
新智元报道
编辑:LRST
【新智元导读】本文将为大家介绍 CVPR 2024 Highlight 的论文 LangSplat: 3D Language Gaussian Splatting(三维语义高斯泼溅)。LangSplat 在开放文本目标定位和语义分割任务上达到 SOTA 性能。在 1440×1080 分辨率的图像上,查询速度比之前的 SOTA 方法 LERF 快了 199 倍。代码已开源。
人类生活在一个三维世界中,并通过文本语言描述三维场景,构建三维语义场以支持在三维空间中的开放文本查询最近越来越受到关注。
最近,来自清华大学和哈佛大学的研究人员共同提出了 LangSplat,该方法结合三维高斯泼溅技术重建三维语义场,能够实现准确高效的开放文本查询。现有方法在 NeRF 的基础上嵌入 CLIP 语义特征,LangSplat 则通过结合三维高斯泼溅,在每个高斯点上编码了从 CLIP 提取的语义特征。

Project Page: https://langsplat.github.io/
Paper: https://arxiv.org/pdf/2312.16084.pdf
Video: https://youtu.be/K_9BBS1ODAc?si=gfo5TrLK-htyWyuT
Code: https://github.com/minghanqin/LangSplat
采用 tile-based 的三维高斯泼溅技术来渲染语义特征,从而避免了 NeRF 中计算成本高昂的渲染过程。

LangSplat 首先训练特定场景下的语义自编码器,然后在场景特定的低维 latent space 上学习语义特征,而不是直接学习高维的 CLIP 语义特征,从而降低了计算量。现有基于 NeRF 的方法的三维语义场比较模糊,无法清晰地区分目标的边界。
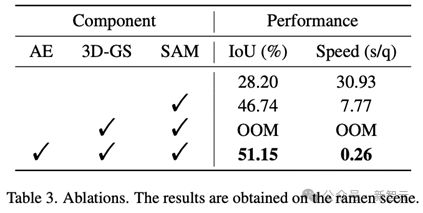
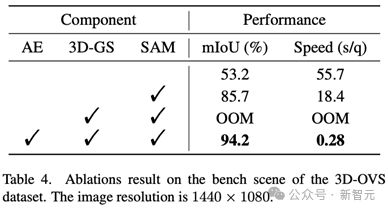
本文深入研究了这一问题,提出使用 SAM 学习多层次语义,在不引入 DINO 特征的情况下获得了更准确的语义场。广泛的实验结果表明,LangSplat 在开放文本目标定位和语义分割任务上的性能显著超过了之前的 SOTA 方法 LERF。
值得注意的是,LangSplat 在 1440×1080 分辨率的图像上,查询速度比 LERF 快了 199 倍。
在 3D 场景中进行开放文本查询对于机器人导航、3D 编辑和增强现实等应用非常重要。目前的方法,例如 LERF 在神经辐射场中嵌入 CLIP 语义特征,受到速度和准确性的限制。
本文提出的方法 LangSplat 显著提高了效率和准确性,为落地应用提供了一种有前景的方案。
该工作目前在X(Twitter)上受到广泛关注。被清华大学官方账号以及 AK 转载,论文视频累计浏览量超过 100,000,论文代码已开源。
方法论
层次语义学习:LangSplat 利用 Segment Anything Model(SAM)学习层次语义,解决了三维语义场的边界模糊问题。
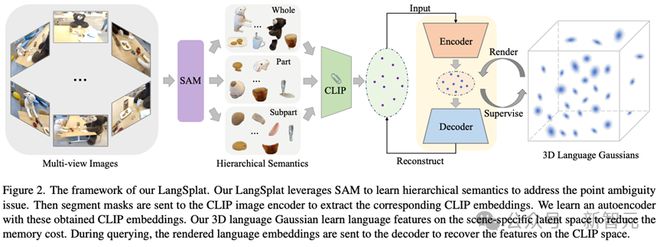
3D 语义高斯泼溅:LangSplat 引入了一种新的技术,即 3D 高斯泼溅,它使用包含语义特征嵌入的 3D 高斯来表示 3D 场景。这种方法比 NeRF-based 的方法渲染过程更快。
特定场景的语义自编码器:为了缓解高维语义特征嵌入导致的内存 out of memory 问题,LangSplat 构建特定场景的语义自编码器将这些文本语义特征降维。
层次语义学习
在本文中,我们利用 SAM 来获得实例级的精确对象掩码,然后用这些掩码对应的图像区域提取像素对齐的特征。我们还明确地建模了 SAM 定义的语义层次,以解决点模糊性问题。
具体来说,我们将一个 32 × 32 点提示的常规网格输入 SAM,以获得三个不同语义层次下的掩码:分别代表子部分、部分和整体层次的掩码。
然后基于 SAM 预测的 IoU 分值、稳定性分值和掩码之间的重叠率,为每一组掩码去除冗余的掩码。每个过滤后的掩码集合独立地根据其各自的语义层次做全图分割,从而得到三个分割图:。
这些分割图准确地勾勒出对象在其层次结构中的边界,有效地将场景划分为语义上有意义的区域。通过获得的分割图,我们继续为每个分割区域提取 CLIP 特征。
数学上,得到的像素对齐的语义嵌入是:
如此,从三维语义场景渲染的每个像素都具有与其精确语义上下文相匹配的 CLIP 特征。这种匹配减少了模糊性,提高了基于语义的查询的准确性。
此外,由于我们在「整体」、「部分」和「子部分」层次上都有不同的分割图,我们可以直接在这些预定义的尺度上查询三维语义场。这消除了在多个绝对尺度上进行密集搜索的需要,使查询过程更加高效。
3D 语义高斯泼溅
在一组 2D 图像上获得语义嵌入后,我们可以通过建模 3D 点和 2D 像素之间的关系来学习一个 3D 语义场。
大多数现有方法使用 NeRFs 进行 3D 建模,但它们面临着耗时的渲染过程。为了解决这个问题,我们提出了基于 3D 高斯散射的 3D 语义场建模方法。
这种 3D 高斯散射方法明确地将 3D 场景表示为各向异性的 3D 高斯分布的集合,每个高斯分布由均值和协方差矩阵描述:
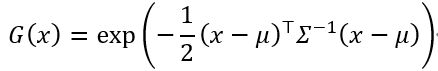
3D 高斯投影到 2D 图像平面上后,用基于 tile 的光栅化策略进行渲染:
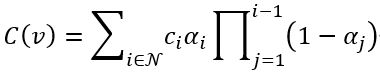
其中,ci 是第 i 个高斯的颜色,N 表示瓦片中的高斯数量, 是在像素 v 处渲染的颜色, 。
这里 oi 是第 i 个高斯的不透明度, 代表投影到二维上的第 i 个高斯的函数。
在本文中,我们提出了 3D 语义高斯,为每个高斯增加三个语义嵌入 。
这些嵌入源自 CLIP 特征,捕捉了 SAM 提供的层次语义。增强后的高斯被命名为 3D 语义高斯。并采用基于 tile 的光栅化器以保持渲染效率:

其中, 代表在像素v处以语义层次l渲染的语义嵌入。通过直接将语义信息引入高斯中,我们使三维语义场能够响应基于文本的查询。
特定场景的语义自编码器
作为一种显式建模方法,表征一个复杂场景可能需要数百万个 3D 点。直接在高维的 CLIP 潜空间直接学习高斯的语义特征会显著增加内存消耗,容易导致「内存不足」的问题。
为降低内存消耗并提高效率,我们引入了基于场景的语义自编码器,将场景中的 CLIP 嵌入映射到低维潜在空间。
CLIP 模型是通过 4 亿对(图像,文本)训练的,其D维潜在空间可能非常紧凑。然而,我们在这里训练的语义场Φ是特定于场景的,这意味着我们可以利用场景先验知识压缩 CLIP 特征。
事实上,对于每个输入图像,我们将获得由 SAM 分割的数百个掩码,这显著少于 CLIP 训练中使用的图像数量。因此,场景中的所有分割区域在 CLIP 潜在空间中稀疏分布,使我们能够通过基于场景的自编码器进一步压缩这些 CLIP 特征。
实验
实验设置:实验测试了该方法在开放词汇 3D 对象定位和语义分割任务上的性能,使用的数据集包括 LERF 和 3D-OVS。
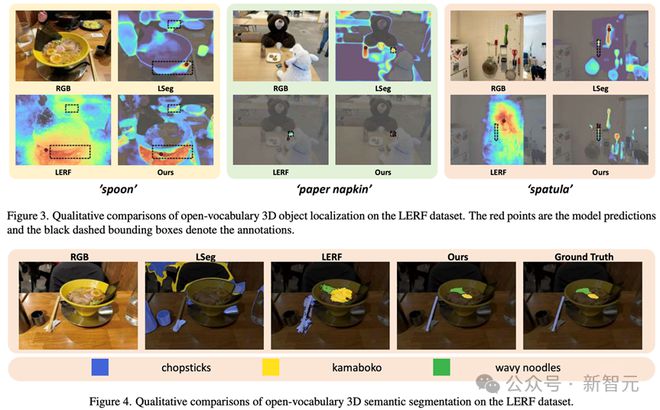
结果:LangSplat 显著优于先前的最先进方法。特别是,它在 1440×1080 分辨率下比 LERF 快 199 倍,显示出在速度和效率上的显著提高。
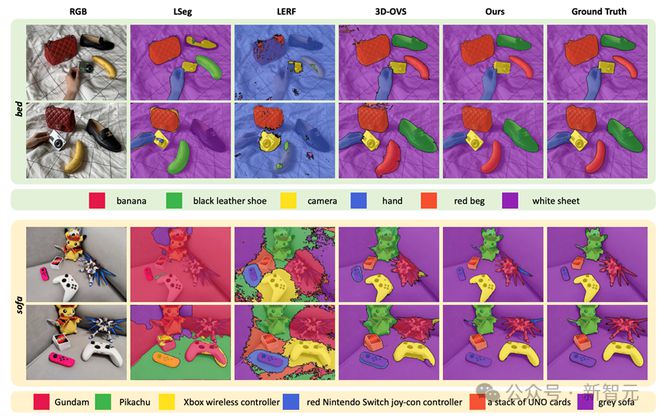
可视化和消融研究:论文包括了详细的可视化和消融研究,展示了 LangSplat 各组成部分的有效性。
贡献
1. 通过引入带有语义特征的 3D 高斯泼溅来进行三维场景感知。
2. 与以前的方法相比,实现了显著的速度提升,使其适合实时应用。
3. 通过采用层次语义和新的渲染技术,LangSplat 提高了 3D 语义场的精确度。
4. 通过使用场景特定的自动编码器,减少了处理高维数据所需的计算和内存开销。
参考资料:






