
新智元报道
编辑:编辑部
如何无痛玩转 Llama 3,这个手把手教程一看就会!80 亿参数推理单卡半分钟速成,微调 700 亿参数仅用 4 卡近半小时训完,还有 100 元代金券免费薅。
就在昨天,许多网友纷纷表示,自己收到了 OpenAI 暂用 API 的邮件。
邮件中,OpenAI 宣布自 7 月 9 日起,将不再对中国等不支持国家的用户提供 API 服务。
许多开发者听到之后,犹如晴天霹雳,在 AI 圈里可是吵翻了天。这意味着,不仅是国内开发者,就连企业,都需要寻找新的解决方案。
现在看来,能与 GPT-4 分庭抗礼的 Llama 3 大模型,无疑是一个不错的选择。
Llama 作为一个完全开源的模型,只要我们有机器,就相当于有了可以不限使用次数的大语言模型帮忙处理任务。
甚至,可以微调这个模型来实现适合自己需求的独特业务场景!
不过,在使用 Llama 3 之前,还需先在 Meta 这边填一个表格,并签一个长长的英文协议;然后会被指引到一个 GitHub 地址,并收到一个邮件链接去下载模型。
此外,如果想体验最大、效果最好的 700 亿参数模型,下载所需的时间也十分「令人酸爽」,尤其是在没有科学加速的情况下。
因为我们一直没有下好 Llama 3 的模型权重, 所以今天没法带大家体验了,此贴到此结束。 (不是)
开玩笑的,我们最近发现了一家宝藏公司,所有的下载和配置都已经提前帮我们完成了!
不但 700 亿参数需要耗费 132GB 存储的模型已经放在了公开数据中,而且还配置好了 Llama 3 的推理和训练微调环境。
换句话说就是,完全不用操心代码库的依赖安装问题,直接上手用就完事了。
更幸运的是,他们的机器真的很便宜!

潞晨云平台:https://cloud.luchentech.com/
话不多说,在完成潞晨云账户注册充钱等一系列流程后,我们就开了个机器试了一波。
推理
Llama 3 80 亿参数的模型
根据 Llama 3 官方网址用 80 亿参数的模型推理只需 1 卡,而 700 亿的模型需要 8 卡。
接下来,我们先来试试用单卡跑较小的 80 亿模型进行推理。
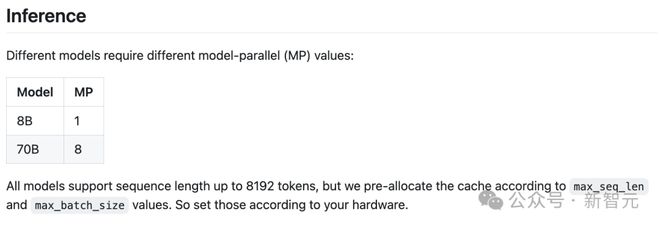
Llama 3 推理:https://github.com/meta-Llama/Llama3#inference
选一块 A800 的卡,计费方式已经默认选择了更省钱的潮汐计费。
在公共镜像中找到 Llama 3 的推理镜像,然后选择 1 张显卡,勾上「允许 SSH 连接」,「存储持久化」,「挂载公开数据」,最后点击右下角的创建。
速度还挺快,不到半分钟,机器就已经初始化好了。
复制 SSH 链接,在 terminal 进行连接。
诚不欺我,两个 Llama 3 的权重都已经在公开数据盘中,无需下载。
先试一个简单的推理。模型权重的初始化十分快捷,大约半分钟。
很快就推理完成了。
似乎写了一半被截断了,应该是 max_length 给太短,我们调整到 200,再来一次。
这次生成结果变长了不少,不过看起来 Llama 3 80 亿的模型能力还是一般,比如突然生成了「3. The United Kingdom」这个部分,前后文不是很严谨。
我们还注意到,在没有给 prompt 的情况下,模型两次都生成同样的开头。这引起了我们的好奇,于是我们决定从代码层面,看看到底是怎么一回事。
把 ColossalAI 的代码下载到了本地,看一下 ColossalAI/examples/inference/llama/llama_generation.py 这个文件:
ColossalAI 代码地址:https://github.com/hpcaitech/ColossalAI
原来是之前跑这个脚本用了默认的 prompt,现在,我们换成一个自定义的文本提示试试。
从结果来看,虽然可以成功继续生成,但是有点越扯越远了,除了前两句,后面并没有像我们期待的那样讲一个故事。
下面,让我们来体验一下 Meta-Llama-3-8B-Instruct 有对话能力的模型的效果。
首先,参考 Llama 3 官网中对话模型指令的格式。
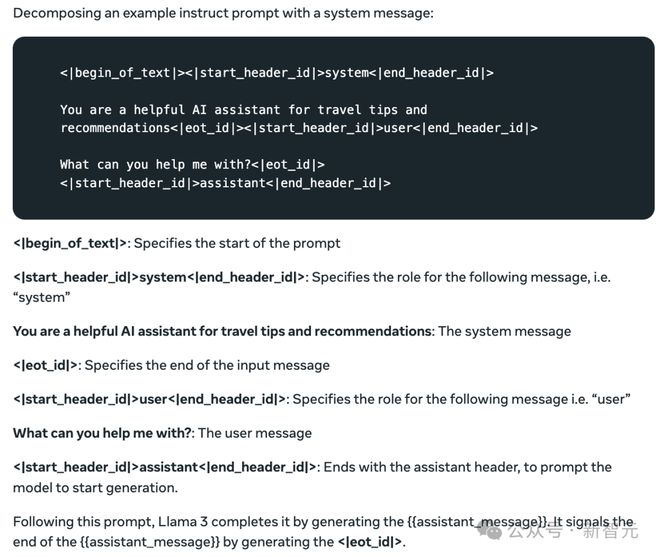
Llama 3 Model Cards:https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3/
先写一个简单的通过对话让模型写故事的指令。
因为在 bash 里面传这么多特殊符号的指令已经不太方便了,我们用了潞晨云的 jupyter 链接,在里面直接对 ColossalAI/examples/inference/llama_generation.py 进行了修改,让它可以读取一个指令的 txt 文件(如 dialog.txt),对每一行进行生成并保存到 txt 文件中(如 dialog_resp.txt)。
大概就是这样:
然后跑指令模型。
不久之后,文件生成。
非常好,这次模型终于真的在讲故事了!感觉指令模型会比基础的模型更好用一些。
完成推理后,赶紧关闭潞晨云机器,毕竟是计时收费的,省钱要紧。
Llama 3 700 亿参数的模型
在单卡上尝试过 80 亿参数模型的效果以后,我们再来试试更大的 700 亿参数模型。
毕竟,这可是一个和 Gemini Pro 1.5 打成平手的模型呢!
此时我们发现,其实 Llama-Factory 的代码既支持推理也支持微调,所以干脆直接拿这个镜像来试试好了。

Llama-Factory 项目地址:https://github.com/hiyouga/LLaMA-Factory
和之前一样的流程启动云主机,这次选择 Llama-Factory 镜像,卡数选 4 即可。
教程地址:https://cloud.luchentech.com/doc/docs/image/llama-factory/
启动时间还是一如既往的快。
我们按照潞晨云教程提示,把模型路径改到了本地。
然后直接开始和 700 亿的模型进行对话!
这次,我们还是让模型讲一个关于深海鲸鱼的故事。
可以看到,效果拔群!由于完全不用修改代码提示,可以直接输入对话内容,使用体验感直接拉满。
模型写了一个名叫 Aria 的蓝鲸的故事,讲她在一次海底探险中遇到了海底秘密守护者。守护者告诉她她的歌声有特殊的力量。最终她成功联合了海底生物并打败了因人类污染而出现的黑暗力量。
这个故事中出现了一个名字「Abyssaria」,于是我们继续针对这个名字进行提问。
很快,模型就进一步对于这个海底城市进行了描述。不愧是 700 亿参数的模型,效果真的不赖。
微调
针对微调,Llama-Factory 已经给出了资源使用的预估。
那接下来,我们就来尝试一下先用 Lora 微调 Llama 3 的小模型。
Llama 3 80 亿参数的模型
这次镜像依旧用 Llama-Factory。
根据上图中的资源预估,我们用 Lora 训练 80 亿参数的模型仅需一卡,而 700 亿参数的模型 4 卡 A800 即可。
打开 Jupyter 链接转到机器后,一样是把模型路径改到了本地,节省时间免下载。
可以看到这边默认用两个数据集,「identify」和「alpaca_en_demo」进行微调。我们很快就找到了这两个数据集的位置,放在/root/LLaMA-Factory/data 下。
这个格式是真的很简单了,想要用自己的数据来微调这个模型,只需要把训练数据整理成一样的格式,再上传到云机器即可。
以下分别是他们的数据例子:
# identity.json,[{"instruction": "hi","input": "","output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"},...]# alpaca_en_demo.json[{"instruction": "Describe a process of making crepes.","input": "","output": "Making crepes is an easy and delicious process! Here are step-by-step instructions on how to make them:\n\n1. Assemble your ingredients. For basic crepes, you'll need: 1 cup all-purpose flour, 2 eggs, 1/2 cup milk, 1/2 cup water, 1/4 teaspoon salt, and 2 tablespoons melted butter.\n\n2. Mix the batter: In a large mixing bowl, whisk together the flour and the eggs. Gradually add the milk and water, stirring constantly to ensure that there are no lumps. Add salt and melted butter, and mix well.\n\n3. Let the batter rest: If you can, let the batter sit for an hour or so. This will help the flour to absorb the liquid and make the crepes more tender.\n\n4. Heat your pan: Preheat a non-stick pan over medium heat. Lightly butter the pan or use cooking spray to prevent the crepes from sticking.\n\n5. Pour the batter: Using a ladle or a measuring cup, pour a small amount of batter (about 1/4 cup) onto the center of the pan. Immediately tilt the pan in a circular motion to spread the batter evenly and thinly over the bottom of the pan.\n\n6. Cook the crepe: Cook the crepe for 1-2 minutes until the bottom is lightly golden. Carefully loosen the edges with a spatula and flip the crepe over to cook the other side for another minute.\n\n7. Remove and repeat: Gently slide the crepe onto a plate, and then repeat the process with the remaining batter. Remember to re-butter the pan between each crepe if necessary.\n\n8. Fill and serve: Fill your cooked crepes with your desired filling, such as fresh fruit, whipped cream, Nutella, or ham and cheese. Roll or fold, and serve immediately. Enjoy!"},...]我们用以下指令启动训练单卡训练:
可以看到,训练过程中 loss 稳定下降,整个微调流程大概耗时 8 分钟左右。
模型也顺利保存到了指定的路径下。
整体来说,训练流程非常便捷!
如果大家有过微调模型的经历,那么一定知道微调过程中大概率遇到各式各样的问题,比如机器环境不匹配,出现 NaN 等,有的模型甚至还需要自己手动改代码才能跑起来。
而今天的训练却完全不用担心 Lora 要怎么设置,不用操心环境配置,训练途中完全没有遇到任何问题。
Llama 3 700 亿参数的模型
其实如果只是 Lora 微调 80 亿参数的模型,那完全没必要开多卡训练。
不过对于 700 亿的模型,我们直接开启 4 卡来尝试一下。
先用同样的方法,修改模型路径:
然后,开始训练!
在训练时,我们踩过一个坑:
一开始用了 examples/lora_multi_gpu/llama3_lora_sft.yaml 这个文件,然后发现这个文件只支持数据并行而没有对模型进行切割。 结果就是,每一台 GPU 上都需要保存整个模型,导致模型上传了 17/30 的时候就遭遇了内存溢出。
不过,切换到 examples/lora_multi_gpu/llama3_lora_sft_ds.yaml 后,4 卡就可顺利跑起 Lora 训练啦!
上传整个 700 亿参数的模型大约耗时两分半。
训练一千条数据的时间这次较久,26 分钟。不过这个也可以理解,毕竟模型权重放在了 4 个显卡上,也造成了一些通讯时间的消耗。
在尝试了潞晨云后,我们发现,微调似乎比想象中的更简单,只要自己按格式准备好数据,就能直接在平台上跑通这个模型,操作丝滑,基本不用 debug~
而且,其实还有更省钱的方法,甚至能不用自掏腰包,通过分享就可得到 100 元的机器使用代金券:
从此,再也不用担心没资源做实验了!
即使跑不起 700 亿的模型的多次实验,也完全可以先在 80 亿的模型上单卡多次实验,再把有希望的结果用 700 亿大模型一步到位!
相关资源链接:
Meta 的 Llama3 平台:https://llama.meta.com/llama3/
潞晨云平台:https://cloud.luchentech.com/
潞晨云 Llama3 用户手册:
https://cloud.luchentech.com/doc/docs/image/llama
https://cloud.luchentech.com/doc/docs/image/llama-factory
LLaMA-Factory: https://github.com/hiyouga/LLaMA-Factory






