西风发自凹非寺
量子位公众号 QbitAI
一张图 30 秒高质量转 3D,3D 生成圈的一个开源模型,最近成了新晋当红炸子鸡。
不仅上线即冲抱抱脸热榜,GitHub 也已揽星超 1.6k。

Gradio 官方也忍不住下场发推文分享,让大伙儿瞧瞧这个算不算是目前最好的图像转 3D 模型:

重点是该模型,背后的团队,还是一支来自清北的 00 后年轻初创团队。
CEO 毕业于北大计算机系,NOI WC 金牌、最佳女选手得主;CTO 来自清华姚班;不少成员还是 CG Artist,擅长利用 CG 进行艺术创作,COO 就是北大艺术史论与工商管理双学位;团队成立一年内就顺利完成了三轮融资……
量子位还打听到,基于该模型打造的产品还即将上线一波新功能:一张图生成 3D 全景图,一键将视频人物替换为生成角色。
这次走红,或许只是这支明星团队的开始。
一张图 30 秒转 3D
细心的家人们可能已经发现了,开头提到的这个爆火的开源模型名为Unique3D,主打高保真度、高一致性、高效率单图转 3D。
比起以往基于 Score Distillation Sampling(SDS)等方法,Unique3D 解决了模型生成需要长时间优化,几何质量差,存在不一致性的问题。
而且 Unique3D 也优化了基于多视图扩散模型方法受限于局部不一致性和生成分辨率,难以产生精细的纹理和复杂的几何细节的问题。

Unique3D 一上线,团队就开源了使用大型开源 3D 数据集 Objaverse 训练出的模型版本,还放出了 Demo 给大伙儿玩。
网友玩过后,一致认为 Unique3D 的诸多表现都很不错。

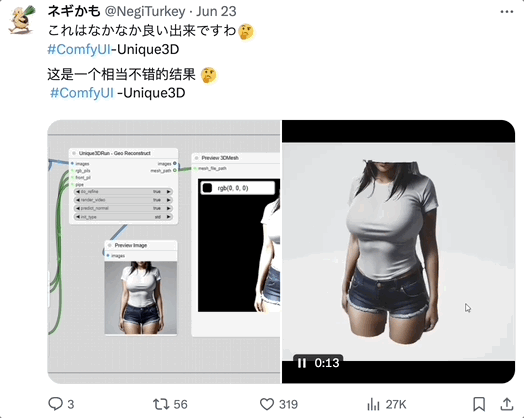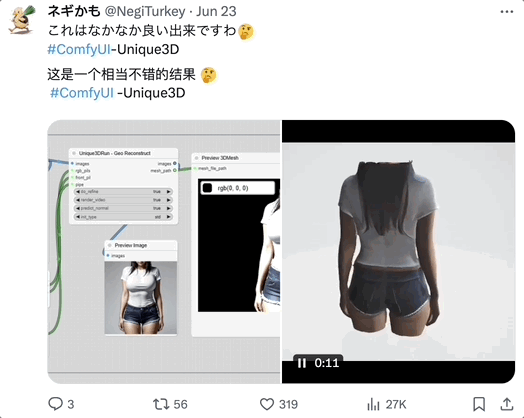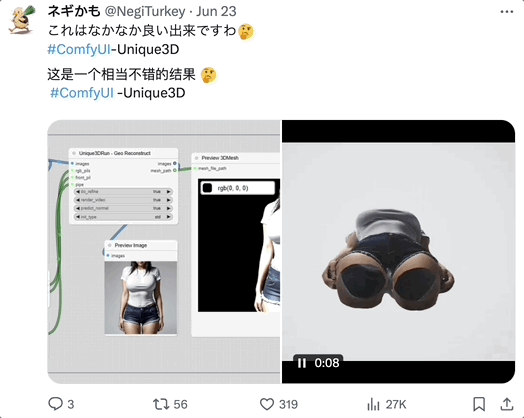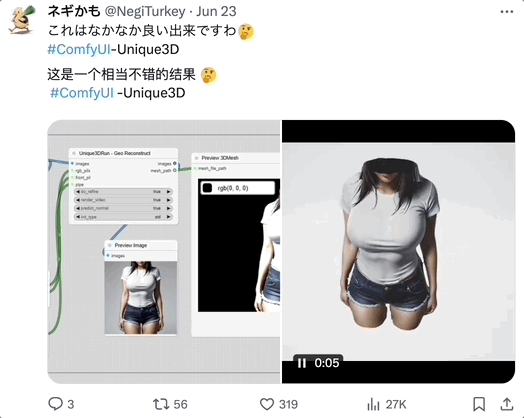
胳膊、腿、手腕都做的很好:
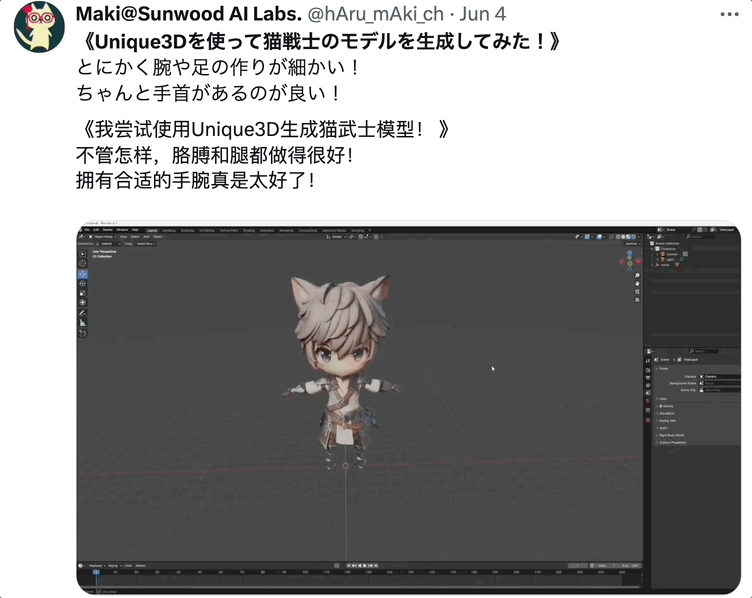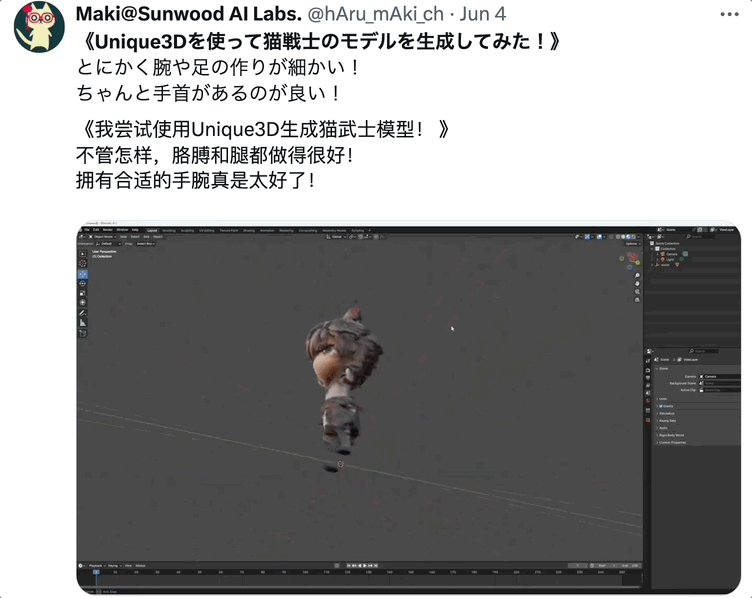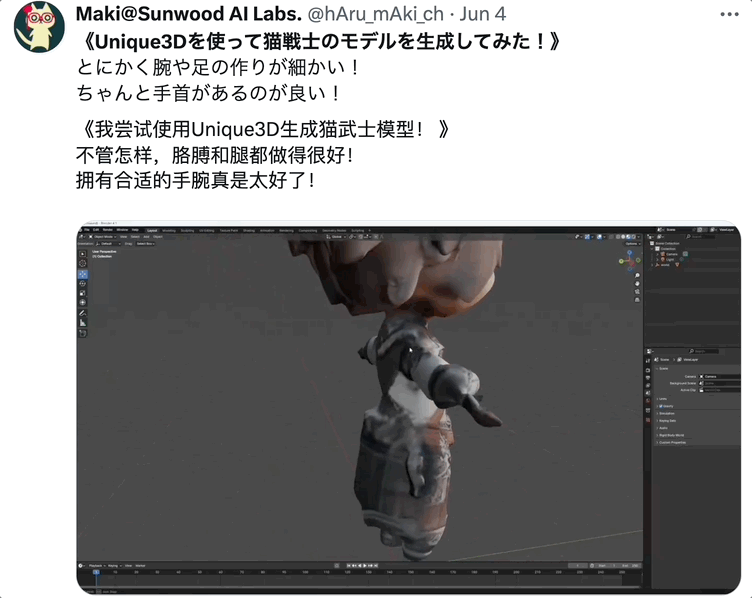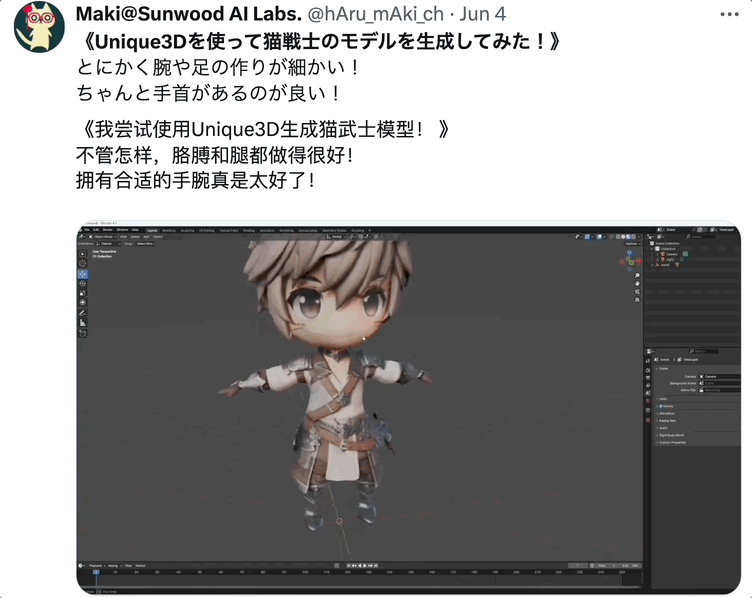
这位网友还为生成好的 3D 模型搭入骨架,解锁高阶玩法:

搭配其他工具,在 Blender 中组建 3D 动画也可以:
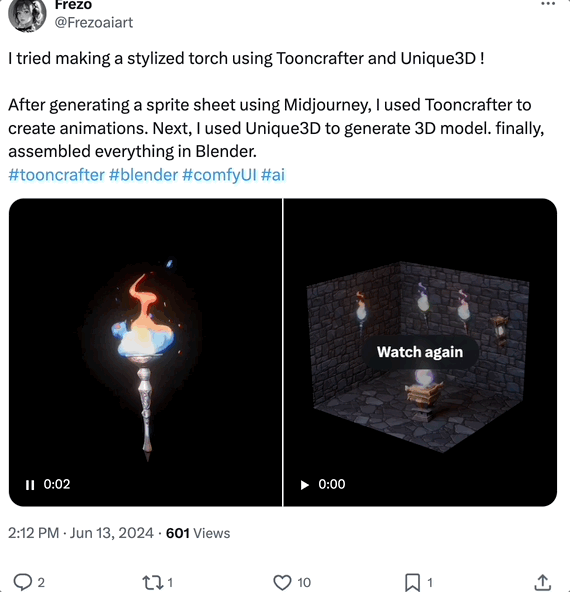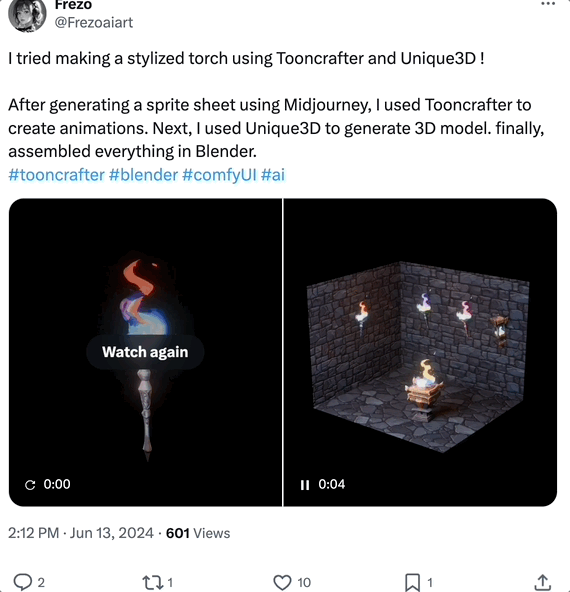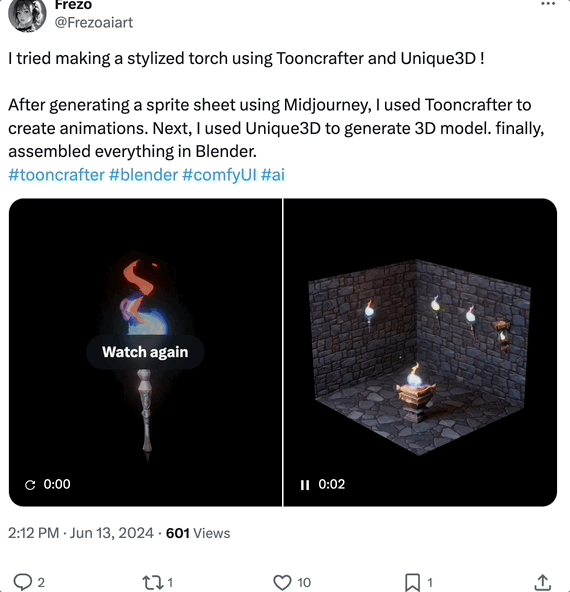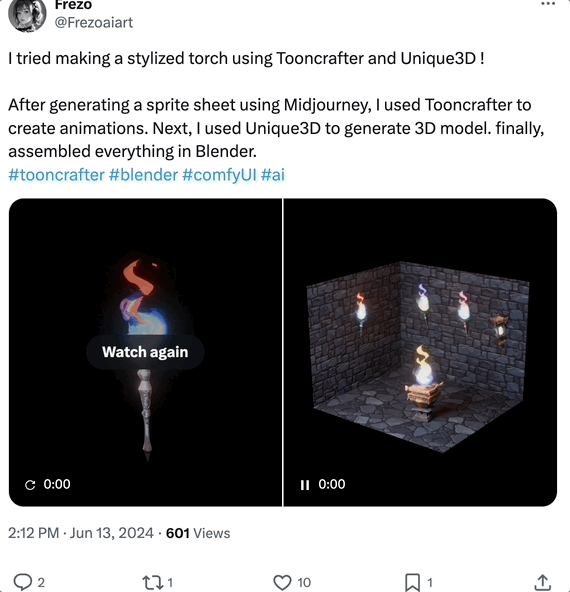
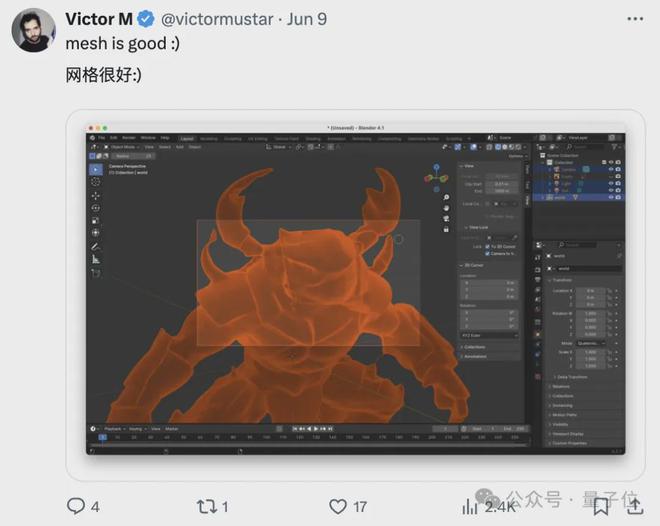
有网友表示,生成的 Mesh 视图质量很高:

看到这,量子位也忍不住上手体验了一番。
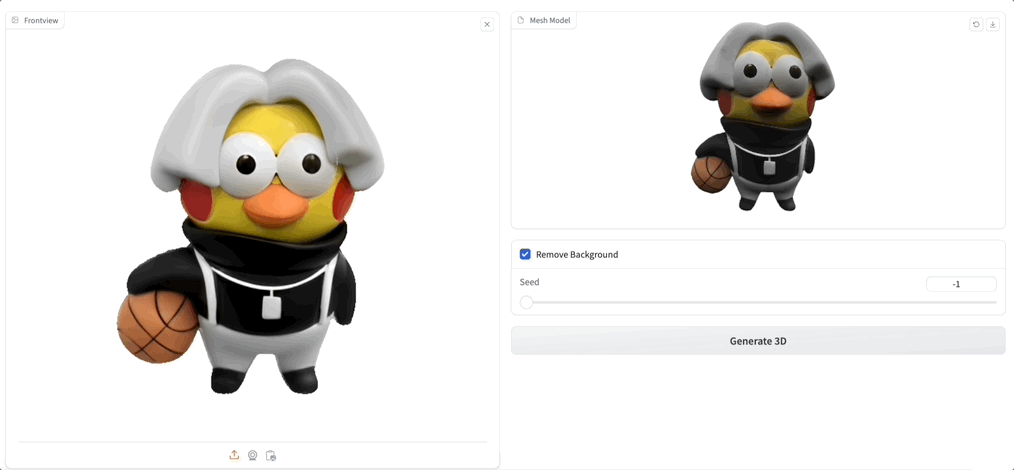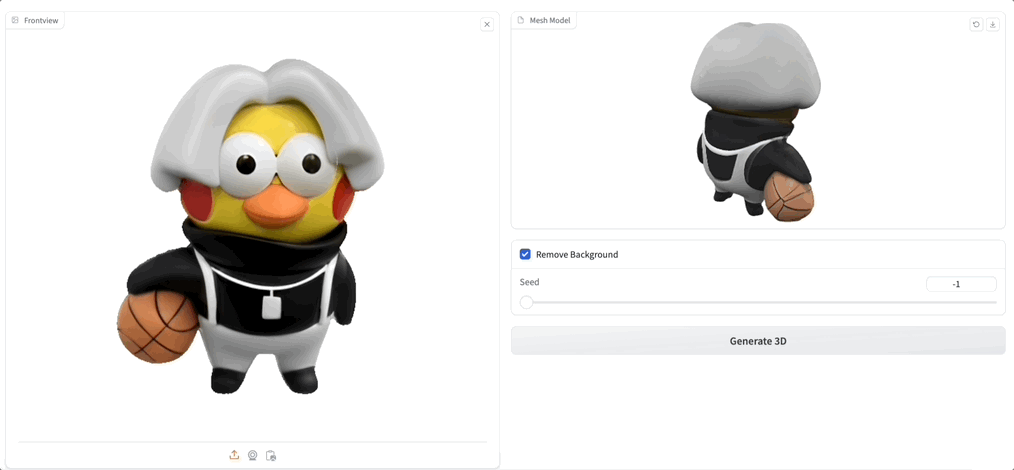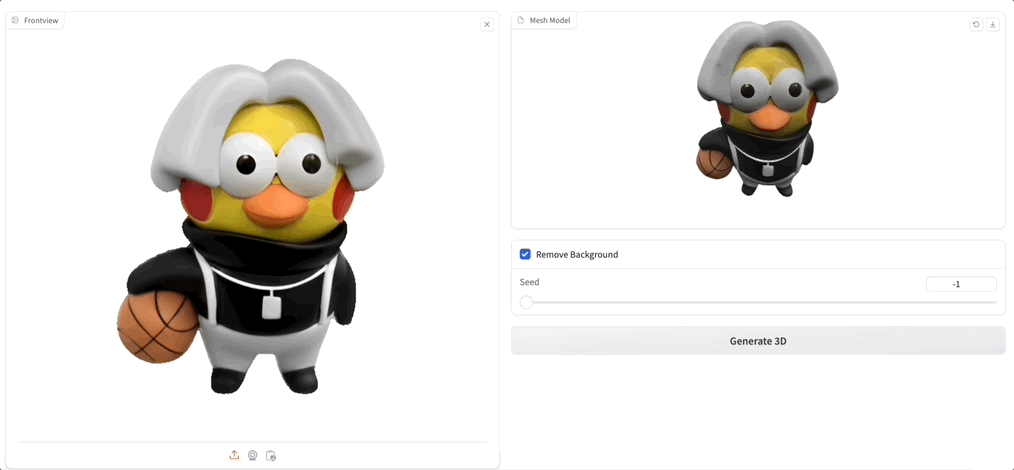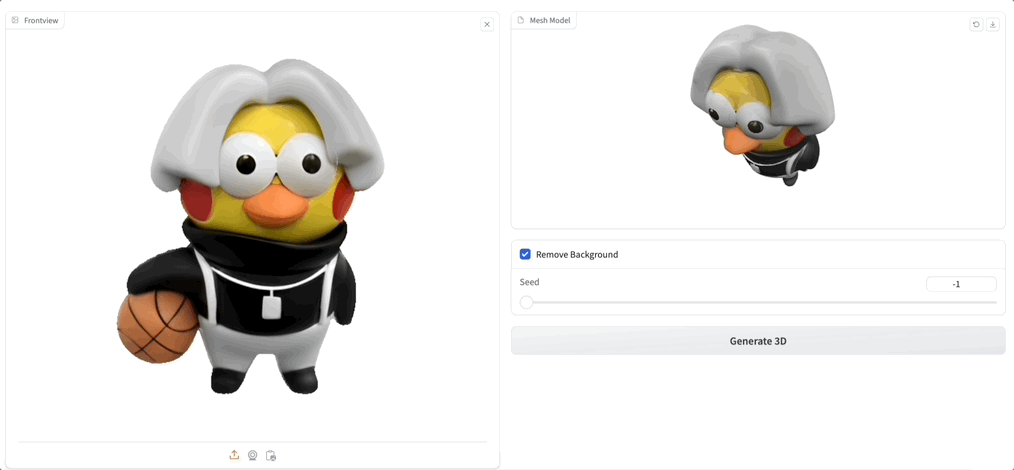
Demo 界面很简洁,只需要上传一张图片,然后点击 Generate 3D 就可以了,也可以简单调整参数 Seed,勾选去除背景:

紧接着,生成速度非常快,相比此前模型需要几分钟的生成时间,Unique3D 几十秒就能将一张图“啪”的一下转 3D:
随手用 GPT-4 生成一张小怪兽的图,然后上传:
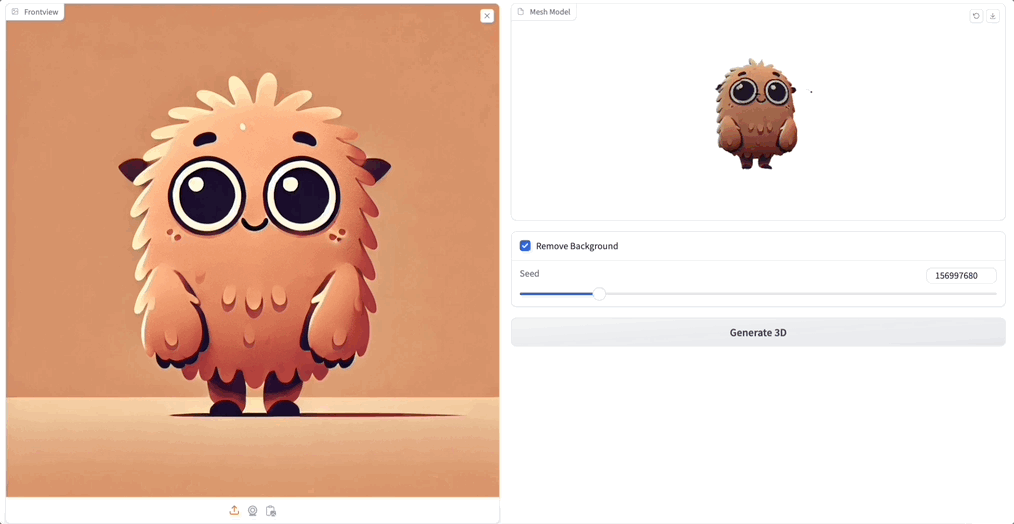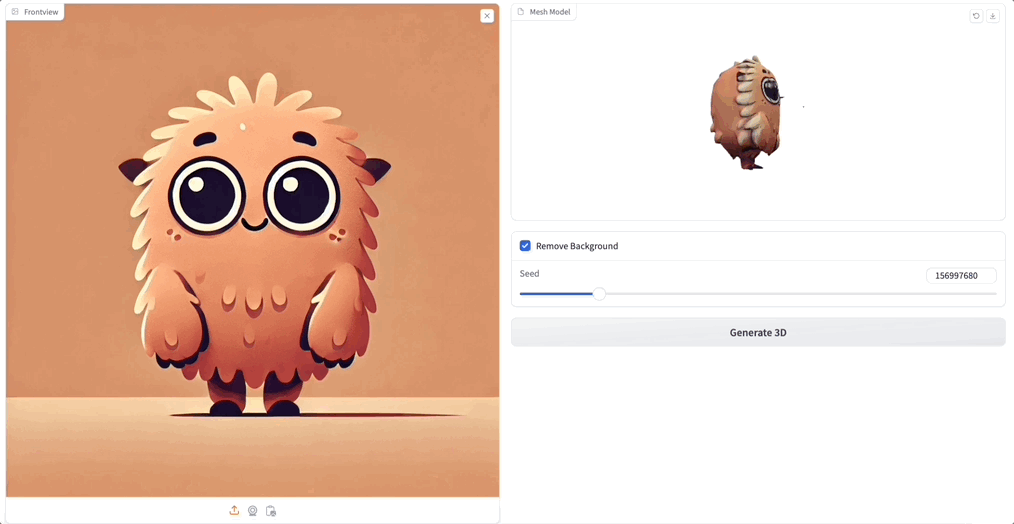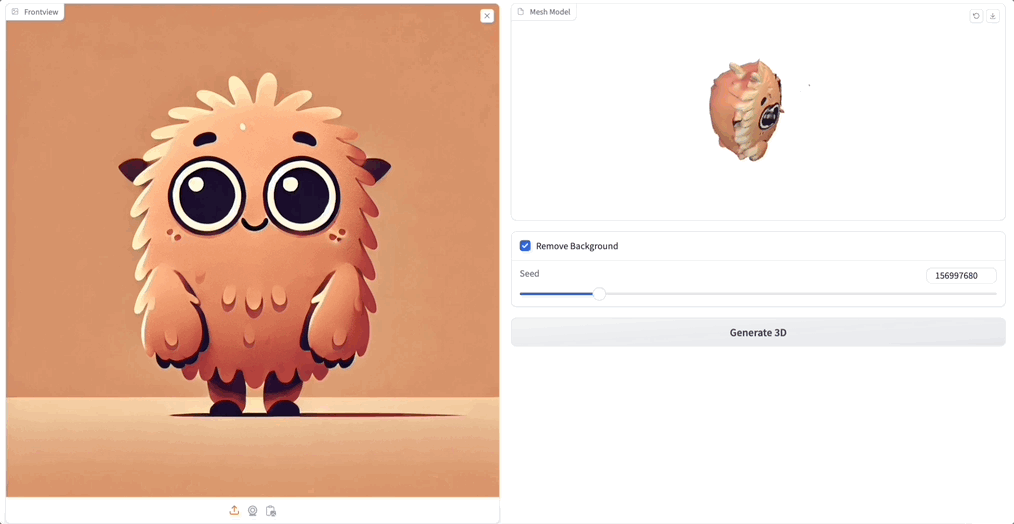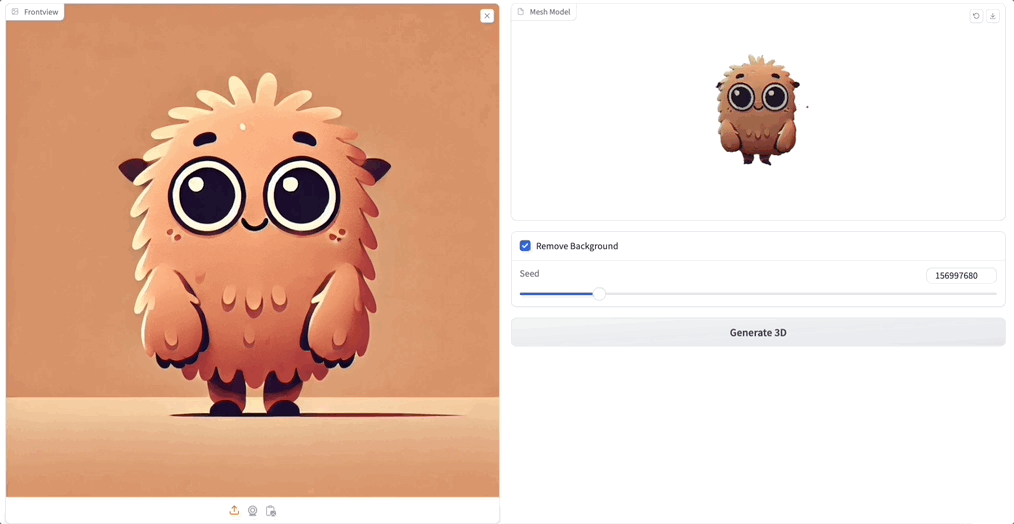
你别说,感觉 3D 生成后的可爱度直线上升,关键 Unique3D 生成的纹理和质感都和原图高度一致。
而这一特点也是最为网友所称赞的。
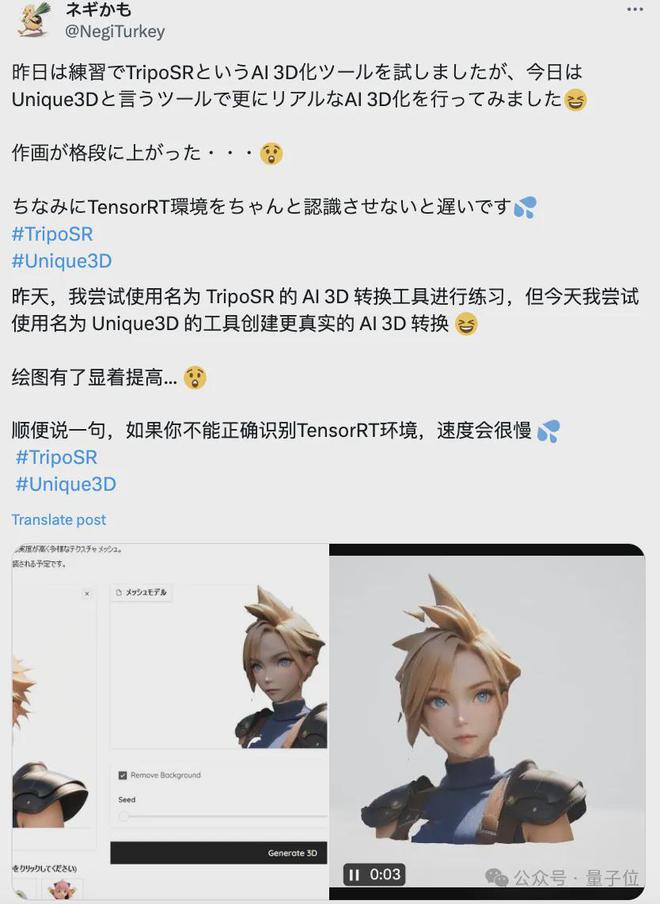
不少网友指出,Unique3D 生成的质感很真实,甚至比 Stability AI 和 Tripo AI 合作推出的单图转 3D 模型 TripoSR 还要好。
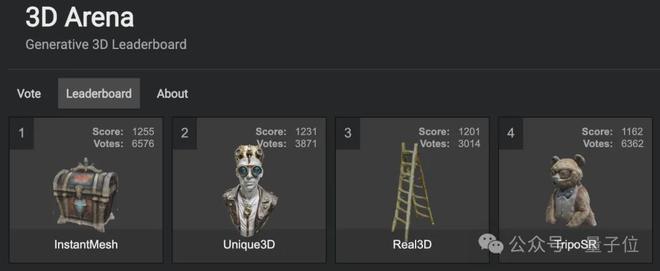
在抱抱脸的 3D 竞技场中,Unique3D目前排名第二,和第一名的 InstantMesh 差距也很小,票差 24:
不过,Unique3D 的生成也会有一些瑕疵,比如有时背面分辨率不高,会有一些小斑点等。

生成企鹅效果很好,生成梯子结构就乱了:
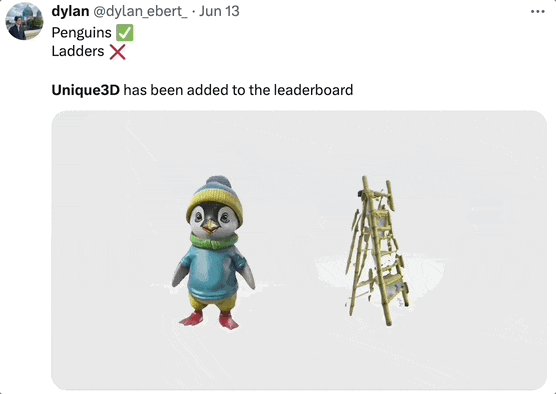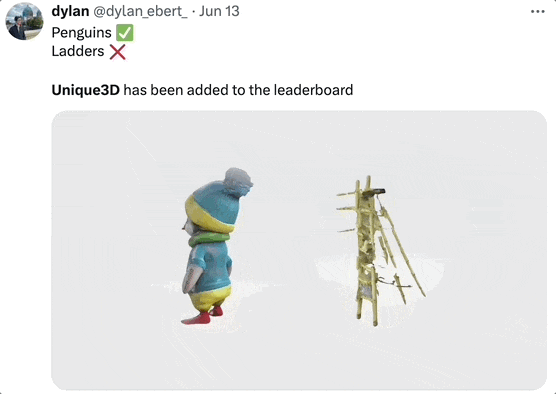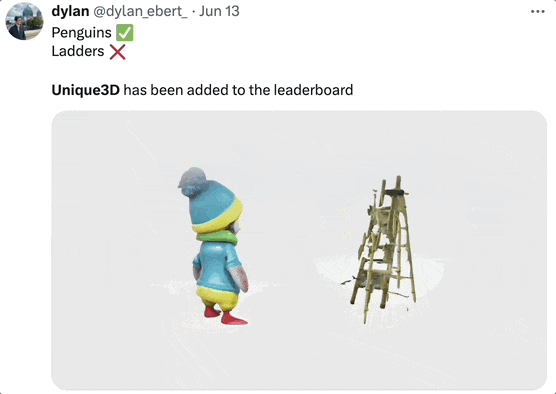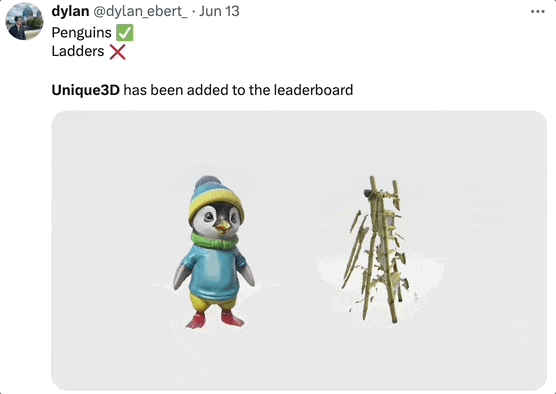
对此开发团队表示会继续优化算法,并且有个小 Tip:上传的图最好是标准的正面图、无遮挡的那种。
此外,团队还表示最近将加入更多视角的参考,提升对不同视角的兼容度,由于一直在优化算法,模型稳定性可能会受干扰。
说回来,Unique3D 是如何将一张图高质量转成 3D 模型的?
Unique3D 里面有什么?
用一张图展现 Unique3D 的 Pipeline 是这样婶儿的:
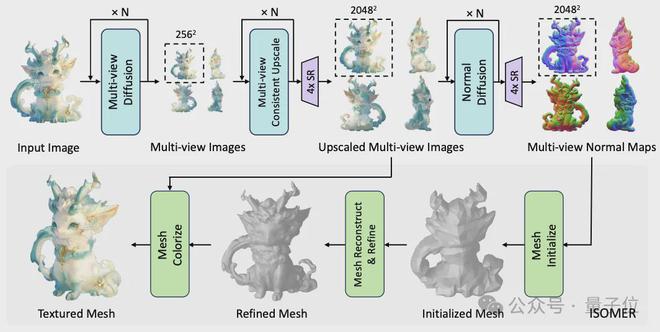
整个流程分三个主要阶段:多视图生成、高分辨率上采样、3D Mesh 重建。
具体来说,输入一张图,首先微调版 Stable Diffusion 模型会根据这张图生成四个 256×256 分辨率的正交多视图图像,也就是从单一视角推断出物体的其它视角。
然后,通过一个高分辨率上采样过程,使用 ControlNet-Tile 将图像分辨率提升至 512×512,再用 Real-ESRGAN进一步提升至 2048×2048,同时利用专门的法线扩散模型生成对应的高分辨率法线图。
利用多级上采样策略,逐步提高图像分辨率,可以较好地保证生成细节。
接着,团队提出了ISOMER 算法,直接基于 Mesh 进行 3D 重建,计算负载与空间分辨率的平方成正比。
其中包括以下步骤:
- 利用前后视图直接快速估计初始 Mesh;
- 通过 300 次迭代的 SGD 优化进行粗到细的 Mesh 优化,引入扩张正则化,避免表面坍塌问题;
- 利用 ExplicitTarget 技术为每个顶点分配唯一的优化目标,处理多视图不一致性;
- 基于多视图图像对精确的几何结构进行着色,使用高效的平滑着色算法完成不可见区域的着色。
由此,从性能上讲,输入一张图在 RTX4090 GPU 上仅需 30 秒即可完成 3D 转换,生成的 3D Mesh 模型在几何精度和纹理细节上都显著优于基准。
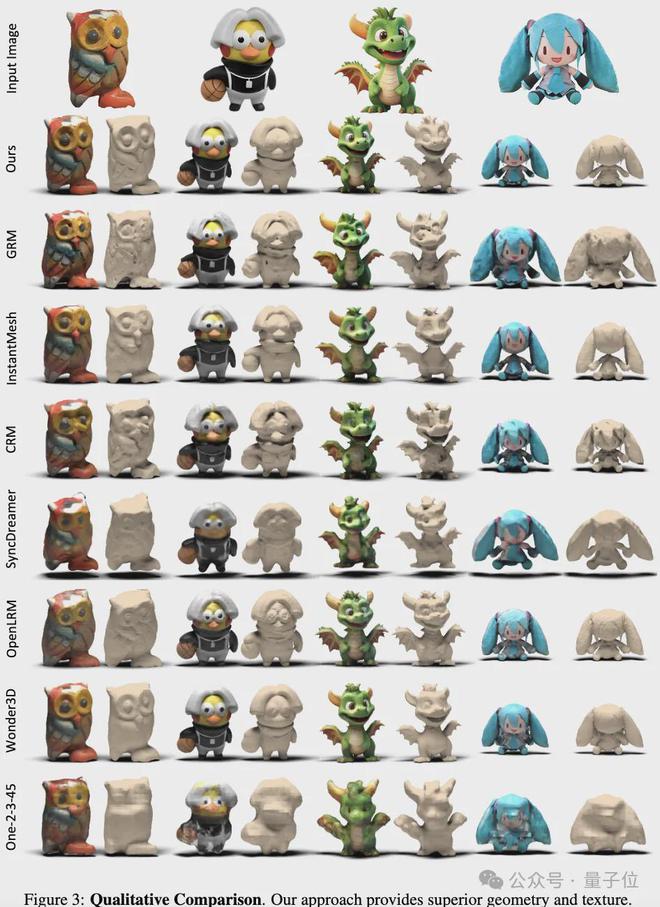
以下是定性比较以及细节对比:

所以,Unique3D 背后的这个年轻的学霸团队又是哪个?
“年轻人就要玩新模态”
Unique3D 背后团队是AVAR AI。
有些人对其可能并不陌生,毕竟自 2021 年成立以来,AVAR AI 就在 3D 这条赛道上多次崭露头角,成立一年后成功融资三轮。
创始人兼 CEO 胡雅婷,毕业于北大计算机系,曾在谷歌、阿里、字节做过算法工程师。
技术合伙人兼 CTO 吴凯路,来自清华姚班,在叉院做 3D 生成和 NeRF 相关研究,曾提出了 FSD(text-to-3d 流分数蒸馏)和 MemSR(高效训练超分辨率模型)等工作。
在此之前,胡雅婷和吴凯路分别拿过 NOI 全国信息学奥林匹克竞赛 WC 金牌、金牌,吴凯路是国家集训队,胡雅婷是最佳女选手。
COO 任靳珊,本科毕业于北大,获艺术史论与工商管理双学位,硕士毕业于芝加哥大学,曾在海内外美术馆、腾讯艺术等有过策展商务文创经历。
总之,一句话形容 AVAR AI 团队:全员平均 00 后学霸。

CEO 胡雅婷还透露,团队目前严格意义上的全职员工很少,有一半是深度合作的 AI 研究员,还有一半是 3D 艺术家。
其本人在参加信息学算法竞赛前也非常喜欢艺术创作,算法在她看来也是一个非常有创造性的过程:
之所以想创业做图形学,也是因为很喜欢皮克斯,皮克斯就是一个典型的技术+艺术团队。
基于此,AVAR AI 的定位也更专注于创作方向。
胡雅婷直言并不想卖 3D 生成的技术,所以选择直接开源 Unique3D:
我们比较关注 3D 应用场景以及它的下一步,希望可以通过比如做动画以及新的交互方式实现 4D,这样就可以让创作者创作出真正有表达力的 IP 或是数字媒体内容。
所以这个过程中可能竞争力并不是技术本身,我们接下来也会重点关注作品的艺术性和 IP 的潜力,以及做好创作者社群。
在她看来,形成这种“创作者经济”会是 AVAR AI 区别于 API 工具等模式的壁垒,像是 Midjourney 就形成了一套创作者生态和网络效应。

而 AVAR AI 此前在 AI 生成 3D 内容方面的工作,也为团队新的 3D 生成项目打下了基础。
在 Unique3D 之前,AVAR AI 的一条业务主线是专注于元宇宙数字品牌,与动画影视公司、知名 IP、互联网大厂等都有过合作,例如曾和阿里合作推出 3D 星球生成器、与奥飞娱乐合作打造 IP 形象。
面向年轻用户,AVAR AI 推出的应用也更加多元,AR、VR、XR 方面也有涉猎。
对于新研发的 Unique3D 模型,团队除开源了用开源数据集训练的模型外,还用更高质量的商用私有数据对模型进行了工程优化并上线到产品网页端——Aiuni AI。
上面提到的更多更具表达力的 3D 应用场景,也在部署中,打开 Aiuni AI 主页就能看到即将上线的新功能。
例如 3D world,一句话、一张图就能生成一个 360 度全景,而且不只是一张全景图,用户可以导出 Mesh,也就是整个场景的 3D 文件。

此外,还有一个叫做 DreamCamera 功能也将会逐步推出,基于团队的另一项研究 Camera Dreamer 打造,可以一键将视频人物替换为生成角色,同时 Aiuni AI 还兼容 VisionPro 等 MR 的渲染环境:

在被量子位问到作为一名年轻的科技创业者,有何见解可以分享给其他有志于进入科技和创业领域的年轻人,Aiuni AI CEO 胡雅婷给出了这样的回答:
我觉得年轻人就一定要做新模态。比如 AIGC 创业,文本、图像、视频,大厂都已经入局了,造了很多通用大模型。而年轻人就得去找一些新的模态,要有新的数据和算法,并且有增量的或是下一代的应用场景。
你觉得 Unique3D、Aiuni AI 的表现如何?感兴趣的家人们可以玩起来了~
Github 链接:https://github.com/AiuniAI/Unique3D
Huggingface Demo:https://huggingface.co/spaces/Wuvin/Unique3D
项目主页:https://wukailu.github.io/Unique3D/
论文链接:https://arxiv.org/pdf/2405.20343
参考链接:
[1]https://x.com/NegiTurkey/status/1804750164680483003
[2]https://x.com/fffiloni/status/1799400868074459574
[3]https://x.com/dylan_ebert_/status/1800959099774943470






