
癌症一直是人类面临的最具有挑战性的疾病之一,据统计每年有超过 1900 万的新发病例和 1000 万死亡病例。早期检测出癌症同时结合已有的治疗手段,可以显著提高各种癌症类型的生存率和治疗效果。
如今,人工智能(AI)有望加快这一过程,医生可能很快就能利用 AI 来检测和诊断患者的癌症,从而尽早进行治疗。
日前,来自伦敦帝国理工学院和剑桥大学的研究团队训练了一种人工智能模型——EMethylNET,通过观察 DNA 甲基化模式,从非癌组织中识别出 13 种不同类型的癌症(包括乳腺癌、肝癌、肺癌和前列腺癌等),准确率高达 98. 2%。
相关论文以“Early detection and diagnosis of cancer with interpretable machine learning to uncover cancer-specific DNA methylation patterns”为题,已发表在 Biology Methods and Protocols 上。

据论文描述,该模型依赖于组织样本(而不是血液中的 DNA 片段),目前还处于实验阶段,需要对更多样化的活检样本进行额外的训练和测试,方可进一步用于临床。
研究人员认为,这项研究的一个重要意义在于使用了一个可解释的人工智能模型,为其预测背后的逻辑提供了说明。该研究同时探索了他们的模型的内部工作原理,发现了该模型在理解致癌潜在过程方面有显著提升。
多分类模型表现出色,准确率超过 98%
癌症一直是人类面临的最具有挑战性的疾病之一。癌症的演变特性极为复杂,治疗难度会随着发现时间的推移而提升。癌症的早筛至关重要,是医学界一直努力攻克的重要方向之一。
遗传信息通过 DNA 中的四种碱基(A、T、G和 C)的模式进行编码。细胞外的环境变化可能导致某些 DNA 碱基通过添加甲基团而被修改,这一过程称为“DNA 甲基化”。每个细胞都拥有数百万这样的 DNA 甲基化标记。研究人员在癌症早期发展过程中观察到了这些标记的变化,判断它们可能有助于癌症的早期诊断。识别特定于不同癌症类型的 DNA 甲基化特征,就像大海捞针一样困难。
在这项工作中,研究团队利用机器学习方法从正常组织特异性甲基化中识别出癌症特异性变化,利用了来自 13 种癌症类型和相应正常组织的 DNA 甲基化微阵列数据。基于 Illumina Infinium 阵列的甲基化组数据,并按照方法中所述提取、清理和处理数据。分析该甲基化微阵列数据,使用一对甲基化和未甲基化探针确定给定 CpG 位置的甲基化探针强度与总体强度的比率(称为 beta 值)。
他们训练并评估了四种不同的模型类型:逻辑回归、支持向量机(SVM)、梯度提升决策树(XGBoost)和深度神经网络(DNN)。对于前三种模型类型,创建了二分类和多分类模型。
由于二元逻辑回归模型的表现并不明显优于二元 XGBoost 模型,并且多类逻辑回归的 MCC 得分低于多类 XGBoost 和 DNN,因此研究将分析重点放在 XGBoost 和 DNN 上。
在这些独立数据集上进行测试时,大多数二元 XGBoost 模型(在 TCGA 数据上训练)表现良好。为了创建更稳健的模型并改进这些结果,研究人员设计了 EMethylNET, EMethylNET 是一种由 DNN 模型组成的模型,该模型基于从多类 XGBoost 中学习到的特征进行训练,可进一步提高性能。
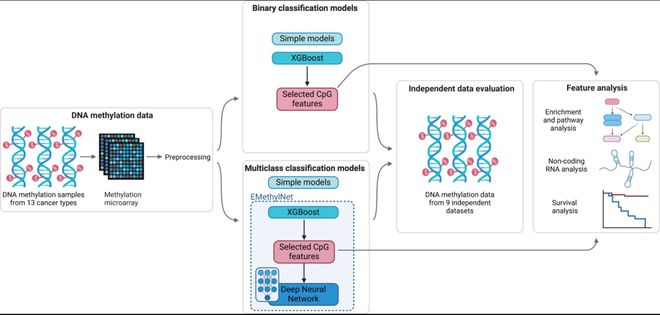
图方法概述
通过对单个肿瘤和正常组织的 DNA 甲基化进行二元分类来检测癌症状态,13 个模型中有 5 个(COAD、KIRC、LUAD、LUSC 和 UCEC)实现了完美的测试集性能。在所有模型中,平均准确率为 98.7%,平均 MCC(不受严重类别不平衡影响的性能指标)为 91.9%。
他们在整个训练数据上训练了一个多类 XGBoost 模型,该模型可以高度准确地区分 13 种癌症类型和正常样本,总体准确率为 98. 2%,总体 MCC 为 98. 0%。同时模型在独立的异构数据集上实现高精度,在独立数据集上也表现出良好的性能。
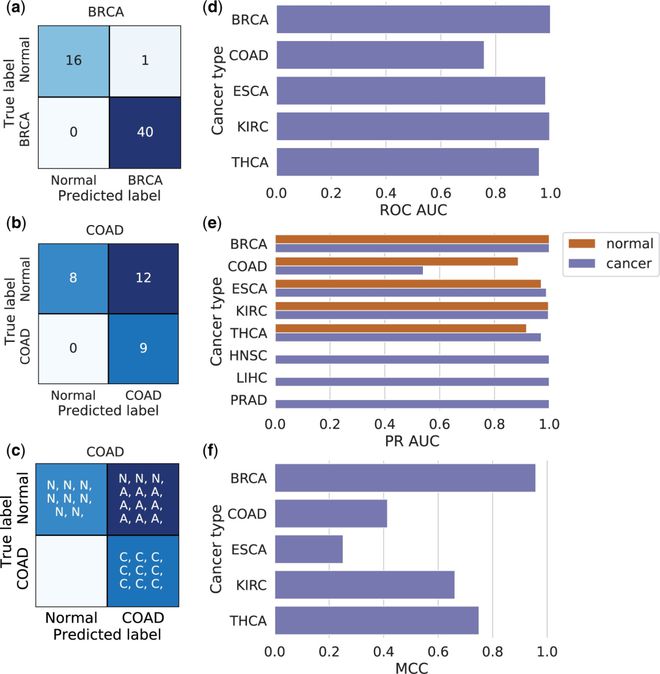
图二元 XGBoost 模型在独立数据集上的性能
使用基于甲基化的方法对癌症进行检测和分类的文献数量庞大,而且还在不断增加。EMethylNET 与其他相关研究进行了比较分析,证明 EMethylNET 在同类作品中实现了具有竞争力的测试集性能。
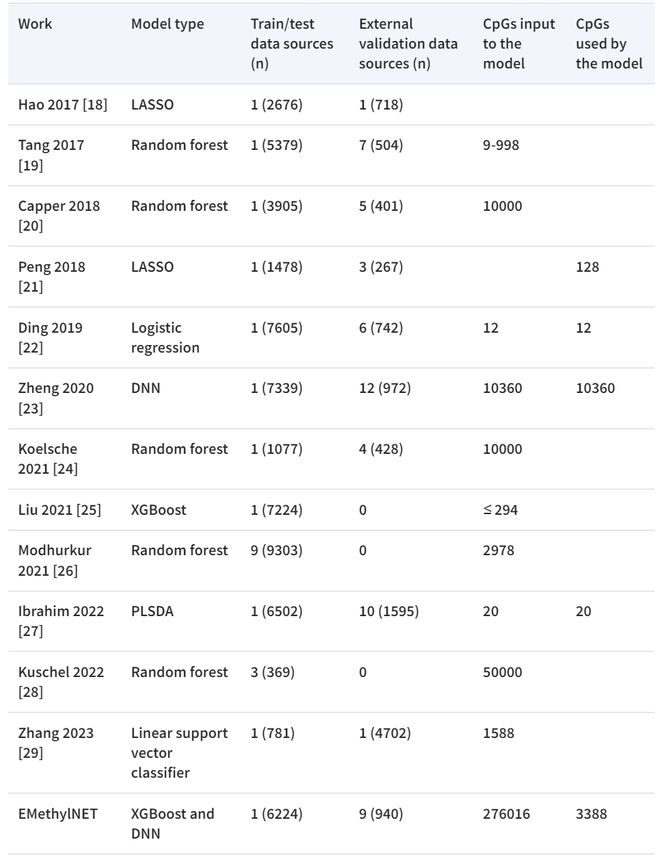
表相关研究汇总
多类基因与癌症相关过程息息相关
使用可解释方法(比如 XGBoost)的一个关键优势是可以识别用于分类的特征 ,研究团队从多类 XGBoost 模型(即 EMethylNET 的输入特征)中探索了 PCC。PCC 可以映射到近端基因——基因体或启动子区域(作为转录起始位点上游 1500 个碱基对窗口)与 PCC 重叠的基因,通过将多类 PCC 映射到近端基因而获得的基因称为“多类基因”。
他们对多类基因进行功能富集分析,发现其富含有助于致癌作用和转录调控特征的基因,并在癌症相关通路和网络中富集。多类基因组由 229 种已知的肿瘤抑制因子和致癌基因、546 种转录调节因子组成,并参与广泛的癌症相关途径和过程。
此外,他们还发现,基因列表包含许多非编码 RNA 基因,主要由 lncRNA 组成。这与越来越多的研究表明 lncRNA 和其他非编码 RNA 在致癌作用中起关键作用的观点一致。
与相关研究相比,该研究是第一个提供深入的特征分析,其中 CpG 由模型自由选择,没有事先的特征选择会给特征分析结果增加潜在偏差。
AI 预测癌症指日可待?
“通过在更多样的数据上更好的训练以及在临床上的严格测试,像这样的计算方法最终将提供可以帮助医生进行癌症早期检测和筛查的 AI 模型,”该论文的通讯作者 Shamith A Samarajiwa 说。“这将提供更好的治疗结果。”
根据训练数据的可用性,此方法可以扩展到检测数百种癌症类型。未来的应用包括将这种方法扩展到游离 DNA 的 DNA 甲基化数据,最终目标是通过液体活检方法早期检测多种类型的癌症。
此外,这种方法的一个明确的临床应用是筛查特定癌症类型或来源不明的癌症,尽管目前的模型并未为此目的进行优化,但已具备这方面的拓展研究空间。
参考链接:
https://academic.oup.com/biomethods/article/9/1/bpae028/7696058






