模型。同时,它的平均医疗问答任务表现也接近 GPT-4.
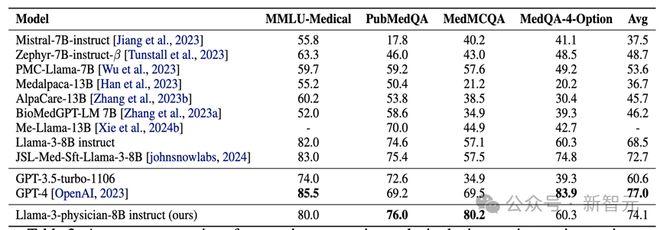
表2:指令微调结束后各模型在四个医疗问答任务上的 zero-shot 表现
本文进一步考虑 Llama-3-Physician-8B-insturct 在其它类型(非问答)的医疗任务上的表现。如表 3 所示,Llama-3-Physician-8B-insturct 在医疗分类,关系抽取,推理和总结任务上都取得了优异表现,且明显超过 GPT-4 表现。
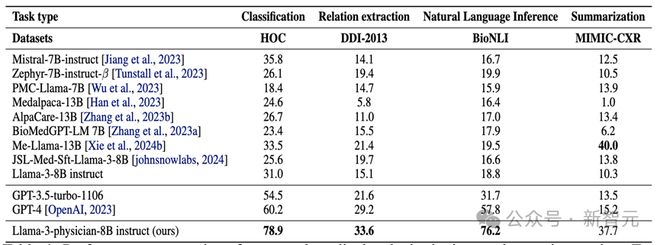
表3:指令微调结束后各模型在医疗分类,关系抽取,推理和总结任务上的 zero-shot 表现
总结
1. 本论文研究了在对 LLMs(大语言模型)进行新领域语料库的连续预训练时的行为,并观察到模型初始性能下降,随后缓慢恢复的现象。本文使用稳定性差距这一概念来描述这一现象,并从可塑性和稳定性梯度的角度对此解释
2. 本文进一步提出了三种有效提高 LLM 在特定领域表现并降低计算成本的策略,从而克服稳定性差距。这些策略包括:在适当大小的数据子集上进行多轮预训练,选取高质量子集和按预训练数据分布混合采样数据。
3. 本文将这些策略应用于最新的 Llama-3-8B 模型的连续预训练和指令微调过程中,所得到的 Llama-3-Physician-8B-insturct 不仅在同规模开源模型中表现最强,并且优于闭源的 GPT-3.5 模型,接近 GPT-4 的表现。
参考资料:






