
文硅谷 101
苹果在 AI 上,终于出招了。在硅谷如火如荼的 AI 大战中,苹果的战书是科技巨头中最晚的,而外界一直在等苹果公司的这步棋。
在美国时间 6 月 10 日的 2024 年 WWDC 上,苹果正式宣布入局,围绕 AI 功能宣布 Apple Intelligence 套件,包括一系列针对用户的 iPhone、iPad 和苹果电脑的 AI 应用,并宣布与 OpenAI 的合作。
有意思的是,我们看到外界对苹果这次 AI 策略发布的极大反差。一面有人嘲笑苹果的 AI 功能太简单太落后,早就是安卓手机上玩剩下的,苹果股价在 WWDC 当天也收跌近2%。然而,就是下一个交易日,WWDC 的第二天,苹果股价强势反弹超过 7.2%,创 2022 年 11 月 10 日以来最大涨幅,刷新 2023 年 12 月 14 日所创的收盘历史新高。
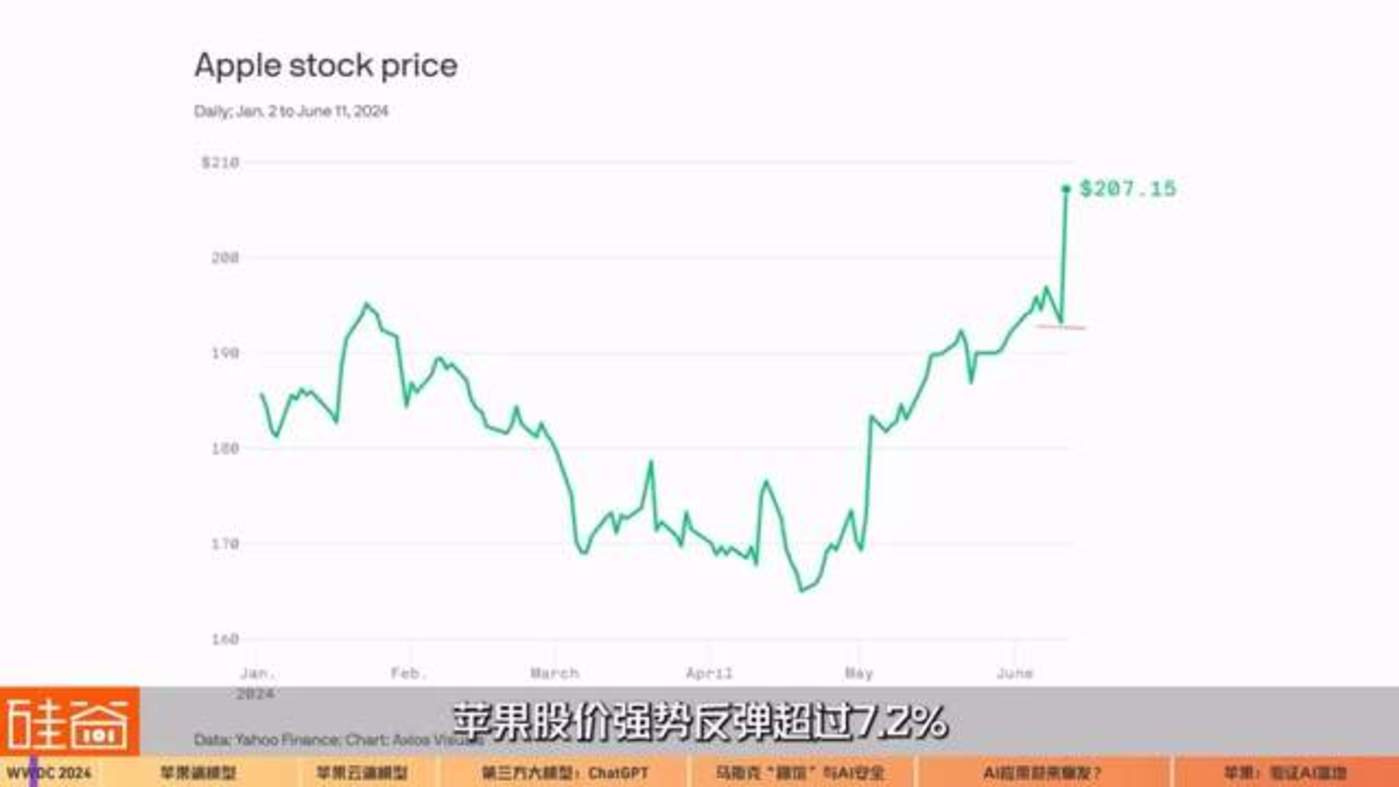
一天之间,市场情绪反转,华尔街意识到了什么?同时,马斯克在推特上对苹果和 OpenAI 的合作公开挑衅,直指安全隐患,苹果的 AI 真的安全吗?苹果手机的端模型能在开发者中间迸发出新一轮的 AI 应用大爆发吗?
带着这些问题,我们密集访问了 AI 模型研究员、应用开发者、一二级投资人等等,想透过 WWDC 各种应用 demo 更深入地去探索一些底层的技术和商业问题,因此也收集了专业领域和资本市场对这次苹果 AI 发布的反馈,希望给大家呈现一个比较全面的观点展示。包括:
1.手机端模型的未来,云上模型以及苹果自研大模型
2.苹果声称的 AI 安全是如何实现的,与 OpenAI 合作的安全隐患在哪里
3.AI 应用是否会进入爆发期
4.苹果对未来硬件和 AI 交互的布局,包括手表和耳机 Airpods
5.二级市场对苹果股价的看法
01 苹果 AI 三件套:向前一步,步步谨慎
首先我们从模型的技术面看看苹果目前的 AI 策略。在 WWDC 的 keynote 之后,苹果机器学习官网公布了 Apple Intelligence 的详细信息,Apple Intelligence 总体来说分成三个部分来实现:自研端侧模型、自研云端模型,再加上 OpenAI 的 GPT 大模型这三套系统。

1. 1 端模型:30 亿参数本地运行针对性任务
第一是本地模型,也被称为端模型:设备上约 30 亿参数的语言模型,测试得分高于诸多 70 亿参数的开源模型(Mistral-7B 或 Gemma-7B);这就是说,虽然苹果的端模型参数小,但表现比是参数量两倍多的其它模型还要好。
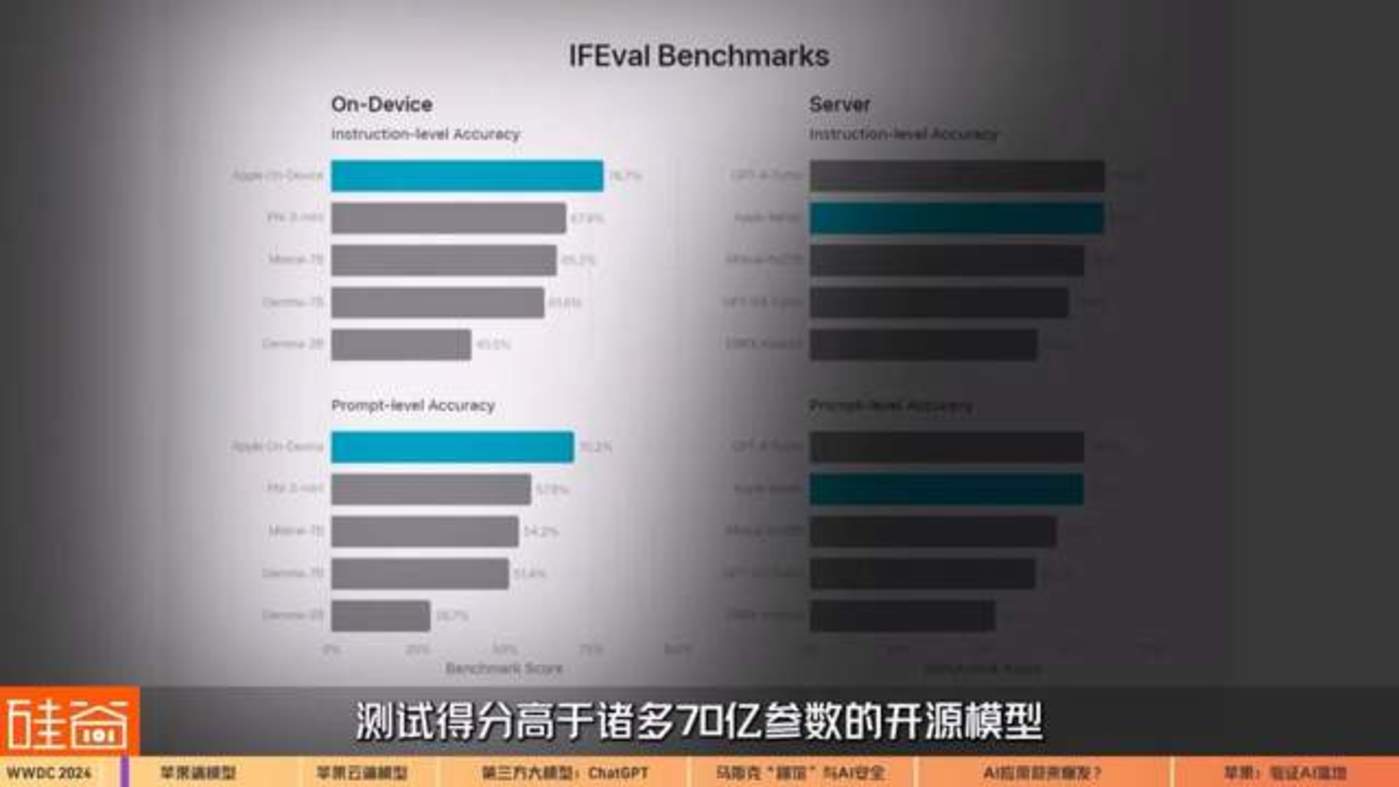
苹果的端模型论文,我们在之前的视频中有提过,除了论文之外,根据官网这次的介绍,苹果在模型框架上用到了“grouped-query-attention”(分组查询注意力)和 LoRA 框架,可以压缩推理过程,有效降低内存占用。这样需要在本地运行的端模型在硬件上的要求,需要 iPhone 15 Pro 和 iPhone 15 Pro Max,以及配置 M1 芯片以上的平板和苹果电脑。
其实芯片算力是一方面,毕竟苹果 A16 芯片的 NPU 算力已经高于 M1 了,真正让 iPhone 15 Pro 以下机型无法使用 AI 功能的原因,则是在于运行内存不足 8GB,进而影响 AI 模型的推理能力。
作为对比,谷歌去年部署过端模型的手机 Pixel 8 Pro,参数只有 18 亿,但运行内存是 12GB,在今年谷歌做出优化后,才能让 18 亿参数的模型跑在运行内存 8GB 的手机上。这样来看,苹果能让 8GB 的手机跑 30 亿的模型,这也是很大的端模型技术领先。
端模型的好处是在设备端就能运行,这让用户数据就在留在手机等设备上,数据隐私问题是最安全的;但坏处是,端模型因为参数较小,在能力和通用性上与千亿万亿参数的大模型 LLM 是无法相比的,所以只能做一些针对性的任务。
陈羽北教授
加州大学助理教授、图灵奖得主杨立昆博士后
我们想要把这样的如此 general (泛化)的东西做到端上的时候,那要面临一个选择,就是说这个端它毕竟是有尺寸限制的,在这样的一个尺寸限制下,有一个基本的问题:到底能够 build in(内置)多少的 generalization(泛化),如果我只是给你一张纸的话,那你最好就是说 focus (专注)在这一个问题上,把这一件事情做好就不错了。
做好一件事情,恰恰是端模型的能力在一些应用上可以实现的。比如说这次 WWDC demo 里面展示的众多 AI 功能中,各种文字和邮件的 AI 优化,电话录音转文字、总结、自动识别短信和邮件等语言功能,还有 AI 生成图片,AI 表情包 genmoji 以及照片 AI 编辑等功能,以及让众多用户久等了的更聪明的 Siri 助手,它可以理解更复杂的语言文本,进行更自然的交互,并且会结合设备端的数据来达到更用户定制化的需求,比如说从相册、邮件、短信、备忘录等文件中提取特定信息来回答问题,比如说你忘了你的身份证号,某个朋友的生日,你的车牌号等等,感觉会让整个 Siri 的交互体验往前迈进一大步。
Nathan Wang
前苹果员工、iOS App 开发者
对于 Apple 来说的话,它最好的一点就是,它的 problem(问题) 是一个固定的问题,或者说一个非常 specific problem(特定的问题),我只要在每一个 specific(特定)的任务,专精这个工作,去部署一个能够完成这个工作的模型,就可以完成这个事情。也并不需要用一个非常大的模型,来支持所有的这个生态,所以刚刚讲的那一点,我会认为 Apple 其实在它设备上,应该部署了这样的一些小模型。
但同时,AI 专家们会告诉我们,端模型的 AI 能力是不够的。所以苹果的解决方案是,在云端再配置更大一些的模型,来解决端模型解决不了的问题。
1. 2 云端模型:更大云端语言模型补足能力
当手机端一些复杂场景出现、端上小模型能力不足的时候,苹果自研的第二个基于云端的基础模型能够补足端模型的短板。
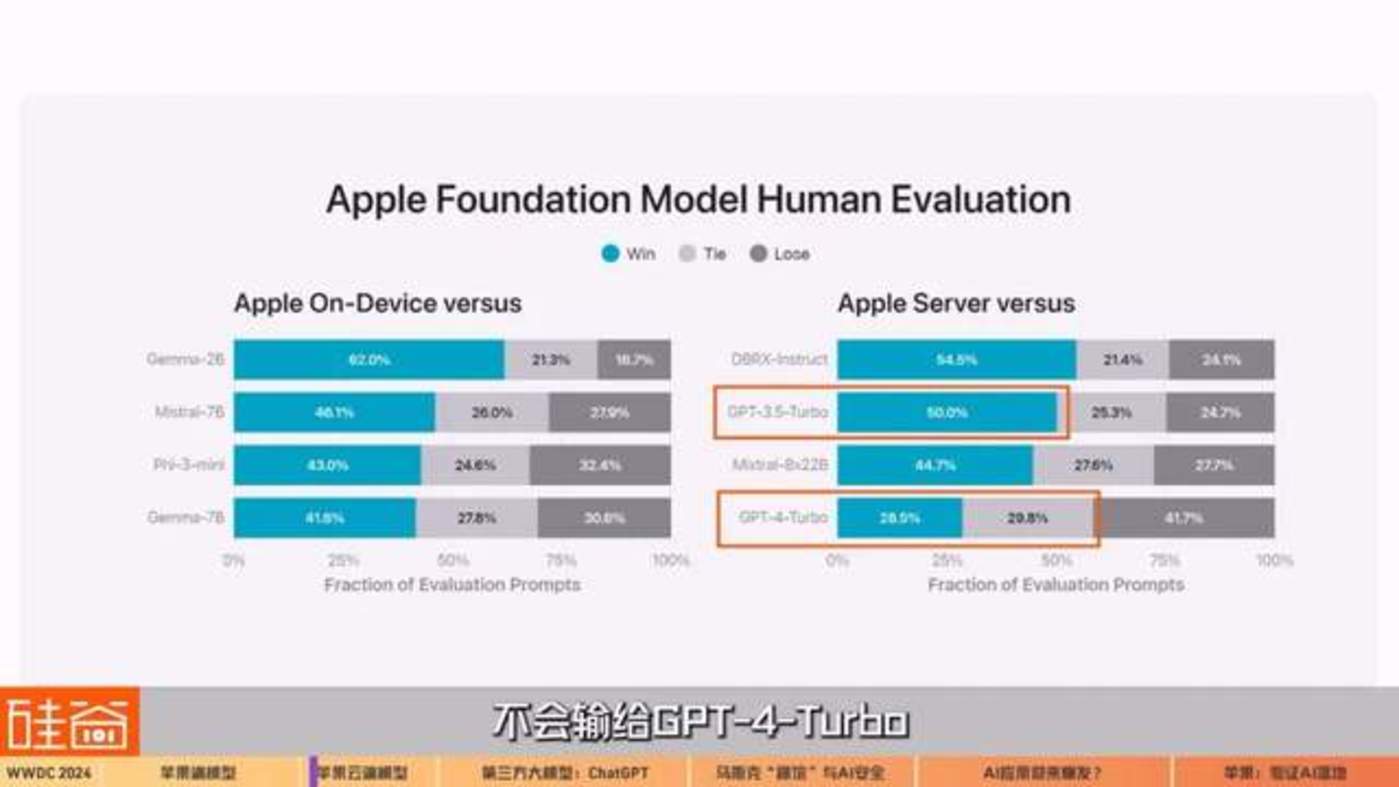
苹果官方公布的技术文章显示,苹果计划通过私有云计算在 Apple 芯片服务器上运行的更大云端语言模型。而苹果表示,通过的云端模型和一些更大参数模型相比,50% 的几率能跑赢 GPT-3.5-Turbo,超过 58.3% 的几率不会输给 GPT-4-Turbo。以这个参数差异的标准来看,苹果的云端模型能力不会太差。
Nathan Wang
前苹果员工、iOS App 开发者
Craig Federighi(苹果高管)展示了一个用户使用案例,就是说他正在开会,可能要 delay(延迟)了,那我要接我女儿,我能不能赶得上。要解决这个问题就相当于说,背后的大模型,需要去调用各式各样的数据和 API,来解决这个问题。
它首先要了解这个会议的时间是什么样的,你会迟多久,然后可能去看你苹果日历的数据,把你会议的时间和地点都给拿到。当拿到两个地址的时候,他就可以去 call(调用)一个 Apple map(苹果地图)的这样的一个 API(应用接口),然后去计算,两个点之间的距离究竟是多少,也会结合交通的数据,把这些数据全部汇总之后,作为提示词送给大模型,大模型拿到这些信息的时候,就可以很好地帮他去思考说,我会不会迟到或要迟到多久,甚至有可能在 APP 端的时候,他可以帮他规划最优的这样的一个路线。
所以说你可以理解做 agent(智能助理),就相当于说大模型加上不同的 API(应用接口)和 function(功能)的 call(调用),给到大模型具体的这些数据,让大模型去做决策。像这样一个复杂的系统的时候,可能在端上的这种小模型就不一定能够做得好。因为大模型需要去知道,在什么情况下要 call(调用)什么的 tool(工具),这个其实是考验大模型逻辑能力,也就 reasoning(推理)的这个 capability(能力)。
苹果目前还没有公布云端模型的具体参数,但前苹果员工、也是非常有经验用 AI 大模型尝试各类 iOS App 的开发者 Nathan Wang 就对我们猜测说,苹果的云端模型不需要很大参数,可能 300-700 亿个参数的模型,就能实现苹果目前想做到的应用功能。
Nathan Wang
前苹果员工、iOS App 开发者
苹果的整个问题,它是非常具体的,比如说这样一系列的部署,或者不同 API(应用接口)的 call(调用)。那它的整个环境其实是被固定住了,完全可以用这些环境产生出的数据,去串一个中小型的模型,完成大模型可以完成的那种复杂程度,我觉得这也是能够达到的。
所以我认为它在云端部署的可能是一个中小型模型,比如说数百亿参数,300-700 亿参数左右这样的,这个模型是被专门训练过去,完成 Apple 生态中一系列操作的模型,那它最终就可以去完成一个很好的用户体验,我觉得这一点的话,应该是 Apple 把整个生态整合在一起所能够达到的一个能力。
而如果云端模型还无法达到的能力,需要更大的模型来结局呢?苹果的做法是,暂时不拿出自家大模型,而是选择与 OpenAI 合作接入 GPT 大模型。
1. 3 OpenAI 合作模式:大模型仍不成熟下的折衷选择
在苹果发布 AI 三件套之前,外界最大的一个疑问在于:目前 AI 大模型的鲁棒性如此不稳定的情况下,对用户体验追求完美的苹果会如何选择。这里鲁棒性 robustness 指的是模型对数据变化的容忍度,能否稳定运行。从事模型研究的陈羽北教授认为,就算是如今市面上最好的 AI 大模型,鲁棒性仍然是很大的挑战,尤其是运用在将会卖出百万部千万部的手机上。
陈羽北教授
加州大学助理教授、图灵奖得主杨立昆博士后
端上的话,很多任务做到 Robust(鲁棒性)的话,是可以清晰 defline(定义)的。然后我觉得有一类问题可能会相对棘手一点,如果我做一个完全 open-ended(开放式)的一个智能助理,非常容易去 show demo(演示 PPT),但不容易做落地。因为要做落地的话,你会发现最核心的问题其实还是 Robustness(鲁棒性),就是当你的 model(模型)以这种以 volume shipping(大规模出货)的时候,百万部出货的时候,这时模型质量就会变得非常的重要。
我们有理由猜测,苹果这个如今全球市值最大的科技公司,有足够的资金、算力、人才去训练足够大的 LLM 大语言模型,就算技术方面落后于 OpenAI,也不应该差得太多。然而,别忘了,苹果也是一个十足的完美主义者,无法忍受推出来的应用或产品被消费者们诟病,因此,苹果在大语言模型上的策略是保守的,也这是为什么苹果目前选择了与 OpenAI 合作,将 GPT 模型整合进了 Apple Intellegence。
在处理文字和使用 Siri 的过程中,如果用户想要调用性能更强的云端模型,可以切换使用 GPT-4o 来生成信息。这今年的 WWDC 中,OpenAI 的 CEO Sam Altman 也去到了现场,虽然没有上台,但依然在苹果开发者们中间引起不小轰动,而苹果的 keynote 中间也短暂展示了用苹果手机弹出 ChatGPT 的窗口进行更复杂的多模态交互。
但是自始至终,苹果强调的是,your permission(你的许可),你作为用户,批准你的数据被送去 ChatGPT。这也是苹果 CEO Tim Cook 在 WWDC keynote 之后接受 Youtube 博主 Marques Brownlee 访问时强调的重点。
Tim Cook
我们认为我们已经做好了这点,即使信息在云上处理,也同样能像在本地处理一样安全、可靠和私密。我们在这方面做了很多工作,投入大量精力来确保这点,如果你想处理的一些问题超出了现有的能力,那你可能会希望去使用市场上的大语言模型,所以我们选择了我们认为做的最好的一家公司,也就是 OpenAI 的 ChatGPT。当你需要将问题交给 ChatGPT 处理时,设备会要求获得你的许可,所以在没有收到用户同意的情况下,不会有任何数据发送到 OpenAI。这是你自己决定的,对吧?
You decide,你来决定。苹果用了这样的话术,把责任定义给了 OpenAI 和苹果用户,而苹果手机上还能让用户免费使用 ChatGPT 的功能,对于现阶段的大模型现状来说,这不失为一个两全其美的这种选择,又能让用户享受端侧模型和云端模型做不到的 AI 能力,又不需要把自己尚不成熟的 LLM 推出来被人诟病。
再提一句,苹果和 OpenAI 的这项合作,苹果在条款上是非常占优的。根据 Bloomberg 的消息,苹果不会向 OpenAI 直接支付费用或现金,而是通过苹果的分销系统推广 OpenAI 的品牌和技术。苹果认为,将 OpenAI 的品牌和技术推广到数亿台苹果设备上,其价值相当于、甚至大于金钱支付。
而对于 OpenAI 来说,ChatGPT 免费让上亿苹果用户使用,这将大大增加 OpenAI 的算力成本,虽然 OpenAI 可以让 ChatGPT 的免费用户升级成为付费账户来实现收入,但毫无疑问,这样一个合作协议,对 OpenAI 来说是有压力的,但是对苹果来说,基本没有任何风险。
只能说,苹果还是苹果。Tim Cook 这一招,在策略上,还是非常稳的。
Tim Cook
生成式人工智能一直在我们的考虑范围内,我们会希望用更成熟、全面的技术,所以我们一定要确保实现方式不会出现问题。
但是呢,苹果的这个 AI 三件套发布之后,并不是没有招来任何批评,其中最有争议的,正是与 OpenAI 的合作,而砸场子的人正是 OpenAI 的黑粉头子,马斯克。
02 马斯克“踢馆”以及 AI 数据安全隐患
在苹果宣布与 OpenAI 的合作之后,马斯克是连发N条推特狂喷苹果的安全隐患。
他说,苹果无法推出自己的人工智能,却能够确保 OpenAI 保护你的安全和隐私,这显然是荒谬的!苹果不知道将你的数据交给 OpenAI 后会发生什么,他们在出卖你。接着,马斯克还表示说,如果苹果公司在操作系统层面整合 OpenAI,那么我的公司将禁止使用苹果设备。这是不可接受的安全违规行为。访客必须在门口检查他们的苹果设备,设备将被存放在法拉第笼中。而马斯克的第四条推特,直接放了这张图片。大家自行感受一下。
马斯克的抨击到底有没有道理呢?抛去马斯克作为 OpenAI 的原创始人转黑粉,以及苹果与 OpenAI 合作没有跟马斯克的 xAI 合作,以及马斯克刚不久前被迫撤回对 OpenAI 和 Sam Atlman 的诉讼等等个人情感原因,和马斯克利益冲突的角色,其实,马斯克的抨击也不是完全没有道理的。我们来详细看看 AI 的安全问题。
我们在上一章说了苹果 AI 三件套:手机端模型,云端模型和第三方的 GPT 模型。端模型因为是本地运行,用户数据就留在手机,iPad 或 Mac 设备上,数据隐私安全是没有问题的,这个很好理解。在苹果的云端模型上,这次发布会中,苹果数次强调将用私有云计算 Private Cloud Compute,来保障苹果用户的隐私安全。
Nathan Wang
前苹果员工、iOS App 开发者
系统会生成一个公钥,并通过公钥把个人数据加密,然后加密过后的数据,然后会被送到云端处理,其间通过 API Gateway,Load balancer(网络平衡负载器),把数据分到不同 server(服务器)上,来进行一系列的运算。
在数据传输过程中,因为你的个人数据是加密的,即使在传输过程中被泄露了,别人拿到的数据也没有办法破解,它其实可以在一定程度上去保护你的数据。当数据到达云端的服务器,也就是苹果的 GPU Farm(GPU 计算中心)进行处理的时候,系统会通过私钥进行数字认证,保证只有在授权的 server(服务器)上,才能解密你的个人数据,比如个人信息、输入的文字等等,然后处理完了之后系统会再次把它加密好,再通过同样的方式传输给到你的手机,你手机通过私钥把这个数据打开,就这样整个系统能够完成端到端的加密。
但任何技术都不是无懈可击的,但它被破解的可能性应该是极小的。所以说从技术角度上,我个人是比较相信苹果在端上部署的模型,以及它在云端部署模型的安全性。
苹果多年来试图打造将用户隐私保护放在首位的企业形象,所以端模型和云端模型在苹果的完全掌控之下,数据安全性是大概率能被用户接受的。但现在的争议点在于,苹果接入了 OpenAI 的 GPT 模型,用户数据将通过苹果手机传送给 OpenAI 的 GPT 模型。那么OpenAI 那边如何保证用户隐私安全,或者 OpenAI 是否会将用户数据作为其它用途,这其实是在苹果的掌控之外。
Nathan Wang
前苹果员工、iOS App 开发者
我的数据如果通过苹果的服务器传输到 OpenAI,通过 OpenAI 的这个 API 来处理的时候,那 OpenAI 是不是有同样安全的架构/端到端加密,我觉得至少他们在公布的时候,没有提到这些内容,所以可能没有这些像苹果做得比较好的加密内容。
那也就是说,当苹果把数据给到 OpenAI,是有可能会产生数据泄露,它应该比在苹果端或者苹果云端数据被泄露可能大。OpenAI 怎么去用这个数据,那就取决于 OpenAI 内部,以及公众是否会相信 OpenAI。我觉得从技术上角度来讲的话,是这样对比的过程。
所以,虽然马斯克贴的图确实有点那啥,但是在苹果的立场,它认为,用户用不用 ChatGPT,数据给不给 OpenAI,是用户的决定,这张图里的椰子,它是知情的,而责任方在 OpenAI,与苹果无关,这是苹果强调的点,在法律上确实无懈可击,但从 AI 数据安全的担忧上,确实不是无懈可击的,就看椰子怎么想了。
同时,我们也跟参会的很多开发者聊了聊,大家对苹果 AI 三件套还是非常兴奋的,而也许,这离我们等待已久的 AI 应用爆发来临的那一天,又近了一步。
03 更完善的开发者生态与 AI 应用爆发
虽然媒体和外界都将主要的注意力放在苹果本次 WWDC 第一天的 keynote 展示中,但参会的开发者们告诉我,之后三天的不同细分会议,对于开发者们才是重中之重,第一天的 keynote 只是一个广告而已。
在当地时间的 6 月 11 日到 14 日,苹果负责开发者社区的工作人员们,会召开大大小小的技术指导会议,针对每个开发者生态都会单开一个专题,手把手和开发者们交流和启发大家在应用上的开发,同时在全球也会有大量开发者在线加入全球开发者队伍,参与为期一周的技术和创意活动。而开发者们认为,Apple Intellegence 会带来大量的新 app 机会。
Queena Qiu
Polyverse 创始人兼 CGO
对于开发者来是件非常好的事情。我们也是一直期待,无论是苹果还是其他硬件公司,在端模型上有一些重大突破,第一是云成本,无论是模型训练还是调优、算法,在云成本上的投入是非常大的,是 GenAI 时代开发应用额外的成本支出,端模型的推出,我觉得在节约成本方面会是非常大的提升,也会给我们更大的空间去开发、或做一些更深、更重的应用。特别是视频方向,如果能在设备端去跑,那整个效果跟输出,会有一个质的提升。
Queena 是 Polyverse 的创始人,他们旗下的产品 Mirror AI 在 2023 年 3 月正式上线后,曾连续数月霸榜 Google Play 美区摄影榜,下载量累积超过千万。
Queena 告诉我,虽然苹果展示出各种在图像上的 AI 功能,这可能和一些图生图或者文生图的 AI 初创公司有产品的相似性,但苹果这样的大公司不会在垂类上过多深入,这其实会启发开发者以及 AI 创业公司们,在更垂直的赛道去开发更多样性的产品和应用。
Queena Qiu
Polyverse 创始人兼 CGO
我觉得往往 Apple 在这方面不会做得特别深,更多的是开放一个入口,给开发者进行尝试。在这个过程当中,对于开发者来说,就是如何去运用发布的这些特点、开源的技术来去进一步的做拓展。比如说,基于会议纪要还有非常多的场景,比如线下活动、线上活动,你还是可以去做很多丰富场景的事情。那在这个基础上就会衍生出非常多有趣的应用了,那我们也是希望基于 Apple,基于互联网巨头的发展,去做一些站在巨人肩膀上的事。
而 Nathan 作为一个开发者,他告诉我,他在深度研究了苹果之后几天的开发者大会之后,认为苹果的野心绝不止 keynote demo(PPT 展示)中展示出来的这些功能,这后面显示出的一个潜在事实是:虽然苹果是这轮硅谷科技巨头中最晚加入 AI 战局的,但可能,苹果才是这轮生成式 AI 的最大受益者之一。
Nathan Wang
前苹果员工、iOS App 开发者
我其实后面是花了一些时间,看它背后整个开发者生态所针对的每一个专题,我很大的一个兴奋点,就是我感觉 Apple 要一统天下。
之所以说它一统天下的一个原因,就是大家可以看到就 Apple 其实它掌控了硬件和软件,很少有企业既可以控制硬件又可以控制软件的,谷歌虽然有自己 Android 手机,但是它在整个硬件设计上其实并没有特别多的能力。反观是 Apple,你看它有自己的芯片,从 M1、 M2、 M3 到 M4,它是有一系列硬件开发的能力,然后它的手机是全球最流行的平台,所有人都在去使用,它背后又有个非常强大的开发者生态。
我会发现苹果越来越多的是,把各方面资源整合起来,就这为什么说苹果一统天下,就是如果你看了后面的这些开发者这些视频,你会发现从一开始,比如说做 APP 要做这个前端,给大家这个 UI/UX 的体验,已经是传统的这个 APP 可以去达到的。那背后针对于 AI 这一块, Apple 其实是让你可以用自己的数据,在它的 GPU 上训练你的模型,然后再把这个模型部到你的 APP 当中去使用。它其实从前端到后端到这个大模型的整个开发和 inference(推理)它基本上全包了。
也就是说你只要在生活在 Apple 的这个开发者生态的话,你就基本上不用出去了,它可以它整个 Apple 的这个生态就可以帮你做所有的事情。所以说你看市面上外面那些,比如说 hugging face 也好, ChatGPT 也好,或者是各家公司在训自己模型,那其实是简单来讲的话,所有东西都会被容纳到 Apple 的整个的这个生态当中去,然后只要你是在 Apple 生态的这个开发者,你就可以用到 Apple 所有的这个资源。
所以讲到这里,大家可能会理解为什么在 WWDC 当天苹果股价略有下跌,但第二天有如此大的涨幅,之后几天还继续连涨。
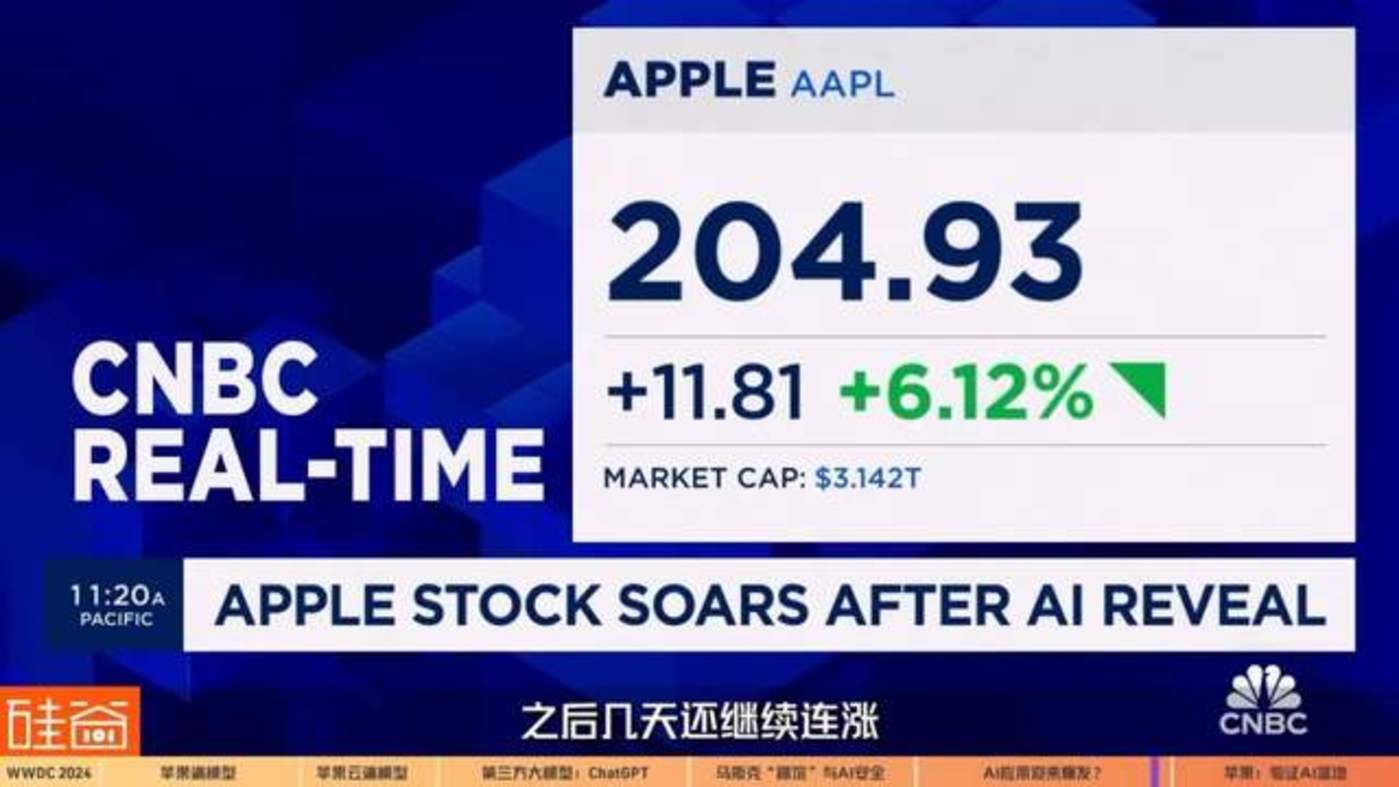
是因为华尔街机构和投资人们,在后几天的开发者大会中整体得到的信息是,苹果不但因为 AI 功能的推出而将换机周期提前、提振手机和设备销量之外,人们意识到,此前让市场担心的这轮生成式 AI 的最终商业落地难题,是最先在苹果这里得到验证的,而这将让苹果成为后来者居上的最终赢家,让苹果的生态更加强大更加难被颠覆。
04 更难被颠覆的苹果:验证 AI 落地的出头鸟
莫傑麟
互联网家族办公室首席投资官
WhatIf Research 主理人
对于苹果这种公司来讲,它的对于技术的判断标准只有一个:这个技术目前能不能做出来消费者愿意使用的产品。统计去年市场,不管是一级还是二级市场,公司做出来的 AI 产品,真正有用户留存的产品并不是很多,可能两只手都能数得过来。
所以公平来讲的,苹果可能事实上确实存在我们讲的老公司、以产品文化导向的公司对技术不够激进的特点,但它在自己的范围之内,它对于产品的判断标准上来讲,我们觉得还是在合理的范围内。就是说到今年它认为 AI 技术发展得非常迅速,已经到了这个东西做出来一些消费者愿意使用的产品,并且对于消费者的体验上是关键的这些东西。
苹果的 AI 功能将在今年下半年对消费者们开放,我相信,很多 AI 应用开发者们也已经开始摩拳擦掌,想乘着苹果 AI 的这股东风,试图做出新的一轮爆款 killer app(杀手级应用)出来。所以随着苹果端模型和云端模型,以及 OpenAI 还有谷歌等一系列大模型的能力提升,接下来的几个月到一年时间,我们可能会看到更多与消费者更近的 AI 应用出现。
莫傑麟
互联网家族办公室首席投资官
WhatIf Research 主理人
它最终的商业模式,或者它的胜负手,其实还是来自于它掌握了硬件的生态。我们很难想象一个设备的场景是苹果没有做过的。我们随身出门携带的手机、耳机、手表,最多加上一个电脑,Vision Pro 我相信是带不出去的,我们真正所有能够穿戴的设备其实苹果已经包全了,所以在这条线上面,我觉得是苹果以消费者导向为文化的目标是一以贯之的。
我经常被一些在硅谷之外的问到:AI 难道不是泡沫吗?如果不是,为什么我身边完全感受不到它正在改变我的生活呢?这是因为,在硅谷,从 ChatGPT 爆火以来,大部分资金和创业项目还在基础模型能力提升,整体的 infra(基础设施)基建,以及 ToB 企业级应用上,到消费者端的应用要不就是效果还不够好,要不然就是只能火一阵,难以保持用户留存率。
而 AI 能力如今慢慢渗透到了与我们普通消费者接触最多的消费者电子产品上,手机,Airpods,电脑,苹果手表,Vision Pro 等等,甚至之后可能会推出的智能家居,它能让用户们感受到 AI 真的已经来临吗?或许在这一轮生成式 AI 的浪潮中,苹果才是第一梯队要去冲锋陷阵、验证技术能否落地的出头鸟。但如果验证成功了,对于苹果来说,它将更加难以颠覆。
莫傑麟
互联网家族办公室首席投资官/WhatIf Research 主理人
我们在背后看到,不管是抢人、抢资源、抢卡各个方面,其实最终都是为了去把技术,更好地巩固到用户生态里面去,让我对用户的价值、对市场份额的抢占会更明显。这个主线目前我们是没有看到突破痕迹的,当然会有很多公司在这个状态里,能做出一些非常好的产品,或者是一些补位出来,但从数量和整个趋势上来讲,其实跟上一个周期真正 technology disruption (技术突破)的年代其实还是有本质的区别。
当然东西可能我们会随时被打脸,比如说基于现在也有人会说整个 LLM(大模型)上会构建一套新的 iOS 出来,会长出非常多新的应用出来。那我觉得这个东西就需要看这个是不是一个完全新的这么一个用户的需求会衍生出来,如果没有的话,我们整体对目前的判断还是处于 technology consolidate(技术巩固),那只要是 consolidate(巩固),那从比例上的概率上来讲,大公司 consolidate technology(加固技术)的这个能力确实是要更强一些。
OpenAI 的目标是 AGI 的能力,谷歌的目标是自家产品的商业化,微软的目标是企业化产品,英伟达的目标是这一些技术突破的底层算力,而苹果,以及与苹果一样的手机制造商们的目标是与你我最相关的,这就是,AI 能否进入到我们的生活,改变我们的生活,成为我们生活的一部分。这个答案还不是确定的,还需要验证。
而验证的人,正是屏幕前的你。这个答案,或许我们很快就能知道了。






